 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks
Mar 30, 2023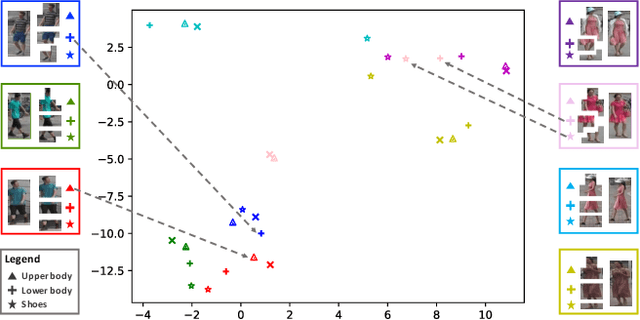
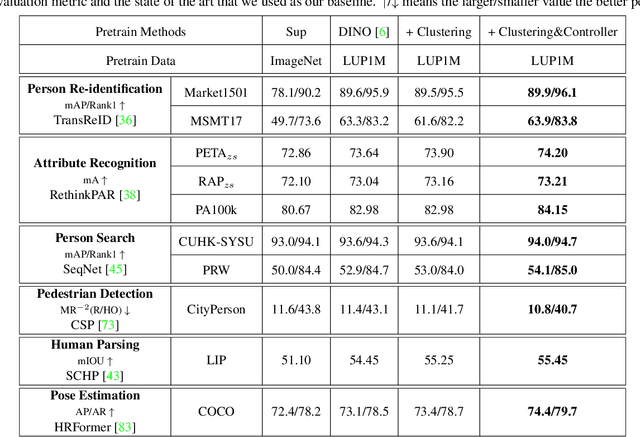
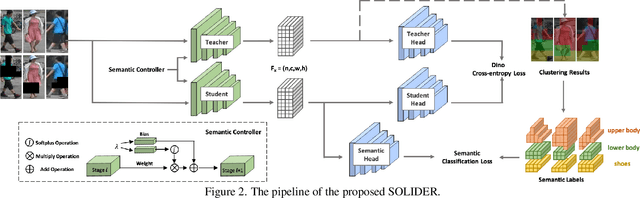
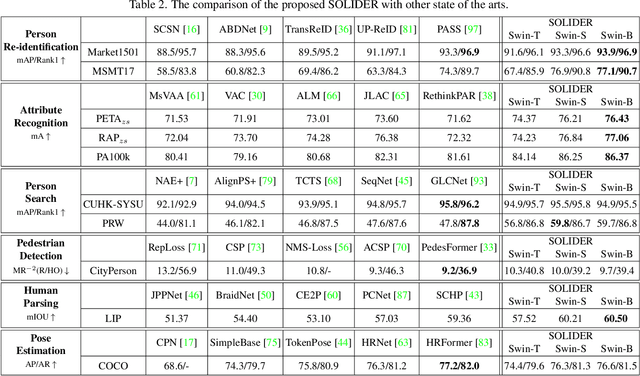
Human-centric visual tasks have attracted increasing research attention due to their widespread applications. In this paper, we aim to learn a general human representation from massive unlabeled human images which can benefit downstream human-centric tasks to the maximum extent. We call this method SOLIDER, a Semantic cOntrollable seLf-supervIseD lEaRning framework. Unlike the existing self-supervised learning methods, prior knowledge from human images is utilized in SOLIDER to build pseudo semantic labels and import more semantic information into the learned representation. Meanwhile, we note that different downstream tasks always require different ratios of semantic information and appearance information. For example, human parsing requires more semantic information, while person re-identification needs more appearance information for identification purpose. So a single learned representation cannot fit for all requirements. To solve this problem, SOLIDER introduces a conditional network with a semantic controller. After the model is trained, users can send values to the controller to produce representations with different ratios of semantic information, which can fit different needs of downstream tasks. Finally, SOLIDER is verified on six downstream human-centric visual tasks. It outperforms state of the arts and builds new baselines for these tasks. The code is released in https://github.com/tinyvision/SOLIDER.
DAMO-YOLO : A Report on Real-Time Object Detection Design
Dec 15, 2022



In this report, we present a fast and accurate object detection method dubbed DAMO-YOLO, which achieves higher performance than the state-of-the-art YOLO series. DAMO-YOLO is extended from YOLO with some new technologies, including Neural Architecture Search (NAS), efficient Reparameterized Generalized-FPN (RepGFPN), a lightweight head with AlignedOTA label assignment, and distillation enhancement. In particular, we use MAE-NAS, a method guided by the principle of maximum entropy, to search our detection backbone under the constraints of low latency and high performance, producing ResNet-like / CSP-like structures with spatial pyramid pooling and focus modules. In the design of necks and heads, we follow the rule of "large neck, small head". We import Generalized-FPN with accelerated queen-fusion to build the detector neck and upgrade its CSPNet with efficient layer aggregation networks (ELAN) and reparameterization. Then we investigate how detector head size affects detection performance and find that a heavy neck with only one task projection layer would yield better results. In addition, AlignedOTA is proposed to solve the misalignment problem in label assignment. And a distillation schema is introduced to improve performance to a higher level. Based on these new techs, we build a suite of models at various scales to meet the needs of different scenarios, i.e., DAMO-YOLO-Tiny/Small/Medium. They can achieve 43.0/46.8/50.0 mAPs on COCO with the latency of 2.78/3.83/5.62 ms on T4 GPUs respectively. The code is available at https://github.com/tinyvision/damo-yolo.
TransFGU: A Top-down Approach to Fine-Grained Unsupervised Semantic Segmentation
Dec 02, 2021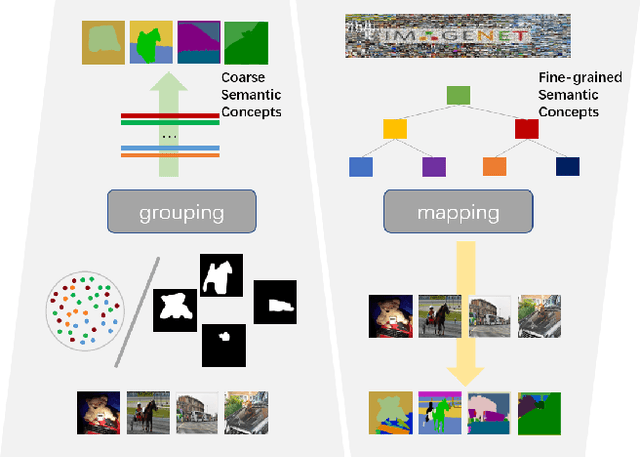
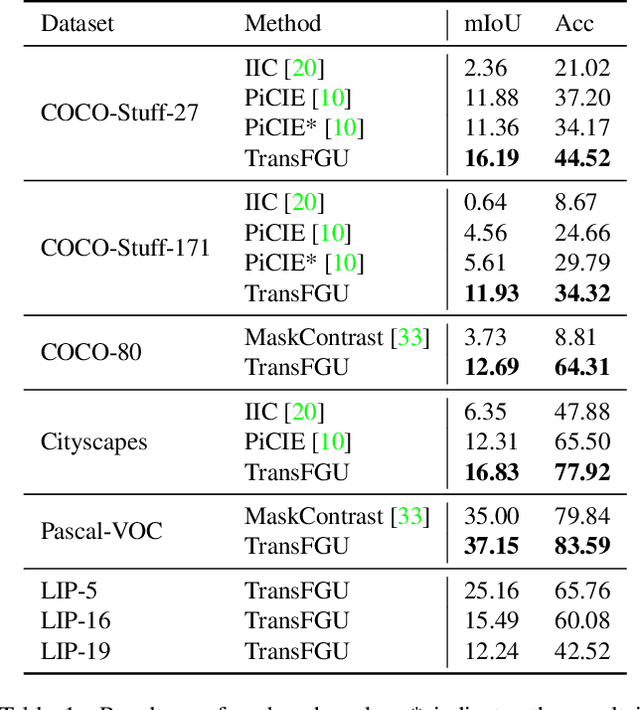
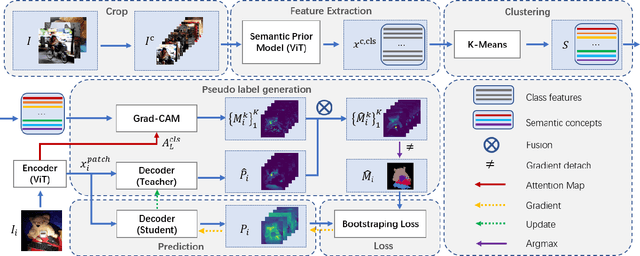
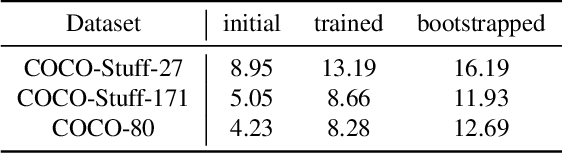
Unsupervised semantic segmentation aims to obtain high-level semantic representation on low-level visual features without manual annotations. Most existing methods are bottom-up approaches that try to group pixels into regions based on their visual cues or certain predefined rules. As a result, it is difficult for these bottom-up approaches to generate fine-grained semantic segmentation when coming to complicated scenes with multiple objects and some objects sharing similar visual appearance. In contrast, we propose the first top-down unsupervised semantic segmentation framework for fine-grained segmentation in extremely complicated scenarios. Specifically, we first obtain rich high-level structured semantic concept information from large-scale vision data in a self-supervised learning manner, and use such information as a prior to discover potential semantic categories presented in target datasets. Secondly, the discovered high-level semantic categories are mapped to low-level pixel features by calculating the class activate map (CAM) with respect to certain discovered semantic representation. Lastly, the obtained CAMs serve as pseudo labels to train the segmentation module and produce final semantic segmentation. Experimental results on multiple semantic segmentation benchmarks show that our top-down unsupervised segmentation is robust to both object-centric and scene-centric datasets under different semantic granularity levels, and outperforms all the current state-of-the-art bottom-up methods. Our code is available at \url{https://github.com/damo-cv/TransFGU}.
Achieving Human Parity on Visual Question Answering
Nov 19, 2021
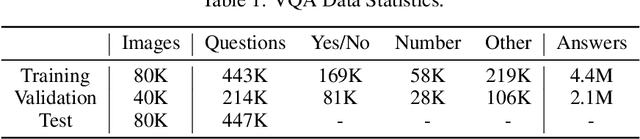
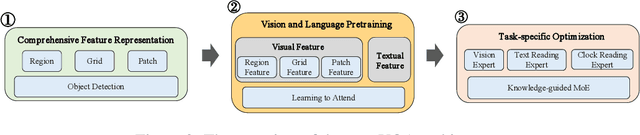
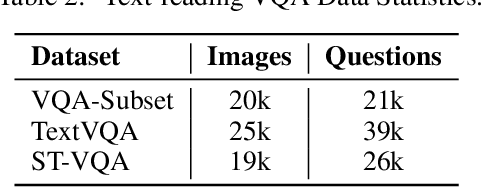
The Visual Question Answering (VQA) task utilizes both visual image and language analysis to answer a textual question with respect to an image. It has been a popular research topic with an increasing number of real-world applications in the last decade. This paper describes our recent research of AliceMind-MMU (ALIbaba's Collection of Encoder-decoders from Machine IntelligeNce lab of Damo academy - MultiMedia Understanding) that obtains similar or even slightly better results than human being does on VQA. This is achieved by systematically improving the VQA pipeline including: (1) pre-training with comprehensive visual and textual feature representation; (2) effective cross-modal interaction with learning to attend; and (3) A novel knowledge mining framework with specialized expert modules for the complex VQA task. Treating different types of visual questions with corresponding expertise needed plays an important role in boosting the performance of our VQA architecture up to the human level. An extensive set of experiments and analysis are conducted to demonstrate the effectiveness of the new research work.
An Empirical Study of Vehicle Re-Identification on the AI City Challenge
May 20, 2021
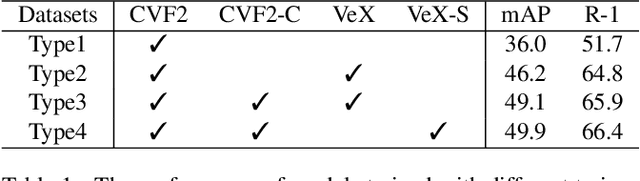
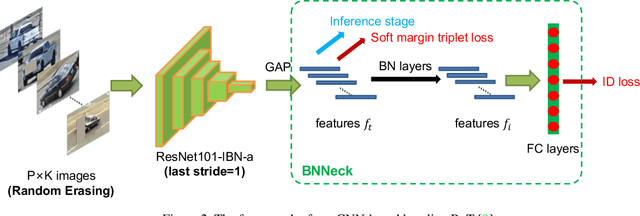

This paper introduces our solution for the Track2 in AI City Challenge 2021 (AICITY21). The Track2 is a vehicle re-identification (ReID) task with both the real-world data and synthetic data. We mainly focus on four points, i.e. training data, unsupervised domain-adaptive (UDA) training, post-processing, model ensembling in this challenge. (1) Both cropping training data and using synthetic data can help the model learn more discriminative features. (2) Since there is a new scenario in the test set that dose not appear in the training set, UDA methods perform well in the challenge. (3) Post-processing techniques including re-ranking, image-to-track retrieval, inter-camera fusion, etc, significantly improve final performance. (4) We ensemble CNN-based models and transformer-based models which provide different representation diversity. With aforementioned techniques, our method finally achieves 0.7445 mAP score, yielding the first place in the competition. Codes are available at https://github.com/michuanhaohao/AICITY2021_Track2_DMT.
City-Scale Multi-Camera Vehicle Tracking Guided by Crossroad Zones
May 14, 2021

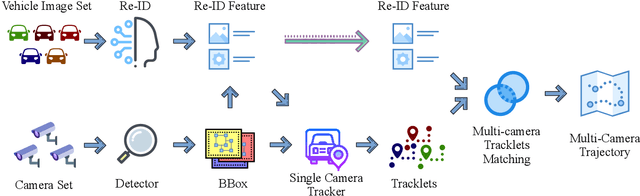

Multi-Target Multi-Camera Tracking has a wide range of applications and is the basis for many advanced inferences and predictions. This paper describes our solution to the Track 3 multi-camera vehicle tracking task in 2021 AI City Challenge (AICITY21). This paper proposes a multi-target multi-camera vehicle tracking framework guided by the crossroad zones. The framework includes: (1) Use mature detection and vehicle re-identification models to extract targets and appearance features. (2) Use modified JDETracker (without detection module) to track single-camera vehicles and generate single-camera tracklets. (3) According to the characteristics of the crossroad, the Tracklet Filter Strategy and the Direction Based Temporal Mask are proposed. (4) Propose Sub-clustering in Adjacent Cameras for multi-camera tracklets matching. Through the above techniques, our method obtained an IDF1 score of 0.8095, ranking first on the leaderboard. The code have released: https://github.com/LCFractal/AIC21-MTMC.