 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashOverlap: A Lightweight Design for Efficiently Overlapping Communication and Computation
Apr 28, 2025Generative models have achieved remarkable success across various applications, driving the demand for multi-GPU computing. Inter-GPU communication becomes a bottleneck in multi-GPU computing systems, particularly on consumer-grade GPUs. By exploiting concurrent hardware execution, overlapping computation and communication latency is an effective technique for mitigating the communication overhead. We identify that an efficient and adaptable overlapping design should satisfy (1) tile-wise overlapping to maximize the overlapping opportunity, (2) interference-free computation to maintain the original computational performance, and (3) communication agnosticism to reduce the development burden against varying communication primitives. Nevertheless, current designs fail to simultaneously optimize for all of those features. To address the issue, we propose FlashOverlap, a lightweight design characterized by tile-wise overlapping, interference-free computation, and communication agnosticism. FlashOverlap utilizes a novel signaling mechanism to identify tile-wise data dependency without interrupting the computation process, and reorders data to contiguous addresses, enabling communication by simply calling NCCL APIs. Experiments show that such a lightweight design achieves up to 1.65x speedup, outperforming existing works in most cases.
LiteVAR: Compressing Visual Autoregressive Modelling with Efficient Attention and Quantization
Nov 26, 2024Visual Autoregressive (VAR) has emerged as a promising approach in image generation, offering competitive potential and performance comparable to diffusion-based models. However, current AR-based visual generation models require substantial computational resources, limiting their applicability on resource-constrained devices. To address this issue, we conducted analysis and identified significant redundancy in three dimensions of the VAR model: (1) the attention map, (2) the attention outputs when using classifier free guidance, and (3) the data precision. Correspondingly, we proposed efficient attention mechanism and low-bit quantization method to enhance the efficiency of VAR models while maintaining performance. With negligible performance lost (less than 0.056 FID increase), we could achieve 85.2% reduction in attention computation, 50% reduction in overall memory and 1.5x latency reduction. To ensure deployment feasibility, we developed efficient training-free compression techniques and analyze the deployment feasibility and efficiency gain of each technique.
Efficient and Effective Retrieval of Dense-Sparse Hybrid Vectors using Graph-based Approximate Nearest Neighbor Search
Oct 27, 2024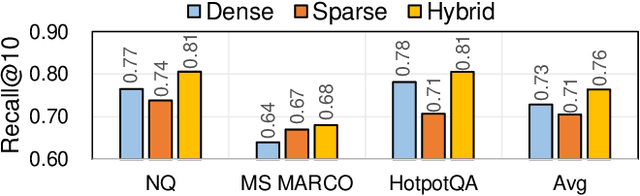

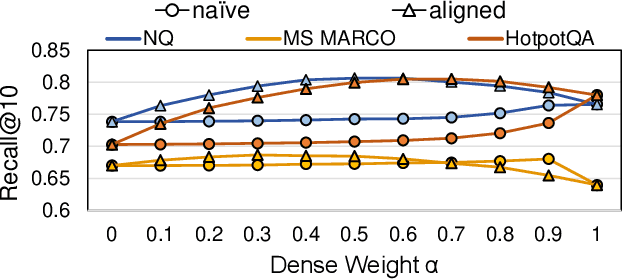

ANNS for embedded vector representations of texts is commonly used in information retrieval, with two important information representations being sparse and dense vectors. While it has been shown that combining these representations improves accuracy, the current method of conducting sparse and dense vector searches separately suffers from low scalability and high system complexity. Alternatively, building a unified index faces challenges with accuracy and efficiency. To address these issues, we propose a graph-based ANNS algorithm for dense-sparse hybrid vectors. Firstly, we propose a distribution alignment method to improve accuracy, which pre-samples dense and sparse vectors to analyze their distance distribution statistic, resulting in a 1%$\sim$9% increase in accuracy. Secondly, to improve efficiency, we design an adaptive two-stage computation strategy that initially computes dense distances only and later computes hybrid distances. Further, we prune the sparse vectors to speed up the calculation. Compared to naive implementation, we achieve $\sim2.1\times$ acceleration. Thorough experiments show that our algorithm achieves 8.9x$\sim$11.7x throughput at equal accuracy compared to existing hybrid vector search algorithms.
EPIM: Efficient Processing-In-Memory Accelerators based on Epitome
Nov 12, 2023
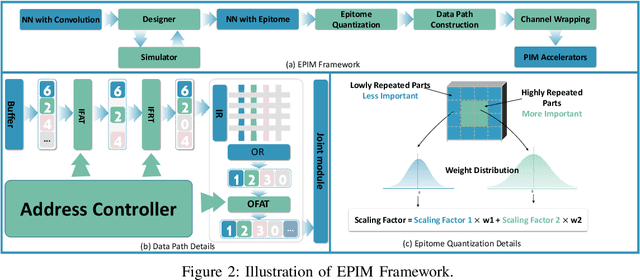


The exploration of Processing-In-Memory (PIM) accelerators has garnered significant attention within the research community. However, the utilization of large-scale neural networks on Processing-In-Memory (PIM) accelerators encounters challenges due to constrained on-chip memory capacity. To tackle this issue, current works explore model compression algorithms to reduce the size of Convolutional Neural Networks (CNNs). Most of these algorithms either aim to represent neural operators with reduced-size parameters (e.g., quantization) or search for the best combinations of neural operators (e.g., neural architecture search). Designing neural operators to align with PIM accelerators' specifications is an area that warrants further study. In this paper, we introduce the Epitome, a lightweight neural operator offering convolution-like functionality, to craft memory-efficient CNN operators for PIM accelerators (EPIM). On the software side, we evaluate epitomes' latency and energy on PIM accelerators and introduce a PIM-aware layer-wise design method to enhance their hardware efficiency. We apply epitome-aware quantization to further reduce the size of epitomes. On the hardware side, we modify the datapath of current PIM accelerators to accommodate epitomes and implement a feature map reuse technique to reduce computation cost. Experimental results reveal that our 3-bit quantized EPIM-ResNet50 attains 71.59% top-1 accuracy on ImageNet, reducing crossbar areas by 30.65 times. EPIM surpasses the state-of-the-art pruning methods on PIM.
FTT-NAS: Discovering Fault-Tolerant Neural Architecture
Mar 20, 2020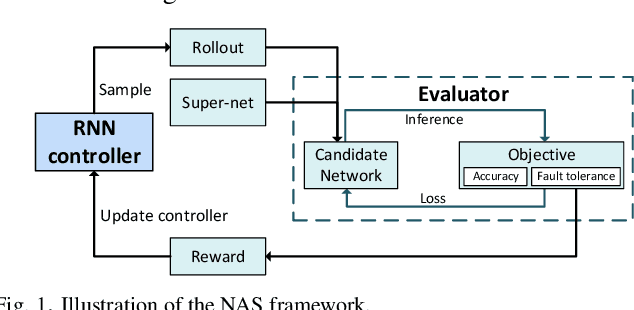
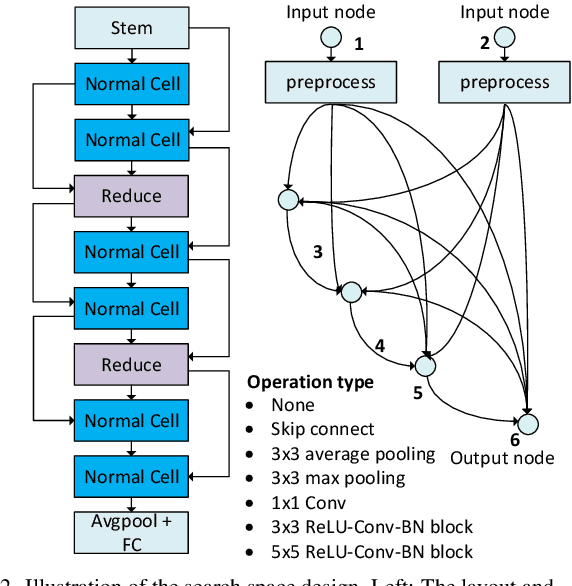
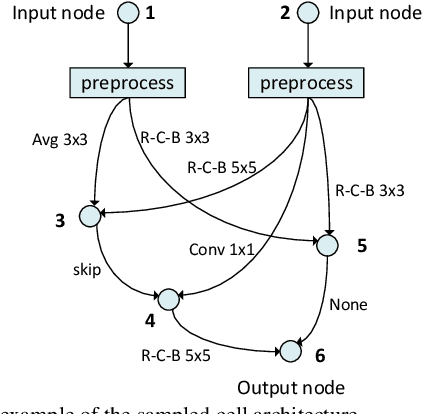
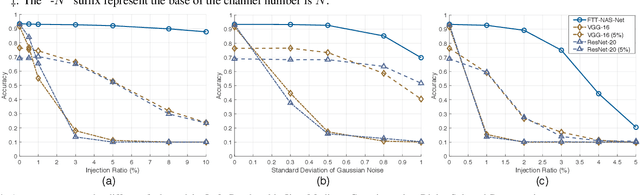
With the fast evolvement of embedded deep-learning computing systems, applications powered by deep learning are moving from the cloud to the edge. When deploying neural networks (NNs) onto the devices under complex environments, there are various types of possible faults: soft errors caused by cosmic radiation and radioactive impurities, voltage instability, aging, temperature variations, and malicious attackers. Thus the safety risk of deploying NNs is now drawing much attention. In this paper, after the analysis of the possible faults in various types of NN accelerators, we formalize and implement various fault models from the algorithmic perspective. We propose Fault-Tolerant Neural Architecture Search (FT-NAS) to automatically discover convolutional neural network (CNN) architectures that are reliable to various faults in nowadays devices. Then we incorporate fault-tolerant training (FTT) in the search process to achieve better results, which is referred to as FTT-NAS. Experiments on CIFAR-10 show that the discovered architectures outperform other manually designed baseline architectures significantly, with comparable or fewer floating-point operations (FLOPs) and parameters. Specifically, with the same fault settings, F-FTT-Net discovered under the feature fault model achieves an accuracy of 86.2% (VS. 68.1% achieved by MobileNet-V2), and W-FTT-Net discovered under the weight fault model achieves an accuracy of 69.6% (VS. 60.8% achieved by ResNet-20). By inspecting the discovered architectures, we find that the operation primitives, the weight quantization range, the capacity of the model, and the connection pattern have influences on the fault resilience capability of NN models.