 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Effective Retrieval of Dense-Sparse Hybrid Vectors using Graph-based Approximate Nearest Neighbor Search
Oct 27, 2024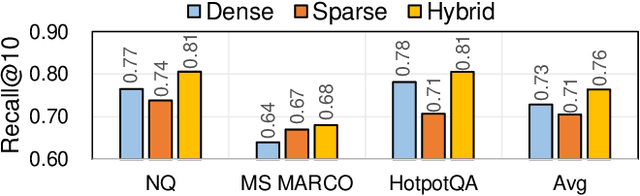

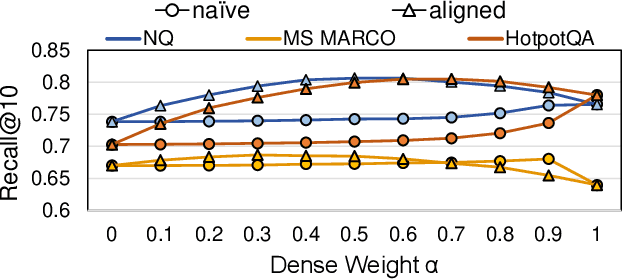

ANNS for embedded vector representations of texts is commonly used in information retrieval, with two important information representations being sparse and dense vectors. While it has been shown that combining these representations improves accuracy, the current method of conducting sparse and dense vector searches separately suffers from low scalability and high system complexity. Alternatively, building a unified index faces challenges with accuracy and efficiency. To address these issues, we propose a graph-based ANNS algorithm for dense-sparse hybrid vectors. Firstly, we propose a distribution alignment method to improve accuracy, which pre-samples dense and sparse vectors to analyze their distance distribution statistic, resulting in a 1%$\sim$9% increase in accuracy. Secondly, to improve efficiency, we design an adaptive two-stage computation strategy that initially computes dense distances only and later computes hybrid distances. Further, we prune the sparse vectors to speed up the calculation. Compared to naive implementation, we achieve $\sim2.1\times$ acceleration. Thorough experiments show that our algorithm achieves 8.9x$\sim$11.7x throughput at equal accuracy compared to existing hybrid vector search algorithms.