 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Efficient and Flexible FPGA Virtualization for Deep Learning in the Cloud
Mar 26, 2020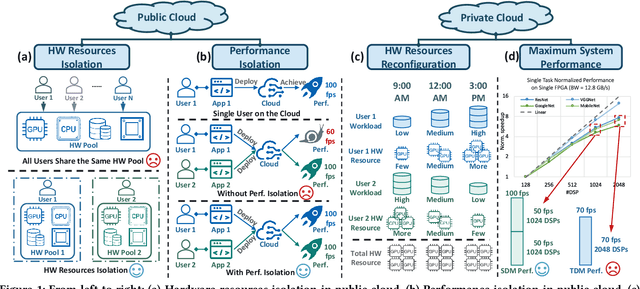
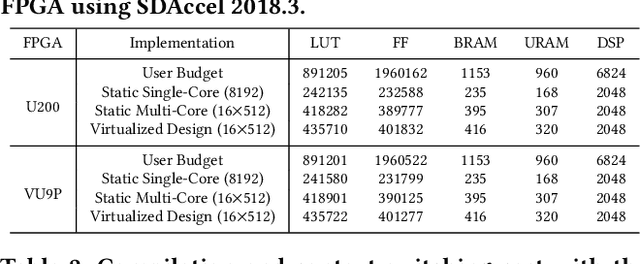
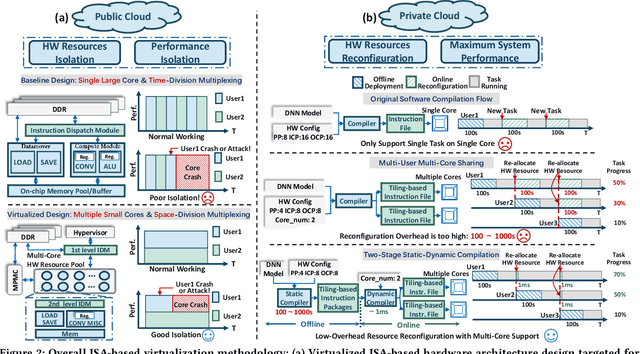
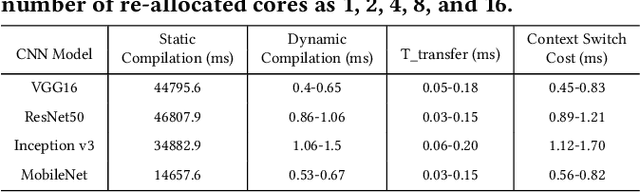
FPGAs have shown great potential in providing low-latency and energy-efficient solutions for deep neural network (DNN) inference applications. Currently, the majority of FPGA-based DNN accelerators in the cloud run in a time-division multiplexing way for multiple users sharing a single FPGA, and require re-compilation with $\sim$100 s overhead. Such designs lead to poor isolation and heavy performance loss for multiple users, which are far away from providing efficient and flexible FPGA virtualization for neither public nor private cloud scenarios. To solve these problems, we introduce a novel virtualization framework for instruction architecture set (ISA) based on DNN accelerators by sharing a single FPGA. We enable the isolation by introducing a two-level instruction dispatch module and a multi-core based hardware resources pool. Such designs provide isolated and runtime-programmable hardware resources, further leading to performance isolation for multiple users. On the other hand, to overcome the heavy re-compilation overheads, we propose a tiling-based instruction frame package design and two-stage static-dynamic compilation. Only the light-weight runtime information is re-compiled with $\sim$1 ms overhead, thus the performance is guaranteed for the private cloud. Our extensive experimental results show that the proposed virtualization design achieves 1.07-1.69x and 1.88-3.12x throughput improvement over previous static designs using the single-core and the multi-core architectures, respectively.
FTT-NAS: Discovering Fault-Tolerant Neural Architecture
Mar 20, 2020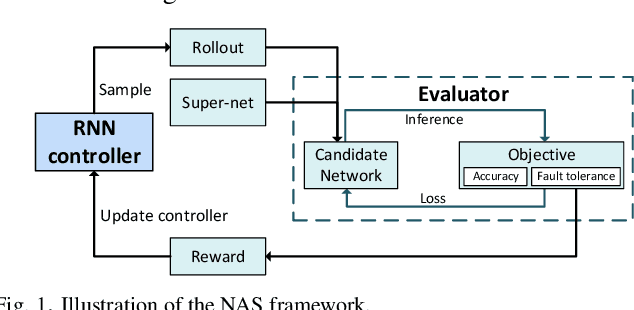
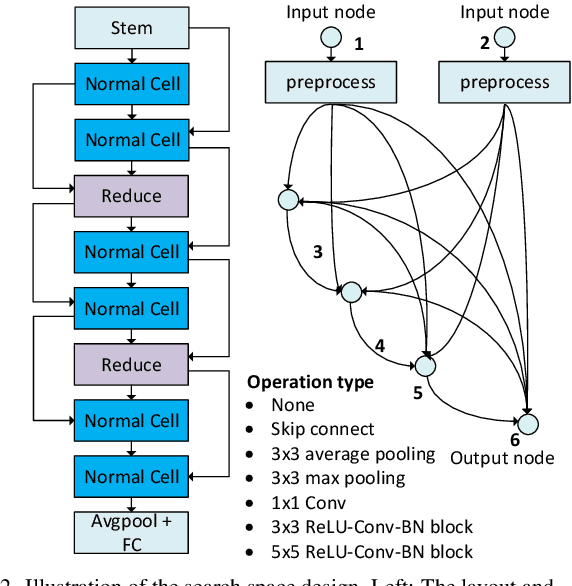
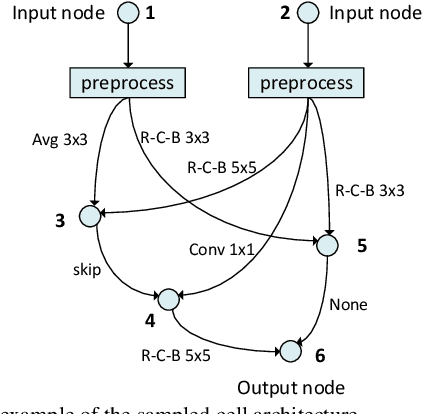
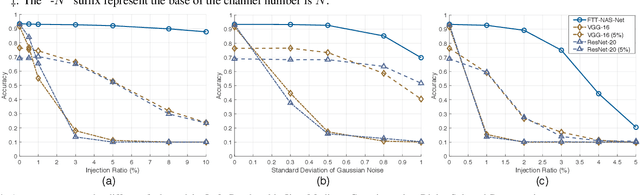
With the fast evolvement of embedded deep-learning computing systems, applications powered by deep learning are moving from the cloud to the edge. When deploying neural networks (NNs) onto the devices under complex environments, there are various types of possible faults: soft errors caused by cosmic radiation and radioactive impurities, voltage instability, aging, temperature variations, and malicious attackers. Thus the safety risk of deploying NNs is now drawing much attention. In this paper, after the analysis of the possible faults in various types of NN accelerators, we formalize and implement various fault models from the algorithmic perspective. We propose Fault-Tolerant Neural Architecture Search (FT-NAS) to automatically discover convolutional neural network (CNN) architectures that are reliable to various faults in nowadays devices. Then we incorporate fault-tolerant training (FTT) in the search process to achieve better results, which is referred to as FTT-NAS. Experiments on CIFAR-10 show that the discovered architectures outperform other manually designed baseline architectures significantly, with comparable or fewer floating-point operations (FLOPs) and parameters. Specifically, with the same fault settings, F-FTT-Net discovered under the feature fault model achieves an accuracy of 86.2% (VS. 68.1% achieved by MobileNet-V2), and W-FTT-Net discovered under the weight fault model achieves an accuracy of 69.6% (VS. 60.8% achieved by ResNet-20). By inspecting the discovered architectures, we find that the operation primitives, the weight quantization range, the capacity of the model, and the connection pattern have influences on the fault resilience capability of NN models.