 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate and Efficient Sub-8-Bit Integer Training
Nov 17, 2024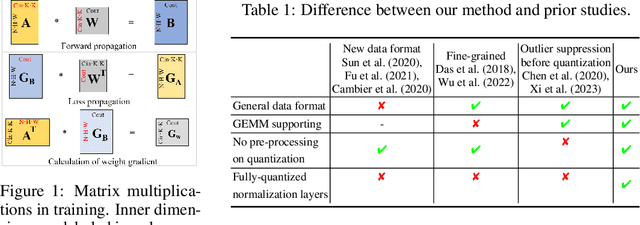
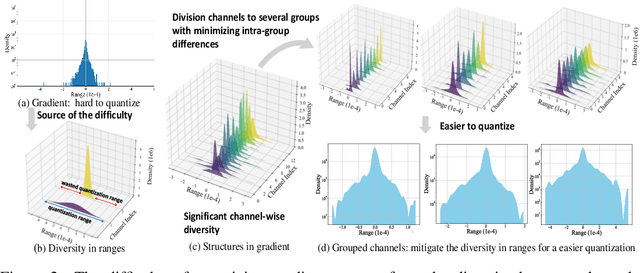
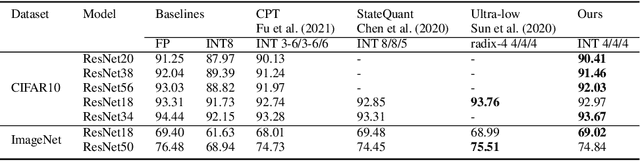
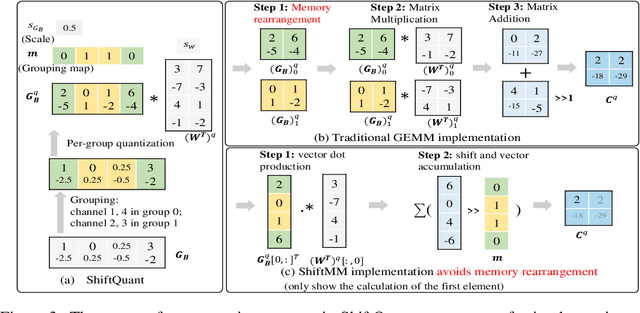
Neural network training is a memory- and compute-intensive task. Quantization, which enables low-bitwidth formats in training, can significantly mitigate the workload. To reduce quantization error, recent methods have developed new data formats and additional pre-processing operations on quantizers. However, it remains quite challenging to achieve high accuracy and efficiency simultaneously. In this paper, we explore sub-8-bit integer training from its essence of gradient descent optimization. Our integer training framework includes two components: ShiftQuant to realize accurate gradient estimation, and L1 normalization to smoothen the loss landscape. ShiftQuant attains performance that approaches the theoretical upper bound of group quantization. Furthermore, it liberates group quantization from inefficient memory rearrangement. The L1 normalization facilitates the implementation of fully quantized normalization layers with impressive convergence accuracy. Our method frees sub-8-bit integer training from pre-processing and supports general devices. This framework achieves negligible accuracy loss across various neural networks and tasks ($0.92\%$ on 4-bit ResNets, $0.61\%$ on 6-bit Transformers). The prototypical implementation of ShiftQuant achieves more than $1.85\times/15.3\%$ performance improvement on CPU/GPU compared to its FP16 counterparts, and $33.9\%$ resource consumption reduction on FPGA than the FP16 counterparts. The proposed fully-quantized L1 normalization layers achieve more than $35.54\%$ improvement in throughout on CPU compared to traditional L2 normalization layers. Moreover, theoretical analysis verifies the advancement of our method.
Efficient and Effective Retrieval of Dense-Sparse Hybrid Vectors using Graph-based Approximate Nearest Neighbor Search
Oct 27, 2024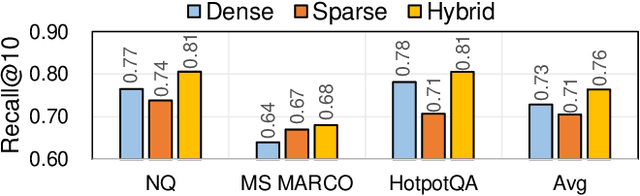

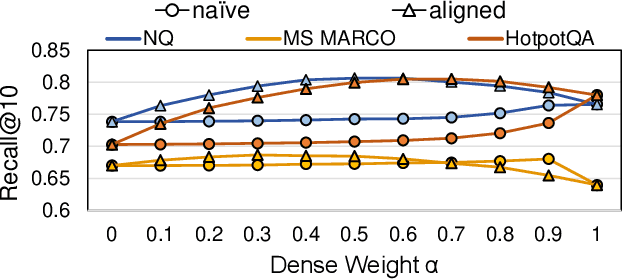

ANNS for embedded vector representations of texts is commonly used in information retrieval, with two important information representations being sparse and dense vectors. While it has been shown that combining these representations improves accuracy, the current method of conducting sparse and dense vector searches separately suffers from low scalability and high system complexity. Alternatively, building a unified index faces challenges with accuracy and efficiency. To address these issues, we propose a graph-based ANNS algorithm for dense-sparse hybrid vectors. Firstly, we propose a distribution alignment method to improve accuracy, which pre-samples dense and sparse vectors to analyze their distance distribution statistic, resulting in a 1%$\sim$9% increase in accuracy. Secondly, to improve efficiency, we design an adaptive two-stage computation strategy that initially computes dense distances only and later computes hybrid distances. Further, we prune the sparse vectors to speed up the calculation. Compared to naive implementation, we achieve $\sim2.1\times$ acceleration. Thorough experiments show that our algorithm achieves 8.9x$\sim$11.7x throughput at equal accuracy compared to existing hybrid vector search algorithms.
FlightLLM: Efficient Large Language Model Inference with a Complete Mapping Flow on FPGAs
Jan 09, 2024



Transformer-based Large Language Models (LLMs) have made a significant impact on various domains. However, LLMs' efficiency suffers from both heavy computation and memory overheads. Compression techniques like sparsification and quantization are commonly used to mitigate the gap between LLM's computation/memory overheads and hardware capacity. However, existing GPU and transformer-based accelerators cannot efficiently process compressed LLMs, due to the following unresolved challenges: low computational efficiency, underutilized memory bandwidth, and large compilation overheads. This paper proposes FlightLLM, enabling efficient LLMs inference with a complete mapping flow on FPGAs. In FlightLLM, we highlight an innovative solution that the computation and memory overhead of LLMs can be solved by utilizing FPGA-specific resources (e.g., DSP48 and heterogeneous memory hierarchy). We propose a configurable sparse DSP chain to support different sparsity patterns with high computation efficiency. Second, we propose an always-on-chip decode scheme to boost memory bandwidth with mixed-precision support. Finally, to make FlightLLM available for real-world LLMs, we propose a length adaptive compilation method to reduce the compilation overhead. Implemented on the Xilinx Alveo U280 FPGA, FlightLLM achieves 6.0$\times$ higher energy efficiency and 1.8$\times$ better cost efficiency against commercial GPUs (e.g., NVIDIA V100S) on modern LLMs (e.g., LLaMA2-7B) using vLLM and SmoothQuant under the batch size of one. FlightLLM beats NVIDIA A100 GPU with 1.2$\times$ higher throughput using the latest Versal VHK158 FPGA.
Towards Lower Bit Multiplication for Convolutional Neural Network Training
Jun 04, 2020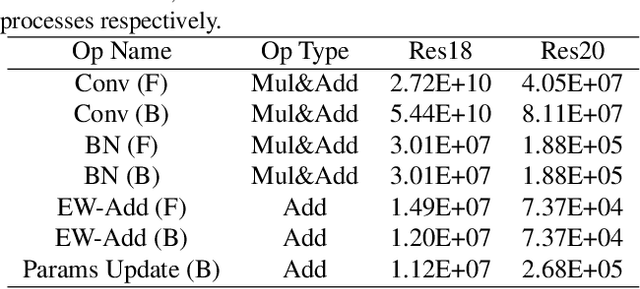
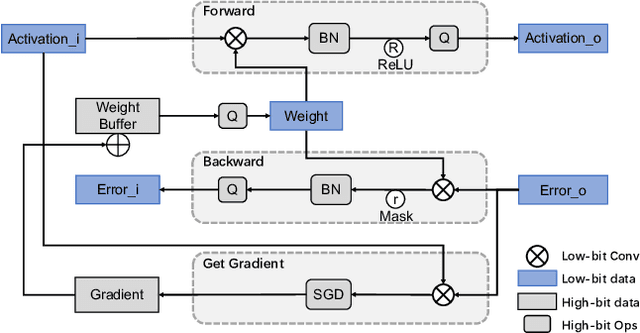
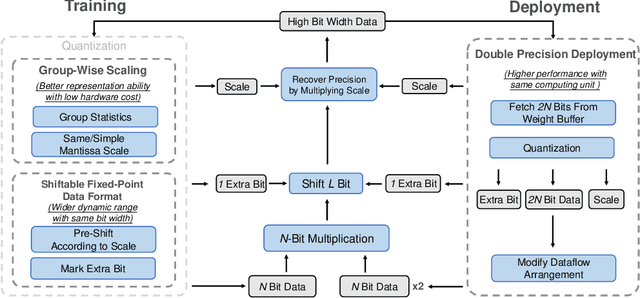
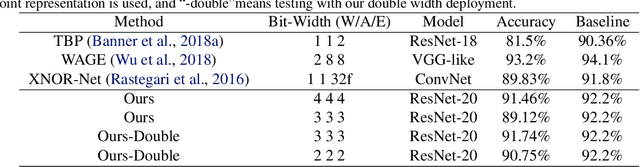
Convolutional Neural Networks (CNNs) have been widely used in many fields. However, the training process costs much energy and time, in which the convolution operations consume the major part. In this paper, we propose a fixed-point training framework, in order to reduce the data bit-width for the convolution multiplications. Firstly, we propose two constrained group-wise scaling methods that can be implemented with low hardware cost. Secondly, to overcome the challenge of trading off overflow and rounding error, a shiftable fixed-point data format is used in this framework. Finally, we propose a double-width deployment technique to boost inference performance with the same bit-width hardware multiplier. The experimental results show that the input data of convolution in the training process can be quantized to 2-bit for CIFAR-10 dataset, 6-bit for ImageNet dataset, with negligible accuracy degradation. Furthermore, our fixed-point train-ing framework has the potential to save at least 75% energy of the computation in the training process.
Enabling Efficient and Flexible FPGA Virtualization for Deep Learning in the Cloud
Mar 26, 2020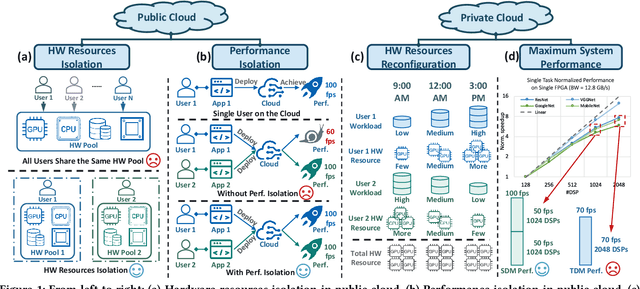
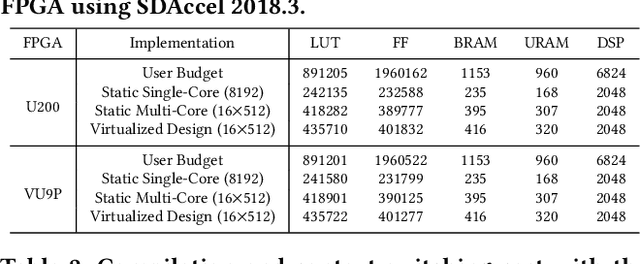
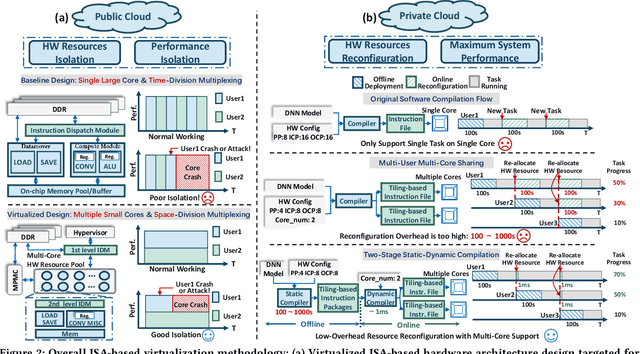
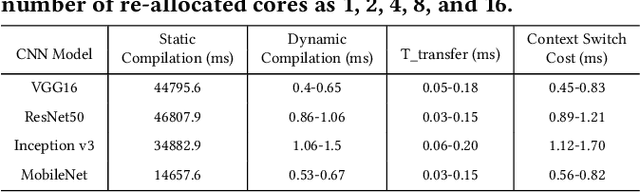
FPGAs have shown great potential in providing low-latency and energy-efficient solutions for deep neural network (DNN) inference applications. Currently, the majority of FPGA-based DNN accelerators in the cloud run in a time-division multiplexing way for multiple users sharing a single FPGA, and require re-compilation with $\sim$100 s overhead. Such designs lead to poor isolation and heavy performance loss for multiple users, which are far away from providing efficient and flexible FPGA virtualization for neither public nor private cloud scenarios. To solve these problems, we introduce a novel virtualization framework for instruction architecture set (ISA) based on DNN accelerators by sharing a single FPGA. We enable the isolation by introducing a two-level instruction dispatch module and a multi-core based hardware resources pool. Such designs provide isolated and runtime-programmable hardware resources, further leading to performance isolation for multiple users. On the other hand, to overcome the heavy re-compilation overheads, we propose a tiling-based instruction frame package design and two-stage static-dynamic compilation. Only the light-weight runtime information is re-compiled with $\sim$1 ms overhead, thus the performance is guaranteed for the private cloud. Our extensive experimental results show that the proposed virtualization design achieves 1.07-1.69x and 1.88-3.12x throughput improvement over previous static designs using the single-core and the multi-core architectures, respectively.