 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfini Memory: Maintainable Topic Documents for Long-Term LLM Agent Memory
Jun 09, 2026Long-term LLM agents need persistent memory that can track changing facts and provide relevant evidence across sessions. Existing memory systems often store observations as isolated records, summaries, or indexed fragments, which makes evidence aggregation, fact revision, and memory maintenance difficult. We propose Infini Memory, a maintainable text-based persistent memory architecture that treats agent memory as topic-structured documents. Each topic document serves as a semantic unit for collecting related evidence, preserving metadata, and revising facts over time. New observations are first staged in a buffer and periodically consolidated into coherent textual contexts. At inference time, an agentic retrieval procedure lets the LLM read memory through iterative tool calls rather than a single retrieval step. On MemoryAgentBench, Infini Memory achieves 64.7% overall score. Ablations show that topic-structured maintenance and iterative evidence inspection improve complementary aspects of long-term memory use.
ScoRe-Flow: Complete Distributional Control via Score-Based Reinforcement Learning for Flow Matching
Apr 13, 2026Flow Matching (FM) policies have emerged as an efficient backbone for robotic control, offering fast and expressive action generation that underpins recent large-scale embodied AI systems. However, FM policies trained via imitation learning inherit the limitations of demonstration data; surpassing suboptimal behaviors requires reinforcement learning (RL) fine-tuning. Recent methods convert deterministic flows into stochastic differential equations (SDEs) with learnable noise injection, enabling exploration and tractable likelihoods, but such noise-only control can compromise training efficiency when demonstrations already provide strong priors. We observe that modulating the drift via the score function, i.e., the gradient of log-density, steers exploration toward high-probability regions, improving stability. The score admits a closed-form expression from the velocity field, requiring no auxiliary networks. Based on this, we propose ScoRe-Flow, a score-based RL fine-tuning method that combines drift modulation with learned variance prediction to achieve decoupled control over the mean and variance of stochastic transitions. Experiments demonstrate that ScoRe-Flow achieves 2.4x faster convergence than flow-based SOTA on D4RL locomotion tasks and up to 5.4% higher success rates on Robomimic and Franka Kitchen manipulation tasks.
STEP: Warm-Started Visuomotor Policies with Spatiotemporal Consistency Prediction
Feb 09, 2026Diffusion policies have recently emerged as a powerful paradigm for visuomotor control in robotic manipulation due to their ability to model the distribution of action sequences and capture multimodality. However, iterative denoising leads to substantial inference latency, limiting control frequency in real-time closed-loop systems. Existing acceleration methods either reduce sampling steps, bypass diffusion through direct prediction, or reuse past actions, but often struggle to jointly preserve action quality and achieve consistently low latency. In this work, we propose STEP, a lightweight spatiotemporal consistency prediction mechanism to construct high-quality warm-start actions that are both distributionally close to the target action and temporally consistent, without compromising the generative capability of the original diffusion policy. Then, we propose a velocity-aware perturbation injection mechanism that adaptively modulates actuation excitation based on temporal action variation to prevent execution stall especially for real-world tasks. We further provide a theoretical analysis showing that the proposed prediction induces a locally contractive mapping, ensuring convergence of action errors during diffusion refinement. We conduct extensive evaluations on nine simulated benchmarks and two real-world tasks. Notably, STEP with 2 steps can achieve an average 21.6% and 27.5% higher success rate than BRIDGER and DDIM on the RoboMimic benchmark and real-world tasks, respectively. These results demonstrate that STEP consistently advances the Pareto frontier of inference latency and success rate over existing methods.
DynSplit-KV: Dynamic Semantic Splitting for KVCache Compression in Efficient Long-Context LLM Inference
Feb 03, 2026Although Key-Value (KV) Cache is essential for efficient large language models (LLMs) inference, its growing memory footprint in long-context scenarios poses a significant bottleneck, making KVCache compression crucial. Current compression methods rely on rigid splitting strategies, such as fixed intervals or pre-defined delimiters. We observe that rigid splitting suffers from significant accuracy degradation (ranging from 5.5% to 55.1%) across different scenarios, owing to the scenario-dependent nature of the semantic boundaries. This highlights the necessity of dynamic semantic splitting to match semantics. To achieve this, we face two challenges. (1) Improper delimiter selection misaligns semantics with the KVCache, resulting in 28.6% accuracy loss. (2) Variable-length blocks after splitting introduce over 73.1% additional inference overhead. To address the above challenges, we propose DynSplit-KV, a KVCache compression method that dynamically identifies delimiters for splitting. We propose: (1) a dynamic importance-aware delimiter selection strategy, improving accuracy by 49.9%. (2) A uniform mapping strategy that transforms variable-length semantic blocks into a fixed-length format, reducing inference overhead by 4.9x. Experiments show that DynSplit-KV achieves the highest accuracy, 2.2x speedup compared with FlashAttention and 2.6x peak memory reduction in long-context scenarios.
SJD++: Improved Speculative Jacobi Decoding for Training-free Acceleration of Discrete Auto-regressive Text-to-Image Generation
Dec 08, 2025Large autoregressive models can generate high-quality, high-resolution images but suffer from slow generation speed, because these models require hundreds to thousands of sequential forward passes for next-token prediction during inference. To accelerate autoregressive text-to-image generation, we propose Speculative Jacobi Decoding++ (SJD++), a training-free probabilistic parallel decoding algorithm. Unlike traditional next-token prediction, SJD++ performs multi-token prediction in each forward pass, drastically reducing generation steps. Specifically, it integrates the iterative multi-token prediction mechanism from Jacobi decoding, with the probabilistic drafting-and-verification mechanism from speculative sampling. More importantly, for further acceleration, SJD++ reuses high-confidence draft tokens after each verification phase instead of resampling them all. We conduct extensive experiments on several representative autoregressive text-to-image generation models and demonstrate that SJD++ achieves $2\times$ to $3\times$ inference latency reduction and $2\times$ to $7\times$ step compression, while preserving visual quality with no observable degradation.
BitSnap: Checkpoint Sparsification and Quantization in LLM Training
Nov 18, 2025As large language models (LLMs) continue to grow in size and complexity, efficient checkpoint saving\&loading has become crucial for managing storage, memory usage, and fault tolerance in LLM training. The current works do not comprehensively take into account the optimization of these several aspects. This paper proposes a novel checkpoint sparsification and quantization method that adapts dynamically to different training stages and model architectures. We present a comprehensive analysis of existing lossy and lossless compression techniques, identify current limitations, and introduce our adaptive approach that balances compression ratio, speed, and precision impact throughout the training process. Experiments on different sizes of LLMs demonstrate that our bitmask-based sparsification method achieves 16x compression ratio without compromising model accuracy. Additionally, the cluster-based quantization method achieves 2x compression ratio with little precision loss.
Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models
Nov 11, 2025Improving reasoning capabilities of Large Language Models (LLMs), especially under parameter constraints, is crucial for real-world applications. Prior work proposes recurrent transformers, which allocate a fixed number of extra iterations per token to improve generation quality. After the first, standard forward pass, instead of verbalization, last-layer hidden states are fed back as inputs for additional iterations to refine token predictions. Yet we identify a latent overthinking phenomenon: easy token predictions that are already correct after the first pass are sometimes revised into errors in additional iterations. To address this, we propose Think-at-Hard (TaH), a dynamic latent thinking method that iterates deeper only at hard tokens. It employs a lightweight neural decider to trigger latent iterations only at tokens that are likely incorrect after the standard forward pass. During latent iterations, Low-Rank Adaptation (LoRA) modules shift the LLM objective from general next-token prediction to focused hard-token refinement. We further introduce a duo-causal attention mechanism that extends attention from the token sequence dimension to an additional iteration depth dimension. This enables cross-iteration information flow while maintaining full sequential parallelism. Experiments show that TaH boosts LLM reasoning performance across five challenging benchmarks while maintaining the same parameter count. Compared with baselines that iterate twice for all output tokens, TaH delivers 8.1-11.3% accuracy gains while exempting 94% of tokens from the second iteration. Against strong single-iteration Qwen3 models finetuned with the same data, it also delivers 4.0-5.0% accuracy gains. When allowing less than 3% additional parameters from LoRA and the iteration decider, the gains increase to 8.5-12.6% and 5.3-5.4%, respectively. Our code is available at https://github.com/thu-nics/TaH.
TASP: Topology-aware Sequence Parallelism
Sep 30, 2025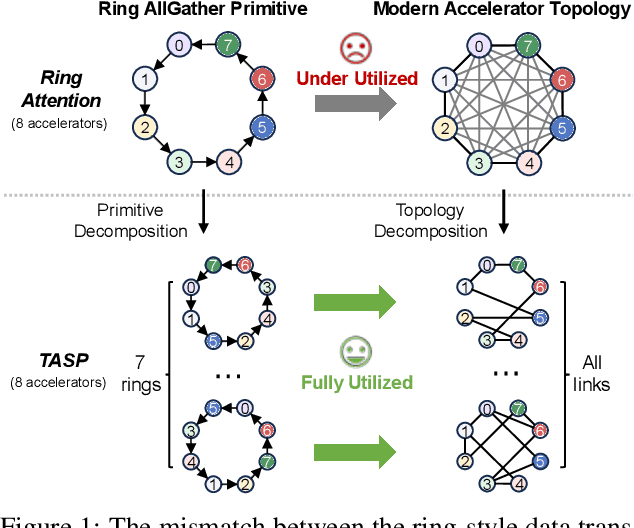


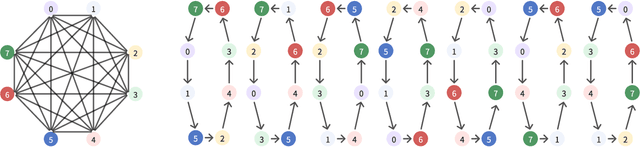
Long-context large language models (LLMs) face constraints due to the quadratic complexity of the self-attention mechanism. The mainstream sequence parallelism (SP) method, Ring Attention, attempts to solve this by distributing the query into multiple query chunks across accelerators and enable each Q tensor to access all KV tensors from other accelerators via the Ring AllGather communication primitive. However, it exhibits low communication efficiency, restricting its practical applicability. This inefficiency stems from the mismatch between the Ring AllGather communication primitive it adopts and the AlltoAll topology of modern accelerators. A Ring AllGather primitive is composed of iterations of ring-styled data transfer, which can only utilize a very limited fraction of an AlltoAll topology. Inspired by the Hamiltonian decomposition of complete directed graphs, we identify that modern accelerator topology can be decomposed into multiple orthogonal ring datapaths which can concurrently transfer data without interference. Based on this, we further observe that the Ring AllGather primitive can also be decomposed into the same number of concurrent ring-styled data transfer at every iteration. Based on these insights, we propose TASP, a topology-aware SP method for long-context LLMs that fully utilizes the communication capacity of modern accelerators via topology decomposition and primitive decomposition. Experimental results on both single-node and multi-node NVIDIA H100 systems and a single-node AMD MI300X system demonstrate that TASP achieves higher communication efficiency than Ring Attention on these modern accelerator topologies and achieves up to 3.58 speedup than Ring Attention and its variant Zigzag-Ring Attention. The code is available at https://github.com/infinigence/HamiltonAttention.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025



Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
SpecDiff: Accelerating Diffusion Model Inference with Self-Speculation
Sep 17, 2025

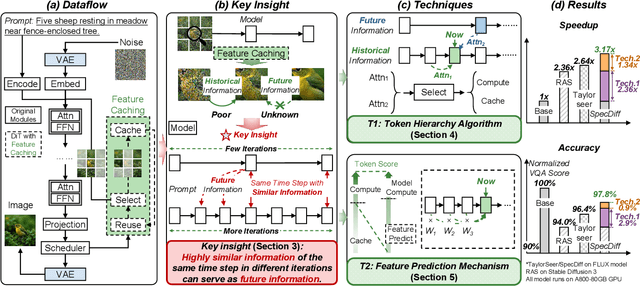

Feature caching has recently emerged as a promising method for diffusion model acceleration. It effectively alleviates the inefficiency problem caused by high computational requirements by caching similar features in the inference process of the diffusion model. In this paper, we analyze existing feature caching methods from the perspective of information utilization, and point out that relying solely on historical information will lead to constrained accuracy and speed performance. And we propose a novel paradigm that introduces future information via self-speculation based on the information similarity at the same time step across different iteration times. Based on this paradigm, we present \textit{SpecDiff}, a training-free multi-level feature caching strategy including a cached feature selection algorithm and a multi-level feature classification algorithm. (1) Feature selection algorithm based on self-speculative information. \textit{SpecDiff} determines a dynamic importance score for each token based on self-speculative information and historical information, and performs cached feature selection through the importance score. (2) Multi-level feature classification algorithm based on feature importance scores. \textit{SpecDiff} classifies tokens by leveraging the differences in feature importance scores and introduces a multi-level feature calculation strategy. Extensive experiments show that \textit{SpecDiff} achieves average 2.80 \times, 2.74 \times , and 3.17\times speedup with negligible quality loss in Stable Diffusion 3, 3.5, and FLUX compared to RFlow on NVIDIA A800-80GB GPU. By merging speculative and historical information, \textit{SpecDiff} overcomes the speedup-accuracy trade-off bottleneck, pushing the Pareto frontier of speedup and accuracy in the efficient diffusion model inference.