 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOwl-AuraID 1.0: An Intelligent System for Autonomous Scientific Instrumentation and Scientific Data Analysis
Mar 31, 2026Scientific discovery increasingly depends on high-throughput characterization, yet automation is hindered by proprietary GUIs and the limited generalizability of existing API-based systems. We present Owl-AuraID, a software-hardware collaborative embodied agent system that adopts a GUI-native paradigm to operate instruments through the same interfaces as human experts. Its skill-centric framework integrates Type-1 (GUI operation) and Type-2 (data analysis) skills into end-to-end workflows, connecting physical sample handling with scientific interpretation. Owl-AuraID demonstrates broad coverage across ten categories of precision instruments and diverse workflows, including multimodal spectral analysis, microscopic imaging, and crystallographic analysis, supporting modalities such as FTIR, NMR, AFM, and TGA. Overall, Owl-AuraID provides a practical, extensible foundation for autonomous laboratories and illustrates a path toward evolving laboratory intelligence through reusable operational and analytical skills. The code are available at https://github.com/OpenOwlab/AuraID.
SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer
Jan 23, 2026Diffusion Transformers have recently demonstrated remarkable performance in video generation. However, the long input sequences result in high computational latency due to the quadratic complexity of full attention. Various sparse attention mechanisms have been proposed. Training-free sparse attention is constrained by limited sparsity and thus offers modest acceleration, whereas training-based methods can reach much higher sparsity but demand substantial data and computation for training. In this work, we propose SALAD, introducing a lightweight linear attention branch in parallel with the sparse attention. By incorporating an input-dependent gating mechanism to finely balance the two branches, our method attains 90% sparsity and 1.72x inference speedup, while maintaining generation quality comparable to the full attention baseline. Moreover, our finetuning process is highly efficient, requiring only 2,000 video samples and 1,600 training steps with a batch size of 8.
VocabTailor: Dynamic Vocabulary Selection for Downstream Tasks in Small Language Models
Aug 21, 2025Small Language Models (SLMs) provide computational advantages in resource-constrained environments, yet memory limitations remain a critical bottleneck for edge device deployment. A substantial portion of SLMs' memory footprint stems from vocabulary-related components, particularly embeddings and language modeling (LM) heads, due to large vocabulary sizes. Existing static vocabulary pruning, while reducing memory usage, suffers from rigid, one-size-fits-all designs that cause information loss from the prefill stage and a lack of flexibility. In this work, we identify two key principles underlying the vocabulary reduction challenge: the lexical locality principle, the observation that only a small subset of tokens is required during any single inference, and the asymmetry in computational characteristics between vocabulary-related components of SLM. Based on these insights, we introduce VocabTailor, a novel decoupled dynamic vocabulary selection framework that addresses memory constraints through offloading embedding and implements a hybrid static-dynamic vocabulary selection strategy for LM Head, enabling on-demand loading of vocabulary components. Comprehensive experiments across diverse downstream tasks demonstrate that VocabTailor achieves a reduction of up to 99% in the memory usage of vocabulary-related components with minimal or no degradation in task performance, substantially outperforming existing static vocabulary pruning.
VGDFR: Diffusion-based Video Generation with Dynamic Latent Frame Rate
Apr 16, 2025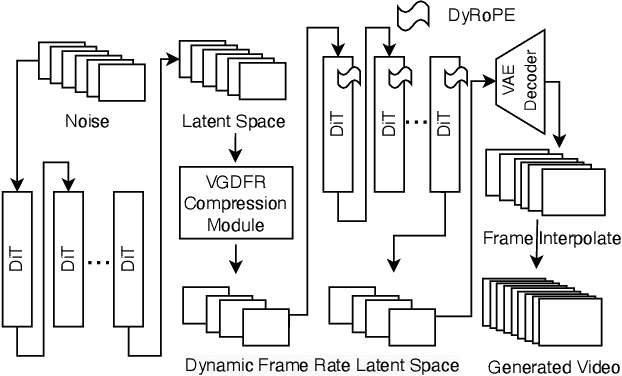
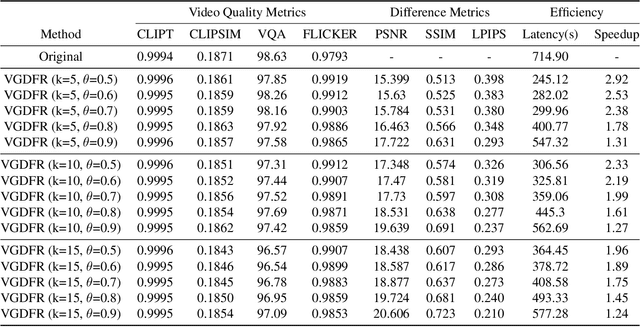

Diffusion Transformer(DiT)-based generation models have achieved remarkable success in video generation. However, their inherent computational demands pose significant efficiency challenges. In this paper, we exploit the inherent temporal non-uniformity of real-world videos and observe that videos exhibit dynamic information density, with high-motion segments demanding greater detail preservation than static scenes. Inspired by this temporal non-uniformity, we propose VGDFR, a training-free approach for Diffusion-based Video Generation with Dynamic Latent Frame Rate. VGDFR adaptively adjusts the number of elements in latent space based on the motion frequency of the latent space content, using fewer tokens for low-frequency segments while preserving detail in high-frequency segments. Specifically, our key contributions are: (1) A dynamic frame rate scheduler for DiT video generation that adaptively assigns frame rates for video segments. (2) A novel latent-space frame merging method to align latent representations with their denoised counterparts before merging those redundant in low-resolution space. (3) A preference analysis of Rotary Positional Embeddings (RoPE) across DiT layers, informing a tailored RoPE strategy optimized for semantic and local information capture. Experiments show that VGDFR can achieve a speedup up to 3x for video generation with minimal quality degradation.
DiTFastAttnV2: Head-wise Attention Compression for Multi-Modality Diffusion Transformers
Mar 28, 2025



Text-to-image generation models, especially Multimodal Diffusion Transformers (MMDiT), have shown remarkable progress in generating high-quality images. However, these models often face significant computational bottlenecks, particularly in attention mechanisms, which hinder their scalability and efficiency. In this paper, we introduce DiTFastAttnV2, a post-training compression method designed to accelerate attention in MMDiT. Through an in-depth analysis of MMDiT's attention patterns, we identify key differences from prior DiT-based methods and propose head-wise arrow attention and caching mechanisms to dynamically adjust attention heads, effectively bridging this gap. We also design an Efficient Fused Kernel for further acceleration. By leveraging local metric methods and optimization techniques, our approach significantly reduces the search time for optimal compression schemes to just minutes while maintaining generation quality. Furthermore, with the customized kernel, DiTFastAttnV2 achieves a 68% reduction in attention FLOPs and 1.5x end-to-end speedup on 2K image generation without compromising visual fidelity.
DLFR-VAE: Dynamic Latent Frame Rate VAE for Video Generation
Feb 17, 2025
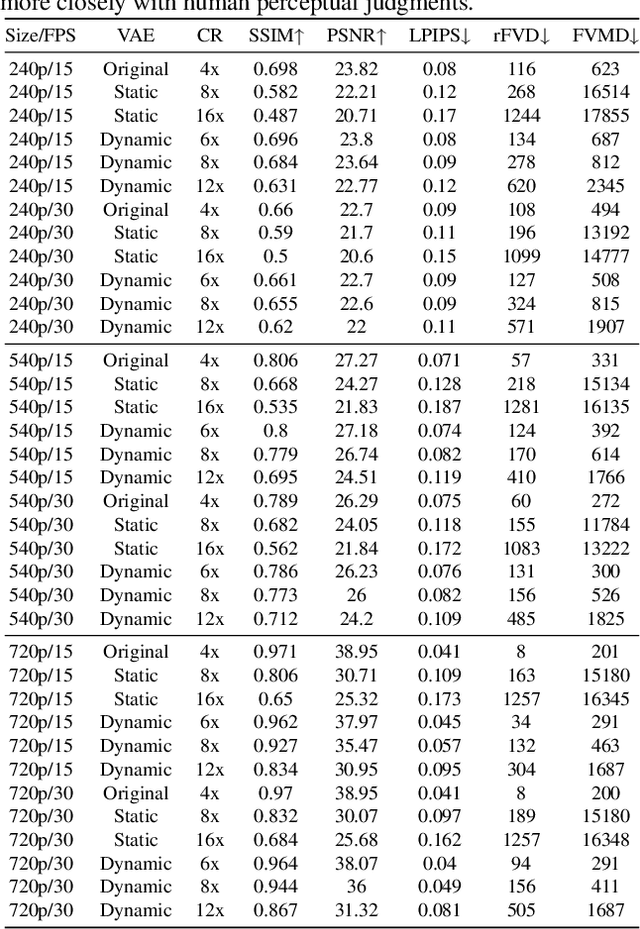

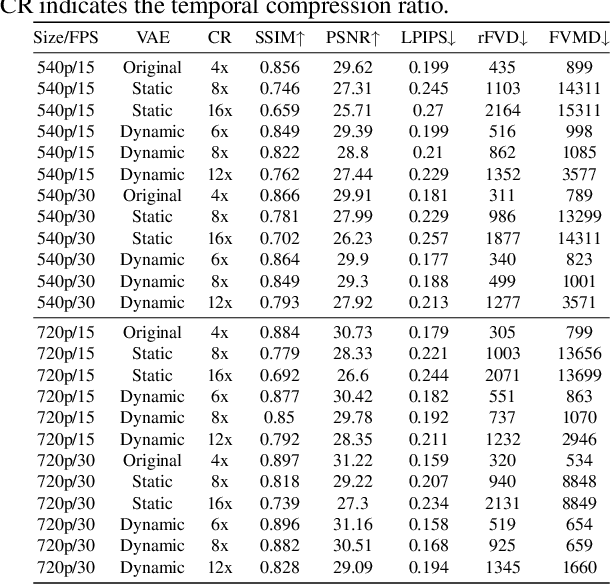
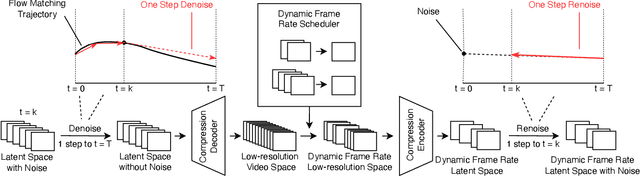
In this paper, we propose the Dynamic Latent Frame Rate VAE (DLFR-VAE), a training-free paradigm that can make use of adaptive temporal compression in latent space. While existing video generative models apply fixed compression rates via pretrained VAE, we observe that real-world video content exhibits substantial temporal non-uniformity, with high-motion segments containing more information than static scenes. Based on this insight, DLFR-VAE dynamically adjusts the latent frame rate according to the content complexity. Specifically, DLFR-VAE comprises two core innovations: (1) A Dynamic Latent Frame Rate Scheduler that partitions videos into temporal chunks and adaptively determines optimal frame rates based on information-theoretic content complexity, and (2) A training-free adaptation mechanism that transforms pretrained VAE architectures into a dynamic VAE that can process features with variable frame rates. Our simple but effective DLFR-VAE can function as a plug-and-play module, seamlessly integrating with existing video generation models and accelerating the video generation process.
E-CAR: Efficient Continuous Autoregressive Image Generation via Multistage Modeling
Dec 19, 2024



Recent advances in autoregressive (AR) models with continuous tokens for image generation show promising results by eliminating the need for discrete tokenization. However, these models face efficiency challenges due to their sequential token generation nature and reliance on computationally intensive diffusion-based sampling. We present ECAR (Efficient Continuous Auto-Regressive Image Generation via Multistage Modeling), an approach that addresses these limitations through two intertwined innovations: (1) a stage-wise continuous token generation strategy that reduces computational complexity and provides progressively refined token maps as hierarchical conditions, and (2) a multistage flow-based distribution modeling method that transforms only partial-denoised distributions at each stage comparing to complete denoising in normal diffusion models. Holistically, ECAR operates by generating tokens at increasing resolutions while simultaneously denoising the image at each stage. This design not only reduces token-to-image transformation cost by a factor of the stage number but also enables parallel processing at the token level. Our approach not only enhances computational efficiency but also aligns naturally with image generation principles by operating in continuous token space and following a hierarchical generation process from coarse to fine details. Experimental results demonstrate that ECAR achieves comparable image quality to DiT Peebles & Xie [2023] while requiring 10$\times$ FLOPs reduction and 5$\times$ speedup to generate a 256$\times$256 image.
DiTFastAttn: Attention Compression for Diffusion Transformer Models
Jun 12, 2024
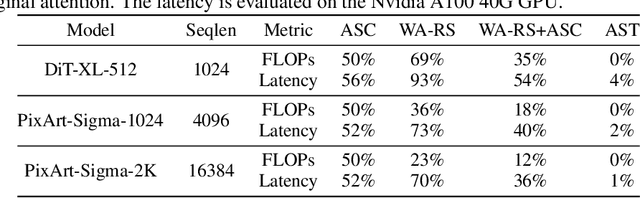
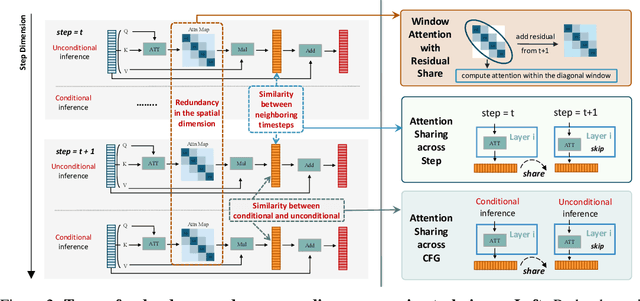
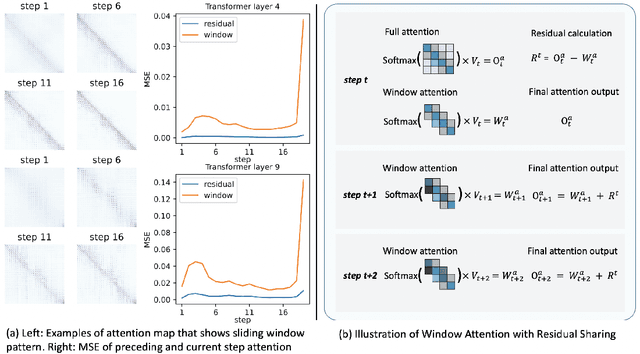
Diffusion Transformers (DiT) excel at image and video generation but face computational challenges due to self-attention's quadratic complexity. We propose DiTFastAttn, a novel post-training compression method to alleviate DiT's computational bottleneck. We identify three key redundancies in the attention computation during DiT inference: 1. spatial redundancy, where many attention heads focus on local information; 2. temporal redundancy, with high similarity between neighboring steps' attention outputs; 3. conditional redundancy, where conditional and unconditional inferences exhibit significant similarity. To tackle these redundancies, we propose three techniques: 1. Window Attention with Residual Caching to reduce spatial redundancy; 2. Temporal Similarity Reduction to exploit the similarity between steps; 3. Conditional Redundancy Elimination to skip redundant computations during conditional generation. To demonstrate the effectiveness of DiTFastAttn, we apply it to DiT, PixArt-Sigma for image generation tasks, and OpenSora for video generation tasks. Evaluation results show that for image generation, our method reduces up to 88\% of the FLOPs and achieves up to 1.6x speedup at high resolution generation.
TransFGU: A Top-down Approach to Fine-Grained Unsupervised Semantic Segmentation
Dec 02, 2021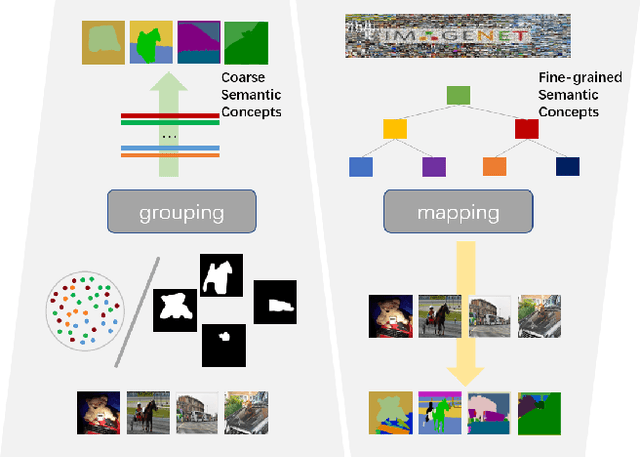
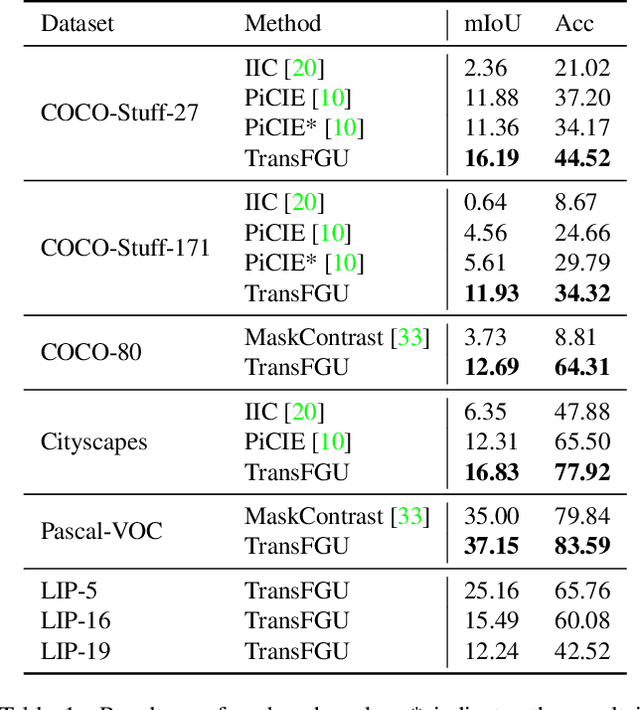
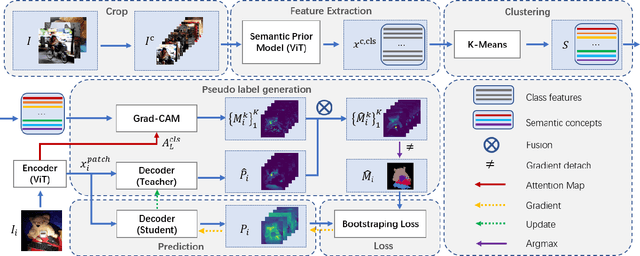
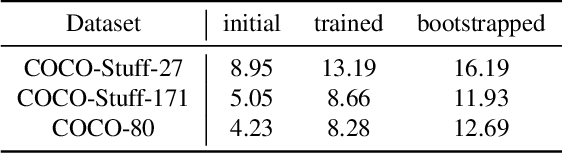
Unsupervised semantic segmentation aims to obtain high-level semantic representation on low-level visual features without manual annotations. Most existing methods are bottom-up approaches that try to group pixels into regions based on their visual cues or certain predefined rules. As a result, it is difficult for these bottom-up approaches to generate fine-grained semantic segmentation when coming to complicated scenes with multiple objects and some objects sharing similar visual appearance. In contrast, we propose the first top-down unsupervised semantic segmentation framework for fine-grained segmentation in extremely complicated scenarios. Specifically, we first obtain rich high-level structured semantic concept information from large-scale vision data in a self-supervised learning manner, and use such information as a prior to discover potential semantic categories presented in target datasets. Secondly, the discovered high-level semantic categories are mapped to low-level pixel features by calculating the class activate map (CAM) with respect to certain discovered semantic representation. Lastly, the obtained CAMs serve as pseudo labels to train the segmentation module and produce final semantic segmentation. Experimental results on multiple semantic segmentation benchmarks show that our top-down unsupervised segmentation is robust to both object-centric and scene-centric datasets under different semantic granularity levels, and outperforms all the current state-of-the-art bottom-up methods. Our code is available at \url{https://github.com/damo-cv/TransFGU}.
Learning to Recommend Frame for Interactive Video Object Segmentation in the Wild
Mar 18, 2021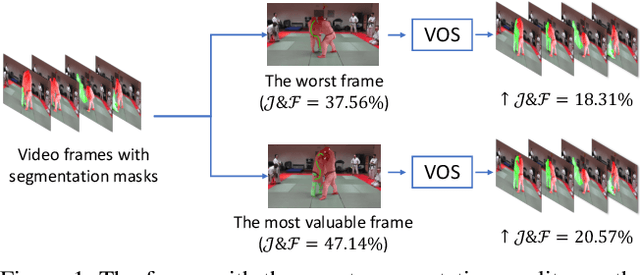

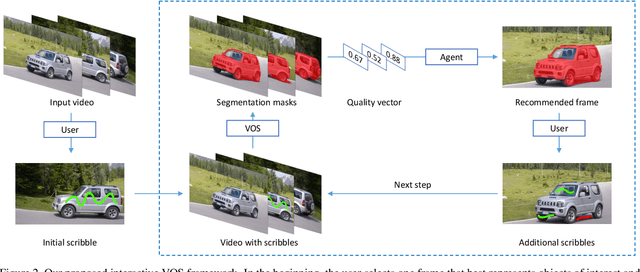
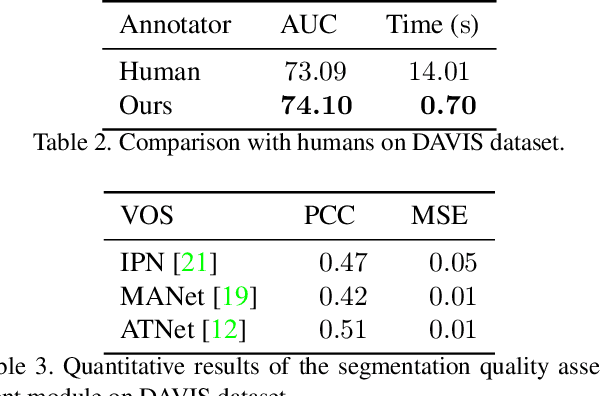
This paper proposes a framework for the interactive video object segmentation (VOS) in the wild where users can choose some frames for annotations iteratively. Then, based on the user annotations, a segmentation algorithm refines the masks. The previous interactive VOS paradigm selects the frame with some worst evaluation metric, and the ground truth is required for calculating the evaluation metric, which is impractical in the testing phase. In contrast, in this paper, we advocate that the frame with the worst evaluation metric may not be exactly the most valuable frame that leads to the most performance improvement across the video. Thus, we formulate the frame selection problem in the interactive VOS as a Markov Decision Process, where an agent is learned to recommend the frame under a deep reinforcement learning framework. The learned agent can automatically determine the most valuable frame, making the interactive setting more practical in the wild. Experimental results on the public datasets show the effectiveness of our learned agent without any changes to the underlying VOS algorithms. Our data, code, and models are available at https://github.com/svip-lab/IVOS-W.