 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity Enhances an LLM's Performance in RAG and Long-context Task
Feb 13, 2025The rapid advancements in large language models (LLMs) have highlighted the challenge of context window limitations, primarily due to the quadratic time complexity of the self-attention mechanism (\(O(N^2)\), where \(N\) denotes the context window length). This constraint impacts tasks such as retrieval-augmented generation (RAG) in question answering (Q\&A) and long context summarization. A common approach involves selecting content with the highest similarity to the query; however, this often leads to redundancy and the exclusion of diverse yet relevant information. Building on principles from Maximal Marginal Relevance (MMR) and Farthest Point Sampling (FPS), we integrate diversity into the content selection process. Our findings reveal that incorporating diversity substantially increases the recall of selecting relevant sentences or chunks before LLM-based Q\&A and summarization. These results highlight the importance of maintaining diversity in future LLM applications to further improve summarization and Q\&A outcomes.
Rate, Explain and Cite (REC): Enhanced Explanation and Attribution in Automatic Evaluation by Large Language Models
Nov 03, 2024



LLMs have demonstrated impressive proficiency in generating coherent and high-quality text, making them valuable across a range of text-generation tasks. However, rigorous evaluation of this generated content is crucial, as ensuring its quality remains a significant challenge due to persistent issues such as factual inaccuracies and hallucinations. This paper introduces two fine-tuned general-purpose LLM autoevaluators, REC-12B and REC-70B, specifically designed to evaluate generated text across several dimensions: faithfulness, instruction following, coherence, and completeness. These models not only provide ratings for these metrics but also offer detailed explanations and verifiable citations, thereby enhancing trust in the content. Moreover, the models support various citation modes, accommodating different requirements for latency and granularity. Extensive evaluations on diverse benchmarks demonstrate that our general-purpose LLM auto-evaluator, REC-70B, outperforms state-of-the-art LLMs, excelling in content evaluation by delivering better quality explanations and citations with minimal bias. It achieves Rank \#1 as a generative model on the RewardBench leaderboard\footnote{\url{https://huggingface.co/spaces/allenai/reward-bench}} under the model name \texttt{TextEval-Llama3.1-70B}. Our REC dataset and models are released at \url{https://github.com/adelaidehsu/REC}.
UFT: Unifying Fine-Tuning of SFT and RLHF/DPO/UNA through a Generalized Implicit Reward Function
Oct 28, 2024
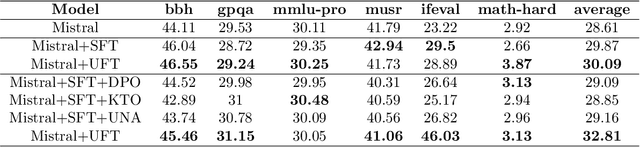
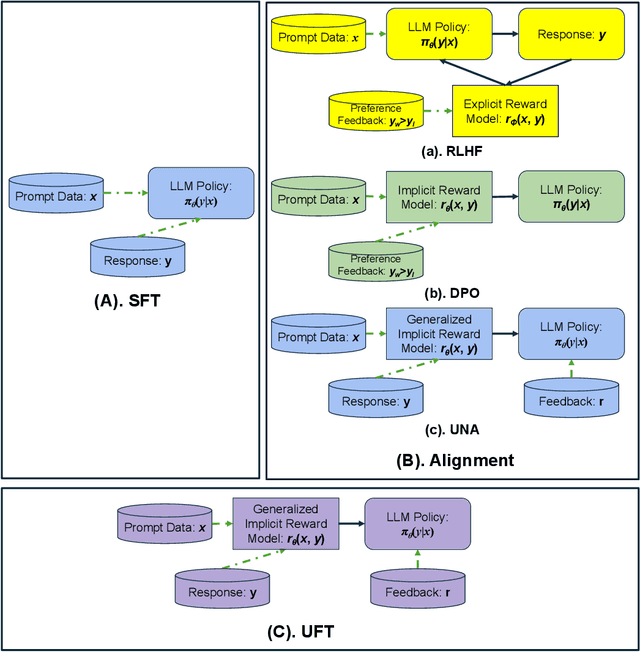

By pretraining on trillions of tokens, an LLM gains the capability of text generation. However, to enhance its utility and reduce potential harm, SFT and alignment are applied sequentially to the pretrained model. Due to the differing nature and objective functions of SFT and alignment, catastrophic forgetting has become a significant issue. To address this, we introduce Unified Fine-Tuning (UFT), which integrates SFT and alignment into a single training stage using the same objective and loss functions through an implicit reward function. Our experimental results demonstrate that UFT outperforms SFT on instruction-tuning data alone. Moreover, when combining instruction-tuning data with alignment data, UFT effectively prevents catastrophic forgetting across these two stages and shows a clear advantage over sequentially applying SFT and alignment. This is evident in the significant improvements observed in the \textbf{ifeval} task for instruction-following and the \textbf{truthful-qa} task for factuality. The proposed general fine-tuning framework UFT establishes an effective and efficient pretraining-UFT paradigm for LLM training.
UNA: Unifying Alignments of RLHF/PPO, DPO and KTO by a Generalized Implicit Reward Function
Aug 27, 2024



An LLM is pretrained on trillions of tokens, but the pretrained LLM may still generate undesired responses. To solve this problem, alignment techniques such as RLHF, DPO and KTO are proposed. However, these alignment techniques have limitations. For example, RLHF requires training the reward model and policy separately, which is complex, time-consuming, memory intensive and unstable during training processes. DPO proposes a mapping between an optimal policy and a reward, greatly simplifying the training process of RLHF. However, it can not take full advantages of a reward model and it is limited to pairwise preference data. In this paper, we propose \textbf{UN}ified \textbf{A}lignment (UNA) which unifies RLHF/PPO, DPO and KTO. Firstly, we mathematically prove that given the classical RLHF objective, the optimal policy is induced by a generalize implicit reward function. With this novel mapping between a reward model and an optimal policy, UNA can 1. unify RLHF/PPO, DPO and KTO into a supervised learning of minimizing the difference between an implicit reward and an explicit reward; 2. outperform RLHF/PPO while simplify, stabilize, speed up and reduce memory burden of RL fine-tuning process; 3. accommodate different feedback types including pairwise, binary and scalar feedback. Downstream experiments show UNA outperforms DPO, KTO and RLHF.
A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More
Jul 23, 2024



With advancements in self-supervised learning, the availability of trillions tokens in a pre-training corpus, instruction fine-tuning, and the development of large Transformers with billions of parameters, large language models (LLMs) are now capable of generating factual and coherent responses to human queries. However, the mixed quality of training data can lead to the generation of undesired responses, presenting a significant challenge. Over the past two years, various methods have been proposed from different perspectives to enhance LLMs, particularly in aligning them with human expectation. Despite these efforts, there has not been a comprehensive survey paper that categorizes and details these approaches. In this work, we aim to address this gap by categorizing these papers into distinct topics and providing detailed explanations of each alignment method, thereby helping readers gain a thorough understanding of the current state of the field.
PAFT: A Parallel Training Paradigm for Effective LLM Fine-Tuning
Jun 25, 2024



Large language models (LLMs) have shown remarkable abilities in diverse natural language processing (NLP) tasks. The LLMs generally undergo supervised fine-tuning (SFT) followed by preference alignment to be usable in downstream applications. However, this sequential training pipeline leads to alignment tax that degrades the LLM performance. This paper introduces PAFT, a new PArallel training paradigm for effective LLM Fine-Tuning, which independently performs SFT and preference alignment (e.g., DPO and ORPO, etc.) with the same pre-trained model on respective datasets. The model produced by SFT and the model from preference alignment are then merged into a final model by parameter fusing for use in downstream applications. This work reveals important findings that preference alignment like DPO naturally results in a sparse model while SFT leads to a natural dense model which needs to be sparsified for effective model merging. This paper introduces an effective interference resolution which reduces the redundancy by sparsifying the delta parameters. The LLM resulted from the new training paradigm achieved Rank #1 on the HuggingFace Open LLM Leaderboard. Comprehensive evaluation shows the effectiveness of the parallel training paradigm.
BUS:Efficient and Effective Vision-language Pre-training with Bottom-Up Patch Summarization
Jul 17, 2023Vision Transformer (ViT) based Vision-Language Pre-training (VLP) models have demonstrated impressive performance in various tasks. However, the lengthy visual token sequences fed into ViT can lead to training inefficiency and ineffectiveness. Existing efforts address the challenge by either bottom-level patch extraction in the ViT backbone or top-level patch abstraction outside, not balancing training efficiency and effectiveness well. Inspired by text summarization in natural language processing, we propose a Bottom-Up Patch Summarization approach named BUS, coordinating bottom-level extraction and top-level abstraction to learn a concise summary of lengthy visual token sequences efficiently. Specifically, We incorporate a Text-Semantics-Aware Patch Selector (TSPS) into the ViT backbone to perform a coarse-grained visual token extraction and then attach a flexible Transformer-based Patch Abstraction Decoder (PAD) upon the backbone for top-level visual abstraction. This bottom-up collaboration enables our BUS to yield high training efficiency while maintaining or even improving effectiveness. We evaluate our approach on various visual-language understanding and generation tasks and show competitive downstream task performance while boosting the training efficiency by 50\%. Additionally, our model achieves state-of-the-art performance on many downstream tasks by increasing input image resolution without increasing computational costs over baselines.
mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video
Feb 01, 2023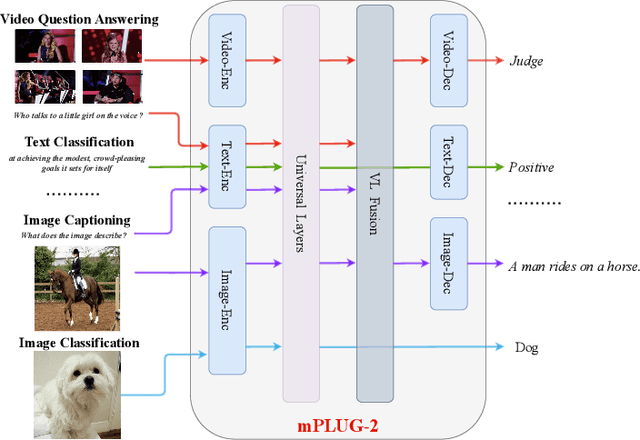
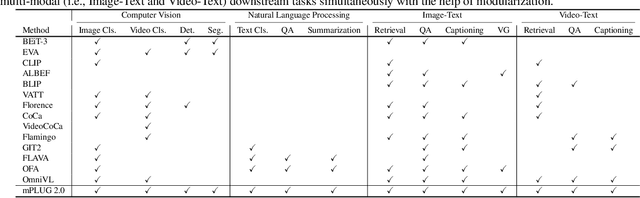
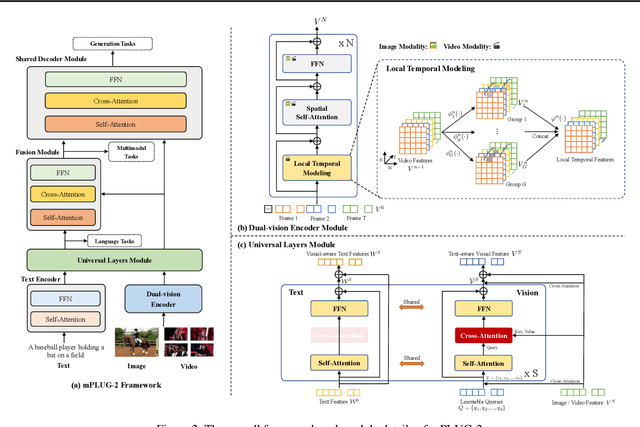

Recent years have witnessed a big convergence of language, vision, and multi-modal pretraining. In this work, we present mPLUG-2, a new unified paradigm with modularized design for multi-modal pretraining, which can benefit from modality collaboration while addressing the problem of modality entanglement. In contrast to predominant paradigms of solely relying on sequence-to-sequence generation or encoder-based instance discrimination, mPLUG-2 introduces a multi-module composition network by sharing common universal modules for modality collaboration and disentangling different modality modules to deal with modality entanglement. It is flexible to select different modules for different understanding and generation tasks across all modalities including text, image, and video. Empirical study shows that mPLUG-2 achieves state-of-the-art or competitive results on a broad range of over 30 downstream tasks, spanning multi-modal tasks of image-text and video-text understanding and generation, and uni-modal tasks of text-only, image-only, and video-only understanding. Notably, mPLUG-2 shows new state-of-the-art results of 48.0 top-1 accuracy and 80.3 CIDEr on the challenging MSRVTT video QA and video caption tasks with a far smaller model size and data scale. It also demonstrates strong zero-shot transferability on vision-language and video-language tasks. Code and models will be released in https://github.com/alibaba/AliceMind.
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
May 25, 2022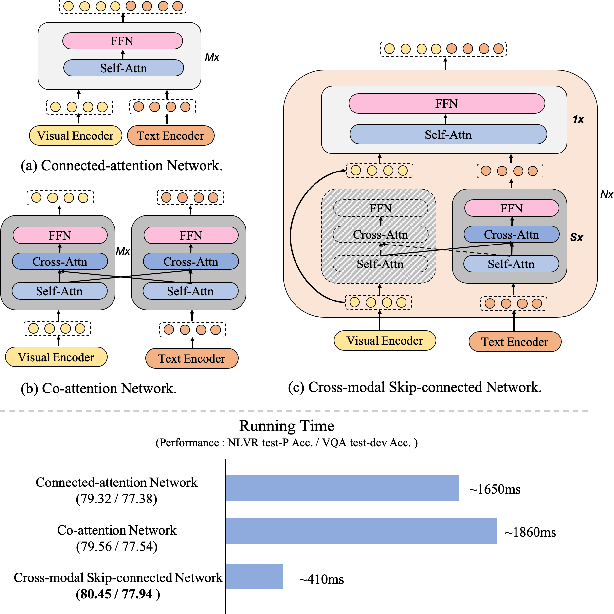
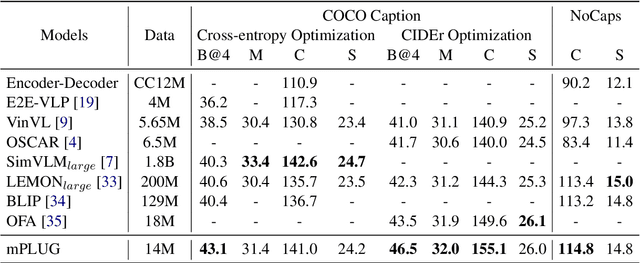
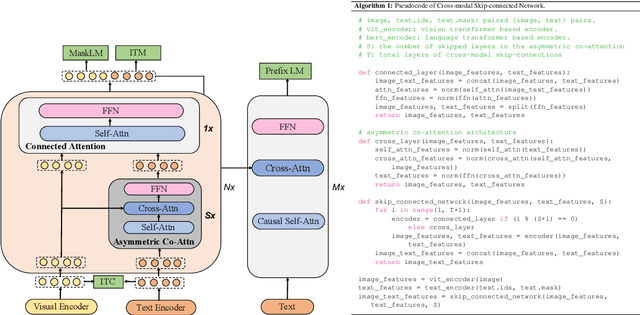

Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
Achieving Human Parity on Visual Question Answering
Nov 19, 2021
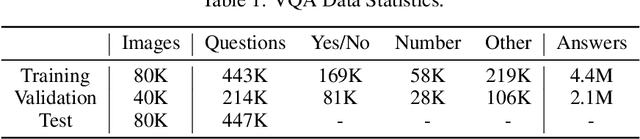
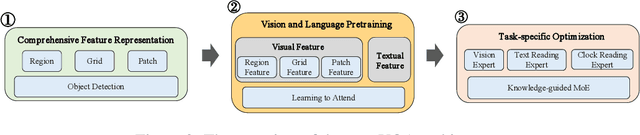
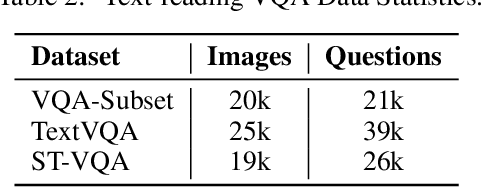
The Visual Question Answering (VQA) task utilizes both visual image and language analysis to answer a textual question with respect to an image. It has been a popular research topic with an increasing number of real-world applications in the last decade. This paper describes our recent research of AliceMind-MMU (ALIbaba's Collection of Encoder-decoders from Machine IntelligeNce lab of Damo academy - MultiMedia Understanding) that obtains similar or even slightly better results than human being does on VQA. This is achieved by systematically improving the VQA pipeline including: (1) pre-training with comprehensive visual and textual feature representation; (2) effective cross-modal interaction with learning to attend; and (3) A novel knowledge mining framework with specialized expert modules for the complex VQA task. Treating different types of visual questions with corresponding expertise needed plays an important role in boosting the performance of our VQA architecture up to the human level. An extensive set of experiments and analysis are conducted to demonstrate the effectiveness of the new research work.