 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Salami Slicing Threat: Exploiting Cumulative Risks in LLM Systems
Apr 13, 2026Large Language Models (LLMs) face prominent security risks from jailbreaking, a practice that manipulates models to bypass built-in security constraints and generate unethical or unsafe content. Among various jailbreak techniques, multi-turn jailbreak attacks are more covert and persistent than single-turn counterparts, exposing critical vulnerabilities of LLMs. However, existing multi-turn jailbreak methods suffer from two fundamental limitations that affect the actual impact in real-world scenarios: (a) As models become more context-aware, any explicit harmful trigger is increasingly likely to be flagged and blocked; (b) Successful final-step triggers often require finely tuned, model-specific contexts, making such attacks highly context-dependent. To fill this gap, we propose \textit{Salami Slicing Risk}, which operates by chaining numerous low-risk inputs that individually evade alignment thresholds but cumulatively accumulate harmful intent to ultimately trigger high-risk behaviors, without heavy reliance on pre-designed contextual structures. Building on this risk, we develop Salami Attack, an automatic framework universally applicable to multiple model types and modalities. Rigorous experiments demonstrate its state-of-the-art performance across diverse models and modalities, achieving over 90\% Attack Success Rate on GPT-4o and Gemini, as well as robustness against real-world alignment defenses. We also proposed a defense strategy to constrain the Salami Attack by at least 44.8\% while achieving a maximum blocking rate of 64.8\% against other multi-turn jailbreak attacks. Our findings provide critical insights into the pervasive risks of multi-turn jailbreaking and offer actionable mitigation strategies to enhance LLM security.
Degradation-Robust Fusion: An Efficient Degradation-Aware Diffusion Framework for Multimodal Image Fusion in Arbitrary Degradation Scenarios
Apr 10, 2026Complex degradations like noise, blur, and low resolution are typical challenges in real world image fusion tasks, limiting the performance and practicality of existing methods. End to end neural network based approaches are generally simple to design and highly efficient in inference, but their black-box nature leads to limited interpretability. Diffusion based methods alleviate this to some extent by providing powerful generative priors and a more structured inference process. However, they are trained to learn a single domain target distribution, whereas fusion lacks natural fused data and relies on modeling complementary information from multiple sources, making diffusion hard to apply directly in practice. To address these challenges, this paper proposes an efficient degradation aware diffusion framework for image fusion under arbitrary degradation scenarios. Specifically, instead of explicitly predicting noise as in conventional diffusion models, our method performs implicit denoising by directly regressing the fused image, enabling flexible adaptation to diverse fusion tasks under complex degradations with limited steps. Moreover, we design a joint observation model correction mechanism that simultaneously imposes degradation and fusion constraints during sampling to ensure high reconstruction accuracy. Experiments on diverse fusion tasks and degradation configurations demonstrate the superiority of the proposed method under complex degradation scenarios.
Improving Safety Alignment via Balanced Direct Preference Optimization
Mar 24, 2026With the rapid development and widespread application of Large Language Models (LLMs), their potential safety risks have attracted widespread attention. Reinforcement Learning from Human Feedback (RLHF) has been adopted to enhance the safety performance of LLMs. As a simple and effective alternative to RLHF, Direct Preference Optimization (DPO) is widely used for safety alignment. However, safety alignment still suffers from severe overfitting, which limits its actual performance. This paper revisits the overfitting phenomenon from the perspective of the model's comprehension of the training data. We find that the Imbalanced Preference Comprehension phenomenon exists between responses in preference pairs, which compromises the model's safety performance. To address this, we propose Balanced Direct Preference Optimization (B-DPO), which adaptively modulates optimization strength between preferred and dispreferred responses based on mutual information. A series of experimental results show that B-DPO can enhance the safety capability while maintaining the competitive general capabilities of LLMs on various mainstream benchmarks compared to state-of-the-art methods. \color{red}{Warning: This paper contains examples of harmful texts, and reader discretion is recommended.
Reloc-VGGT: Visual Re-localization with Geometry Grounded Transformer
Dec 26, 2025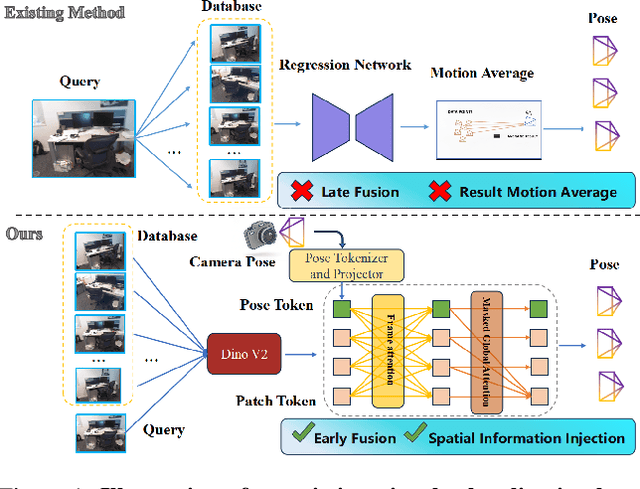
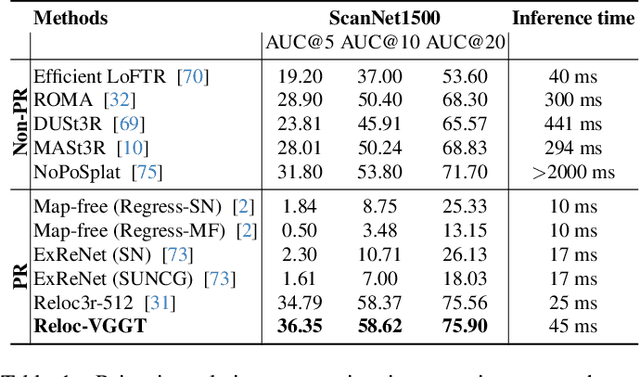
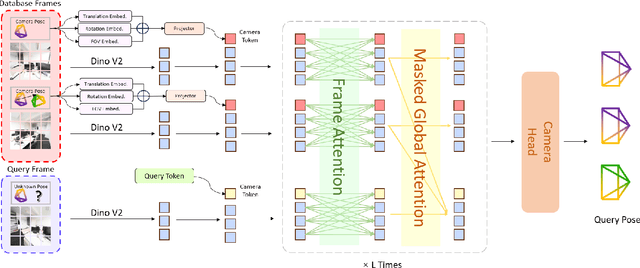
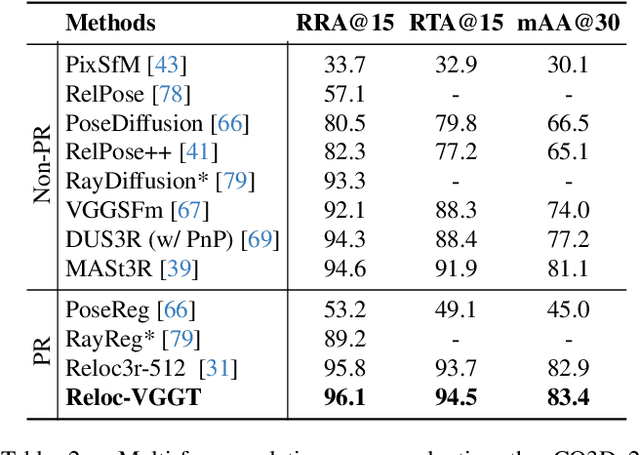
Visual localization has traditionally been formulated as a pair-wise pose regression problem. Existing approaches mainly estimate relative poses between two images and employ a late-fusion strategy to obtain absolute pose estimates. However, the late motion average is often insufficient for effectively integrating spatial information, and its accuracy degrades in complex environments. In this paper, we present the first visual localization framework that performs multi-view spatial integration through an early-fusion mechanism, enabling robust operation in both structured and unstructured environments. Our framework is built upon the VGGT backbone, which encodes multi-view 3D geometry, and we introduce a pose tokenizer and projection module to more effectively exploit spatial relationships from multiple database views. Furthermore, we propose a novel sparse mask attention strategy that reduces computational cost by avoiding the quadratic complexity of global attention, thereby enabling real-time performance at scale. Trained on approximately eight million posed image pairs, Reloc-VGGT demonstrates strong accuracy and remarkable generalization ability. Extensive experiments across diverse public datasets consistently validate the effectiveness and efficiency of our approach, delivering high-quality camera pose estimates in real time while maintaining robustness to unseen environments. Our code and models will be publicly released upon acceptance.https://github.com/dtc111111/Reloc-VGGT.
UniPR-3D: Towards Universal Visual Place Recognition with Visual Geometry Grounded Transformer
Dec 24, 2025Visual Place Recognition (VPR) has been traditionally formulated as a single-image retrieval task. Using multiple views offers clear advantages, yet this setting remains relatively underexplored and existing methods often struggle to generalize across diverse environments. In this work we introduce UniPR-3D, the first VPR architecture that effectively integrates information from multiple views. UniPR-3D builds on a VGGT backbone capable of encoding multi-view 3D representations, which we adapt by designing feature aggregators and fine-tune for the place recognition task. To construct our descriptor, we jointly leverage the 3D tokens and intermediate 2D tokens produced by VGGT. Based on their distinct characteristics, we design dedicated aggregation modules for 2D and 3D features, allowing our descriptor to capture fine-grained texture cues while also reasoning across viewpoints. To further enhance generalization, we incorporate both single- and multi-frame aggregation schemes, along with a variable-length sequence retrieval strategy. Our experiments show that UniPR-3D sets a new state of the art, outperforming both single- and multi-view baselines and highlighting the effectiveness of geometry-grounded tokens for VPR. Our code and models will be made publicly available on Github https://github.com/dtc111111/UniPR-3D.
EchoMark: Perceptual Acoustic Environment Transfer with Watermark-Embedded Room Impulse Response
Nov 09, 2025Acoustic Environment Matching (AEM) is the task of transferring clean audio into a target acoustic environment, enabling engaging applications such as audio dubbing and auditory immersive virtual reality (VR). Recovering similar room impulse response (RIR) directly from reverberant speech offers more accessible and flexible AEM solution. However, this capability also introduces vulnerabilities of arbitrary ``relocation" if misused by malicious user, such as facilitating advanced voice spoofing attacks or undermining the authenticity of recorded evidence. To address this issue, we propose EchoMark, the first deep learning-based AEM framework that generates perceptually similar RIRs with embedded watermark. Our design tackle the challenges posed by variable RIR characteristics, such as different durations and energy decays, by operating in the latent domain. By jointly optimizing the model with a perceptual loss for RIR reconstruction and a loss for watermark detection, EchoMark achieves both high-quality environment transfer and reliable watermark recovery. Experiments on diverse datasets validate that EchoMark achieves room acoustic parameter matching performance comparable to FiNS, the state-of-the-art RIR estimator. Furthermore, a high Mean Opinion Score (MOS) of 4.22 out of 5, watermark detection accuracy exceeding 99\%, and bit error rates (BER) below 0.3\% collectively demonstrate the effectiveness of EchoMark in preserving perceptual quality while ensuring reliable watermark embedding.
Explore Data Left Behind in Reinforcement Learning for Reasoning Language Models
Nov 06, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an effective approach for improving the reasoning abilities of large language models (LLMs). The Group Relative Policy Optimization (GRPO) family has demonstrated strong performance in training LLMs with RLVR. However, as models train longer and scale larger, more training prompts become residual prompts, those with zero variance rewards that provide no training signal. Consequently, fewer prompts contribute to training, reducing diversity and hindering effectiveness. To fully exploit these residual prompts, we propose the Explore Residual Prompts in Policy Optimization (ERPO) framework, which encourages exploration on residual prompts and reactivates their training signals. ERPO maintains a history tracker for each prompt and adaptively increases the sampling temperature for residual prompts that previously produced all correct responses. This encourages the model to generate more diverse reasoning traces, introducing incorrect responses that revive training signals. Empirical results on the Qwen2.5 series demonstrate that ERPO consistently surpasses strong baselines across multiple mathematical reasoning benchmarks.
UniLGL: Learning Uniform Place Recognition for FOV-limited/Panoramic LiDAR Global Localization
Jul 16, 2025Existing LGL methods typically consider only partial information (e.g., geometric features) from LiDAR observations or are designed for homogeneous LiDAR sensors, overlooking the uniformity in LGL. In this work, a uniform LGL method is proposed, termed UniLGL, which simultaneously achieves spatial and material uniformity, as well as sensor-type uniformity. The key idea of the proposed method is to encode the complete point cloud, which contains both geometric and material information, into a pair of BEV images (i.e., a spatial BEV image and an intensity BEV image). An end-to-end multi-BEV fusion network is designed to extract uniform features, equipping UniLGL with spatial and material uniformity. To ensure robust LGL across heterogeneous LiDAR sensors, a viewpoint invariance hypothesis is introduced, which replaces the conventional translation equivariance assumption commonly used in existing LPR networks and supervises UniLGL to achieve sensor-type uniformity in both global descriptors and local feature representations. Finally, based on the mapping between local features on the 2D BEV image and the point cloud, a robust global pose estimator is derived that determines the global minimum of the global pose on SE(3) without requiring additional registration. To validate the effectiveness of the proposed uniform LGL, extensive benchmarks are conducted in real-world environments, and the results show that the proposed UniLGL is demonstratively competitive compared to other State-of-the-Art LGL methods. Furthermore, UniLGL has been deployed on diverse platforms, including full-size trucks and agile Micro Aerial Vehicles (MAVs), to enable high-precision localization and mapping as well as multi-MAV collaborative exploration in port and forest environments, demonstrating the applicability of UniLGL in industrial and field scenarios.
SpeechVerifier: Robust Acoustic Fingerprint against Tampering Attacks via Watermarking
May 28, 2025With the surge of social media, maliciously tampered public speeches, especially those from influential figures, have seriously affected social stability and public trust. Existing speech tampering detection methods remain insufficient: they either rely on external reference data or fail to be both sensitive to attacks and robust to benign operations, such as compression and resampling. To tackle these challenges, we introduce SpeechVerifer to proactively verify speech integrity using only the published speech itself, i.e., without requiring any external references. Inspired by audio fingerprinting and watermarking, SpeechVerifier can (i) effectively detect tampering attacks, (ii) be robust to benign operations and (iii) verify the integrity only based on published speeches. Briefly, SpeechVerifier utilizes multiscale feature extraction to capture speech features across different temporal resolutions. Then, it employs contrastive learning to generate fingerprints that can detect modifications at varying granularities. These fingerprints are designed to be robust to benign operations, but exhibit significant changes when malicious tampering occurs. To enable speech verification in a self-contained manner, the generated fingerprints are then embedded into the speech signal by segment-wise watermarking. Without external references, SpeechVerifier can retrieve the fingerprint from the published audio and check it with the embedded watermark to verify the integrity of the speech. Extensive experimental results demonstrate that the proposed SpeechVerifier is effective in detecting tampering attacks and robust to benign operations.
MobiVital: Self-supervised Time-series Quality Estimation for Contactless Respiration Monitoring Using UWB Radar
Mar 14, 2025Respiration waveforms are increasingly recognized as important biomarkers, offering insights beyond simple respiration rates, such as detecting breathing irregularities for disease diagnosis or monitoring breath patterns to guide rehabilitation training. Previous works in wireless respiration monitoring have primarily focused on estimating respiration rate, where the breath waveforms are often generated as a by-product. As a result, issues such as waveform deformation and inversion have largely been overlooked, reducing the signal's utility for applications requiring breathing waveforms. To address this problem, we present a novel approach, MobiVital, that improves the quality of respiration waveforms obtained from ultra-wideband (UWB) radar data. MobiVital combines a self-supervised autoregressive model for breathing waveform extraction with a biology-informed algorithm to detect and correct waveform inversions. To encourage reproducible research efforts for developing wireless vital signal monitoring systems, we also release a 12-person, 24-hour UWB radar vital signal dataset, with time-synchronized ground truth obtained from wearable sensors. Our results show that the respiration waveforms produced by our system exhibit a 7-34% increase in fidelity to the ground truth compared to the baselines and can benefit downstream tasks such as respiration rate estimation.