 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobPI: Robust Private Inference against Malicious Client
Feb 23, 2026The increased deployment of machine learning inference in various applications has sparked privacy concerns. In response, private inference (PI) protocols have been created to allow parties to perform inference without revealing their sensitive data. Despite recent advances in the efficiency of PI, most current methods assume a semi-honest threat model where the data owner is honest and adheres to the protocol. However, in reality, data owners can have different motivations and act in unpredictable ways, making this assumption unrealistic. To demonstrate how a malicious client can compromise the semi-honest model, we first designed an inference manipulation attack against a range of state-of-the-art private inference protocols. This attack allows a malicious client to modify the model output with 3x to 8x fewer queries than current black-box attacks. Motivated by the attacks, we proposed and implemented RobPI, a robust and resilient private inference protocol that withstands malicious clients. RobPI integrates a distinctive cryptographic protocol that bolsters security by weaving encryption-compatible noise into the logits and features of private inference, thereby efficiently warding off malicious-client attacks. Our extensive experiments on various neural networks and datasets show that RobPI achieves ~91.9% attack success rate reduction and increases more than 10x the number of queries required by malicious-client attacks.
RPP: A Certified Poisoned-Sample Detection Framework for Backdoor Attacks under Dataset Imbalance
Jan 30, 2026Deep neural networks are highly susceptible to backdoor attacks, yet most defense methods to date rely on balanced data, overlooking the pervasive class imbalance in real-world scenarios that can amplify backdoor threats. This paper presents the first in-depth investigation of how the dataset imbalance amplifies backdoor vulnerability, showing that (i) the imbalance induces a majority-class bias that increases susceptibility and (ii) conventional defenses degrade significantly as the imbalance grows. To address this, we propose Randomized Probability Perturbation (RPP), a certified poisoned-sample detection framework that operates in a black-box setting using only model output probabilities. For any inspected sample, RPP determines whether the input has been backdoor-manipulated, while offering provable within-domain detectability guarantees and a probabilistic upper bound on the false positive rate. Extensive experiments on five benchmarks (MNIST, SVHN, CIFAR-10, TinyImageNet and ImageNet10) covering 10 backdoor attacks and 12 baseline defenses show that RPP achieves significantly higher detection accuracy than state-of-the-art defenses, particularly under dataset imbalance. RPP establishes a theoretical and practical foundation for defending against backdoor attacks in real-world environments with imbalanced data.
Learning Latency-Aware Orchestration for Parallel Multi-Agent Systems
Jan 15, 2026Multi-agent systems (MAS) enable complex reasoning by coordinating multiple agents, but often incur high inference latency due to multi-step execution and repeated model invocations, severely limiting their scalability and usability in time-sensitive scenarios. Most existing approaches primarily optimize task performance and inference cost, and explicitly or implicitly assume sequential execution, making them less optimal for controlling latency under parallel execution. In this work, we investigate learning-based orchestration of multi-agent systems with explicit latency supervision under parallel execution. We propose Latency-Aware Multi-agent System (LAMaS), a latency-aware multi-agent orchestration framework that enables parallel execution and explicitly optimizes the critical execution path, allowing the controller to construct execution topology graphs with lower latency under parallel execution. Our experiments show that our approach reduces critical path length by 38-46% compared to the state-of-the-art baseline for multi-agent architecture search across multiple benchmarks, while maintaining or even improving task performance. These results highlight the importance of explicitly optimizing latency under parallel execution when designing efficient multi-agent systems. The code is available at https://github.com/xishi404/LAMaS
Factuality Beyond Coherence: Evaluating LLM Watermarking Methods for Medical Texts
Sep 09, 2025As large language models (LLMs) adapted to sensitive domains such as medicine, their fluency raises safety risks, particularly regarding provenance and accountability. Watermarking embeds detectable patterns to mitigate these risks, yet its reliability in medical contexts remains untested. Existing benchmarks focus on detection-quality tradeoffs, overlooking factual risks under low-entropy settings often exploited by watermarking's reweighting strategy. We propose a medical-focused evaluation workflow that jointly assesses factual accuracy and coherence. Using GPT-Judger and further human validation, we introduce the Factuality-Weighted Score (FWS), a composite metric prioritizing factual accuracy beyond coherence to guide watermarking deployment in medical domains. Our evaluation shows current watermarking methods substantially compromise medical factuality, with entropy shifts degrading medical entity representation. These findings underscore the need for domain-aware watermarking approaches that preserve the integrity of medical content.
TFHE-Coder: Evaluating LLM-agentic Fully Homomorphic Encryption Code Generation
Mar 15, 2025



Fully Homomorphic Encryption over the torus (TFHE) enables computation on encrypted data without decryption, making it a cornerstone of secure and confidential computing. Despite its potential in privacy preserving machine learning, secure multi party computation, private blockchain transactions, and secure medical diagnostics, its adoption remains limited due to cryptographic complexity and usability challenges. While various TFHE libraries and compilers exist, practical code generation remains a hurdle. We propose a compiler integrated framework to evaluate LLM inference and agentic optimization for TFHE code generation, focusing on logic gates and ReLU activation. Our methodology assesses error rates, compilability, and structural similarity across open and closedsource LLMs. Results highlight significant limitations in off-the-shelf models, while agentic optimizations such as retrieval augmented generation (RAG) and few-shot prompting reduce errors and enhance code fidelity. This work establishes the first benchmark for TFHE code generation, demonstrating how LLMs, when augmented with domain-specific feedback, can bridge the expertise gap in FHE code generation.
CipherPrune: Efficient and Scalable Private Transformer Inference
Feb 24, 2025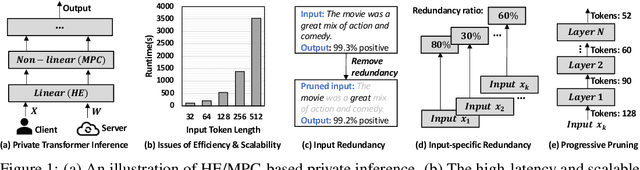
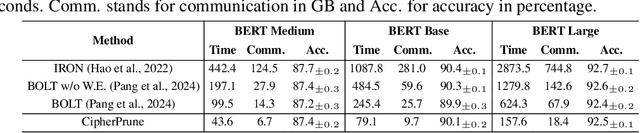
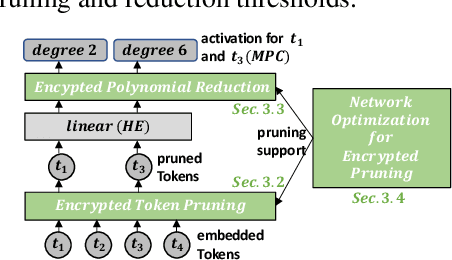
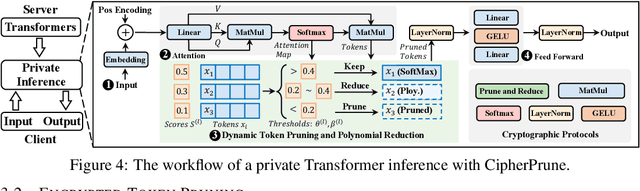
Private Transformer inference using cryptographic protocols offers promising solutions for privacy-preserving machine learning; however, it still faces significant runtime overhead (efficiency issues) and challenges in handling long-token inputs (scalability issues). We observe that the Transformer's operational complexity scales quadratically with the number of input tokens, making it essential to reduce the input token length. Notably, each token varies in importance, and many inputs contain redundant tokens. Additionally, prior private inference methods that rely on high-degree polynomial approximations for non-linear activations are computationally expensive. Therefore, reducing the polynomial degree for less important tokens can significantly accelerate private inference. Building on these observations, we propose \textit{CipherPrune}, an efficient and scalable private inference framework that includes a secure encrypted token pruning protocol, a polynomial reduction protocol, and corresponding Transformer network optimizations. At the protocol level, encrypted token pruning adaptively removes unimportant tokens from encrypted inputs in a progressive, layer-wise manner. Additionally, encrypted polynomial reduction assigns lower-degree polynomials to less important tokens after pruning, enhancing efficiency without decryption. At the network level, we introduce protocol-aware network optimization via a gradient-based search to maximize pruning thresholds and polynomial reduction conditions while maintaining the desired accuracy. Our experiments demonstrate that CipherPrune reduces the execution overhead of private Transformer inference by approximately $6.1\times$ for 128-token inputs and $10.6\times$ for 512-token inputs, compared to previous methods, with only a marginal drop in accuracy. The code is publicly available at https://github.com/UCF-Lou-Lab-PET/cipher-prune-inference.
Uncovering the Hidden Threat of Text Watermarking from Users with Cross-Lingual Knowledge
Feb 23, 2025



In this study, we delve into the hidden threats posed to text watermarking by users with cross-lingual knowledge. While most research focuses on watermarking methods for English, there is a significant gap in evaluating these methods in cross-lingual contexts. This oversight neglects critical adversary scenarios involving cross-lingual users, creating uncertainty regarding the effectiveness of cross-lingual watermarking. We assess four watermarking techniques across four linguistically rich languages, examining watermark resilience and text quality across various parameters and attacks. Our focus is on a realistic scenario featuring adversaries with cross-lingual expertise, evaluating the adequacy of current watermarking methods against such challenges.
BadFair: Backdoored Fairness Attacks with Group-conditioned Triggers
Oct 23, 2024Attacking fairness is crucial because compromised models can introduce biased outcomes, undermining trust and amplifying inequalities in sensitive applications like hiring, healthcare, and law enforcement. This highlights the urgent need to understand how fairness mechanisms can be exploited and to develop defenses that ensure both fairness and robustness. We introduce BadFair, a novel backdoored fairness attack methodology. BadFair stealthily crafts a model that operates with accuracy and fairness under regular conditions but, when activated by certain triggers, discriminates and produces incorrect results for specific groups. This type of attack is particularly stealthy and dangerous, as it circumvents existing fairness detection methods, maintaining an appearance of fairness in normal use. Our findings reveal that BadFair achieves a more than 85% attack success rate in attacks aimed at target groups on average while only incurring a minimal accuracy loss. Moreover, it consistently exhibits a significant discrimination score, distinguishing between pre-defined target and non-target attacked groups across various datasets and models.
Jailbreaking LLMs with Arabic Transliteration and Arabizi
Jun 26, 2024This study identifies the potential vulnerabilities of Large Language Models (LLMs) to 'jailbreak' attacks, specifically focusing on the Arabic language and its various forms. While most research has concentrated on English-based prompt manipulation, our investigation broadens the scope to investigate the Arabic language. We initially tested the AdvBench benchmark in Standardized Arabic, finding that even with prompt manipulation techniques like prefix injection, it was insufficient to provoke LLMs into generating unsafe content. However, when using Arabic transliteration and chatspeak (or arabizi), we found that unsafe content could be produced on platforms like OpenAI GPT-4 and Anthropic Claude 3 Sonnet. Our findings suggest that using Arabic and its various forms could expose information that might remain hidden, potentially increasing the risk of jailbreak attacks. We hypothesize that this exposure could be due to the model's learned connection to specific words, highlighting the need for more comprehensive safety training across all language forms.
CR-UTP: Certified Robustness against Universal Text Perturbations
Jun 04, 2024



It is imperative to ensure the stability of every prediction made by a language model; that is, a language's prediction should remain consistent despite minor input variations, like word substitutions. In this paper, we investigate the problem of certifying a language model's robustness against Universal Text Perturbations (UTPs), which have been widely used in universal adversarial attacks and backdoor attacks. Existing certified robustness based on random smoothing has shown considerable promise in certifying the input-specific text perturbations (ISTPs), operating under the assumption that any random alteration of a sample's clean or adversarial words would negate the impact of sample-wise perturbations. However, with UTPs, masking only the adversarial words can eliminate the attack. A naive method is to simply increase the masking ratio and the likelihood of masking attack tokens, but it leads to a significant reduction in both certified accuracy and the certified radius due to input corruption by extensive masking. To solve this challenge, we introduce a novel approach, the superior prompt search method, designed to identify a superior prompt that maintains higher certified accuracy under extensive masking. Additionally, we theoretically motivate why ensembles are a particularly suitable choice as base prompts for random smoothing. The method is denoted by superior prompt ensembling technique. We also empirically confirm this technique, obtaining state-of-the-art results in multiple settings. These methodologies, for the first time, enable high certified accuracy against both UTPs and ISTPs. The source code of CR-UTP is available at https://github.com/UCFML-Research/CR-UTP.