 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFall Risk and Gait Analysis in Community-Dwelling Older Adults using World-Spaced 3D Human Mesh Recovery
Apr 13, 2026Gait assessment is a key clinical indicator of fall risk and overall health in older adults. However, standard clinical practice is largely limited to stopwatch-measured gait speed. We present a pipeline that leverages a 3D Human Mesh Recovery (HMR) model to extract gait parameters from recordings of older adults completing the Timed Up and Go (TUG) test. From videos recorded across different community centers, we extract and analyze spatiotemporal gait parameters, including step time, sit-to-stand duration, and step length. We found that video-derived step time was significantly correlated with IMU-based insole measurements. Using linear mixed effects models, we confirmed that shorter, more variable step lengths and longer sit-to-stand durations were predicted by higher self-rated fall risk and fear of falling. These findings demonstrate that our pipeline can enable accessible and ecologically valid gait analysis in community settings.
CirrusBench: Evaluating LLM-based Agents Beyond Correctness in Real-World Cloud Service Environments
Mar 30, 2026The increasing agentic capabilities of Large Language Models (LLMs) have enabled their deployment in real-world applications, such as cloud services, where customer-assistant interactions exhibit high technical complexity and long-horizon dependencies, making robustness and resolution efficiency critical for customer satisfaction. However, existing benchmarks for LLM-based agents largely rely on synthetic environments that fail to capture the diversity and unpredictability of authentic customer inputs, often ignoring the resolution efficiency essential for real-world deployment. To bridge this gap, we introduce CirrusBench, a novel evaluation framework distinguished by its foundation in real-world data from authentic cloud service tickets. CirrusBench preserves the intricate multi-turn logical chains and realistic tool dependencies inherent to technical service environments. Moving beyond execution correctness, we introduce novel Customer-Centric metrics to define agent success, quantifying service quality through metrics such as the Normalized Efficiency Index and Multi-Turn Latency to explicitly measure resolution efficiency. Experiments utilizing our framework reveal that while state-of-the-art models demonstrate strong reasoning capabilities, they frequently struggle in complex, realistic multi-turn tasks and fail to meet the high-efficiency standards required for customer service, highlighting critical directions for the future development of LLM-based agents in practical technical service applications. CirrusBench evaluation framework is released at: https://github.com/CirrusAI
GUIDE: Resolving Domain Bias in GUI Agents through Real-Time Web Video Retrieval and Plug-and-Play Annotation
Mar 27, 2026Large vision-language models have endowed GUI agents with strong general capabilities for interface understanding and interaction. However, due to insufficient exposure to domain-specific software operation data during training, these agents exhibit significant domain bias - they lack familiarity with the specific operation workflows (planning) and UI element layouts (grounding) of particular applications, limiting their real-world task performance. In this paper, we present GUIDE (GUI Unbiasing via Instructional-Video Driven Expertise), a training-free, plug-and-play framework that resolves GUI agent domain bias by autonomously acquiring domain-specific expertise from web tutorial videos through a retrieval-augmented automated annotation pipeline. GUIDE introduces two key innovations. First, a subtitle-driven Video-RAG pipeline unlocks video semantics through subtitle analysis, performing progressive three-stage retrieval - domain classification, topic extraction, and relevance matching - to identify task-relevant tutorial videos. Second, a fully automated annotation pipeline built on an inverse dynamics paradigm feeds consecutive keyframes enhanced with UI element detection into VLMs, inferring the required planning and grounding knowledge that are injected into the agent's corresponding modules to address both manifestations of domain bias. Extensive experiments on OSWorld demonstrate GUIDE's generality as a plug-and-play component for both multi-agent systems and single-model agents. It consistently yields over 5% improvements and reduces execution steps - without modifying any model parameters or architecture - validating GUIDE as an architecture-agnostic enhancement to bridge GUI agent domain bias.
Lightweight Adaptation for LLM-based Technical Service Agent: Latent Logic Augmentation and Robust Noise Reduction
Mar 18, 2026Adapting Large Language Models in complex technical service domains is constrained by the absence of explicit cognitive chains in human demonstrations and the inherent ambiguity arising from the diversity of valid responses. These limitations severely hinder agents from internalizing latent decision dynamics and generalizing effectively. Moreover, practical adaptation is often impeded by the prohibitive resource and time costs associated with standard training paradigms. To overcome these challenges and guarantee computational efficiency, we propose a lightweight adaptation framework comprising three key contributions. (1) Latent Logic Augmentation: We introduce Planning-Aware Trajectory Modeling and Decision Reasoning Augmentation to bridge the gap between surface-level supervision and latent decision logic. These approaches strengthen the stability of Supervised Fine-Tuning alignment. (2) Robust Noise Reduction: We construct a Multiple Ground Truths dataset through a dual-filtering method to reduce the noise by validating diverse responses, thereby capturing the semantic diversity. (3) Lightweight Adaptation: We design a Hybrid Reward mechanism that fuses an LLM-based judge with a lightweight relevance-based Reranker to distill high-fidelity reward signals while reducing the computational cost compared to standard LLM-as-a-Judge reinforcement learning. Empirical evaluations on real-world Cloud service tasks, conducted across semantically diverse settings, demonstrate that our framework achieves stability and performance gains through Latent Logic Augmentation and Robust Noise Reduction. Concurrently, our Hybrid Reward mechanism achieves alignment comparable to standard LLM-as-a-judge methods with reduced training time, underscoring the practical value for deploying technical service agents.
HUMANLLM: Benchmarking and Reinforcing LLM Anthropomorphism via Human Cognitive Patterns
Jan 15, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning and generation, serving as the foundation for advanced persona simulation and Role-Playing Language Agents (RPLAs). However, achieving authentic alignment with human cognitive and behavioral patterns remains a critical challenge for these agents. We present HUMANLLM, a framework treating psychological patterns as interacting causal forces. We construct 244 patterns from ~12,000 academic papers and synthesize 11,359 scenarios where 2-5 patterns reinforce, conflict, or modulate each other, with multi-turn conversations expressing inner thoughts, actions, and dialogue. Our dual-level checklists evaluate both individual pattern fidelity and emergent multi-pattern dynamics, achieving strong human alignment (r=0.91) while revealing that holistic metrics conflate simulation accuracy with social desirability. HUMANLLM-8B outperforms Qwen3-32B on multi-pattern dynamics despite 4x fewer parameters, demonstrating that authentic anthropomorphism requires cognitive modeling--simulating not just what humans do, but the psychological processes generating those behaviors.
Language Drift in Multilingual Retrieval-Augmented Generation: Characterization and Decoding-Time Mitigation
Nov 13, 2025



Multilingual Retrieval-Augmented Generation (RAG) enables large language models (LLMs) to perform knowledge-intensive tasks in multilingual settings by leveraging retrieved documents as external evidence. However, when the retrieved evidence differs in language from the user query and in-context exemplars, the model often exhibits language drift by generating responses in an unintended language. This phenomenon is especially pronounced during reasoning-intensive decoding, such as Chain-of-Thought (CoT) generation, where intermediate steps introduce further language instability. In this paper, we systematically study output language drift in multilingual RAG across multiple datasets, languages, and LLM backbones. Our controlled experiments reveal that the drift results not from comprehension failure but from decoder-level collapse, where dominant token distributions and high-frequency English patterns dominate the intended generation language. We further observe that English serves as a semantic attractor under cross-lingual conditions, emerging as both the strongest interference source and the most frequent fallback language. To mitigate this, we propose Soft Constrained Decoding (SCD), a lightweight, training-free decoding strategy that gently steers generation toward the target language by penalizing non-target-language tokens. SCD is model-agnostic and can be applied to any generation algorithm without modifying the architecture or requiring additional data. Experiments across three multilingual datasets and multiple typologically diverse languages show that SCD consistently improves language alignment and task performance, providing an effective and generalizable solution in multilingual RAG.
Mitigating Spurious Correlations with Causal Logit Perturbation
May 21, 2025Deep learning has seen widespread success in various domains such as science, industry, and society. However, it is acknowledged that certain approaches suffer from non-robustness, relying on spurious correlations for predictions. Addressing these limitations is of paramount importance, necessitating the development of methods that can disentangle spurious correlations. {This study attempts to implement causal models via logit perturbations and introduces a novel Causal Logit Perturbation (CLP) framework to train classifiers with generated causal logit perturbations for individual samples, thereby mitigating the spurious associations between non-causal attributes (i.e., image backgrounds) and classes.} {Our framework employs a} perturbation network to generate sample-wise logit perturbations using a series of training characteristics of samples as inputs. The whole framework is optimized by an online meta-learning-based learning algorithm and leverages human causal knowledge by augmenting metadata in both counterfactual and factual manners. Empirical evaluations on four typical biased learning scenarios, including long-tail learning, noisy label learning, generalized long-tail learning, and subpopulation shift learning, demonstrate that CLP consistently achieves state-of-the-art performance. Moreover, visualization results support the effectiveness of the generated causal perturbations in redirecting model attention towards causal image attributes and dismantling spurious associations.
Continuous Optimization for Feature Selection with Permutation-Invariant Embedding and Policy-Guided Search
May 16, 2025Feature selection removes redundant features to enhanc performance and computational efficiency in downstream tasks. Existing works often struggle to capture complex feature interactions and adapt to diverse scenarios. Recent advances in this domain have incorporated generative intelligence to address these drawbacks by uncovering intricate relationships between features. However, two key limitations remain: 1) embedding feature subsets in a continuous space is challenging due to permutation sensitivity, as changes in feature order can introduce biases and weaken the embedding learning process; 2) gradient-based search in the embedding space assumes convexity, which is rarely guaranteed, leading to reduced search effectiveness and suboptimal subsets. To address these limitations, we propose a new framework that can: 1) preserve feature subset knowledge in a continuous embedding space while ensuring permutation invariance; 2) effectively explore the embedding space without relying on strong convex assumptions. For the first objective, we develop an encoder-decoder paradigm to preserve feature selection knowledge into a continuous embedding space. This paradigm captures feature interactions through pairwise relationships within the subset, removing the influence of feature order on the embedding. Moreover, an inducing point mechanism is introduced to accelerate pairwise relationship computations. For the second objective, we employ a policy-based reinforcement learning (RL) approach to guide the exploration of the embedding space. The RL agent effectively navigates the space by balancing multiple objectives. By prioritizing high-potential regions adaptively and eliminating the reliance on convexity assumptions, the RL agent effectively reduces the risk of converging to local optima. Extensive experiments demonstrate the effectiveness, efficiency, robustness and explicitness of our model.
TongUI: Building Generalized GUI Agents by Learning from Multimodal Web Tutorials
Apr 17, 2025Building Graphical User Interface (GUI) agents is a promising research direction, which simulates human interaction with computers or mobile phones to perform diverse GUI tasks. However, a major challenge in developing generalized GUI agents is the lack of sufficient trajectory data across various operating systems and applications, mainly due to the high cost of manual annotations. In this paper, we propose the TongUI framework that builds generalized GUI agents by learning from rich multimodal web tutorials. Concretely, we crawl and process online GUI tutorials (such as videos and articles) into GUI agent trajectory data, through which we produce the GUI-Net dataset containing 143K trajectory data across five operating systems and more than 200 applications. We develop the TongUI agent by fine-tuning Qwen2.5-VL-3B/7B models on GUI-Net, which show remarkable performance improvements on commonly used grounding and navigation benchmarks, outperforming baseline agents about 10\% on multiple benchmarks, showing the effectiveness of the GUI-Net dataset and underscoring the significance of our TongUI framework. We will fully open-source the code, the GUI-Net dataset, and the trained models soon.
VGDFR: Diffusion-based Video Generation with Dynamic Latent Frame Rate
Apr 16, 2025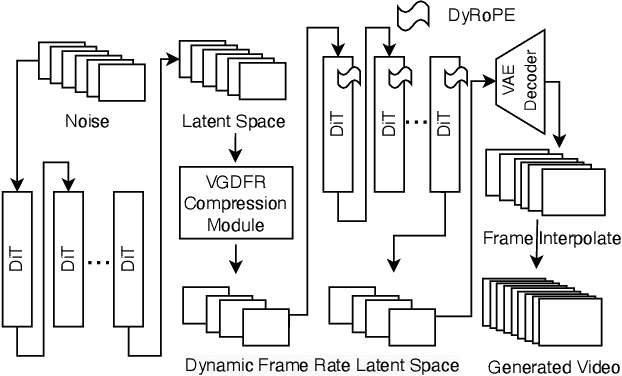
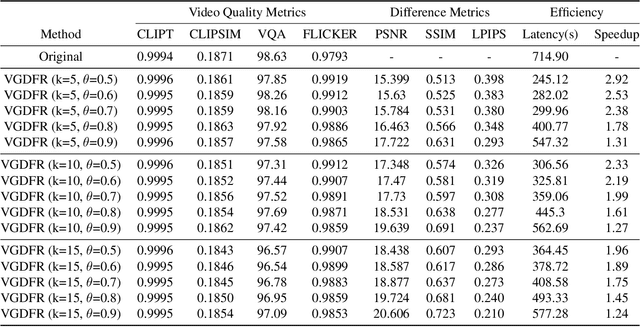
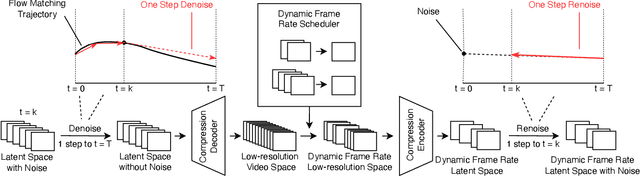

Diffusion Transformer(DiT)-based generation models have achieved remarkable success in video generation. However, their inherent computational demands pose significant efficiency challenges. In this paper, we exploit the inherent temporal non-uniformity of real-world videos and observe that videos exhibit dynamic information density, with high-motion segments demanding greater detail preservation than static scenes. Inspired by this temporal non-uniformity, we propose VGDFR, a training-free approach for Diffusion-based Video Generation with Dynamic Latent Frame Rate. VGDFR adaptively adjusts the number of elements in latent space based on the motion frequency of the latent space content, using fewer tokens for low-frequency segments while preserving detail in high-frequency segments. Specifically, our key contributions are: (1) A dynamic frame rate scheduler for DiT video generation that adaptively assigns frame rates for video segments. (2) A novel latent-space frame merging method to align latent representations with their denoised counterparts before merging those redundant in low-resolution space. (3) A preference analysis of Rotary Positional Embeddings (RoPE) across DiT layers, informing a tailored RoPE strategy optimized for semantic and local information capture. Experiments show that VGDFR can achieve a speedup up to 3x for video generation with minimal quality degradation.