 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpusQA: A 10 Million Token Benchmark for Corpus-Level Analysis and Reasoning
Jan 21, 2026While large language models now handle million-token contexts, their capacity for reasoning across entire document repositories remains largely untested. Existing benchmarks are inadequate, as they are mostly limited to single long texts or rely on a "sparse retrieval" assumption-that answers can be derived from a few relevant chunks. This assumption fails for true corpus-level analysis, where evidence is highly dispersed across hundreds of documents and answers require global integration, comparison, and statistical aggregation. To address this critical gap, we introduce CorpusQA, a new benchmark scaling up to 10 million tokens, generated via a novel data synthesis framework. By decoupling reasoning from textual representation, this framework creates complex, computation-intensive queries with programmatically guaranteed ground-truth answers, challenging systems to perform holistic reasoning over vast, unstructured text without relying on fallible human annotation. We further demonstrate the utility of our framework beyond evaluation, showing that fine-tuning on our synthesized data effectively enhances an LLM's general long-context reasoning capabilities. Extensive experiments reveal that even state-of-the-art long-context LLMs struggle as input length increases, and standard retrieval-augmented generation systems collapse entirely. Our findings indicate that memory-augmented agentic architectures offer a more robust alternative, suggesting a critical shift is needed from simply extending context windows to developing advanced architectures for global information synthesis.
Incentivizing In-depth Reasoning over Long Contexts with Process Advantage Shaping
Jan 18, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective in enhancing LLMs short-context reasoning, but its performance degrades in long-context scenarios that require both precise grounding and robust long-range reasoning. We identify the "almost-there" phenomenon in long-context reasoning, where trajectories are largely correct but fail at the final step, and attribute this failure to two factors: (1) the lack of high reasoning density in long-context QA data that push LLMs beyond mere grounding toward sophisticated multi-hop reasoning; and (2) the loss of valuable learning signals during long-context RL training due to the indiscriminate penalization of partially correct trajectories with incorrect outcomes. To overcome this bottleneck, we propose DeepReasonQA, a KG-driven synthesis framework that controllably constructs high-difficulty, multi-hop long-context QA pairs with inherent reasoning chains. Building on this, we introduce Long-context Process Advantage Shaping (LongPAS), a simple yet effective method that performs fine-grained credit assignment by evaluating reasoning steps along Validity and Relevance dimensions, which captures critical learning signals from "almost-there" trajectories. Experiments on three long-context reasoning benchmarks show that our approach substantially outperforms RLVR baselines and matches frontier LLMs while using far fewer parameters. Further analysis confirms the effectiveness of our methods in strengthening long-context reasoning while maintaining stable RL training.
Q-Regularized Generative Auto-Bidding: From Suboptimal Trajectories to Optimal Policies
Jan 06, 2026With the rapid development of e-commerce, auto-bidding has become a key asset in optimizing advertising performance under diverse advertiser environments. The current approaches focus on reinforcement learning (RL) and generative models. These efforts imitate offline historical behaviors by utilizing a complex structure with expensive hyperparameter tuning. The suboptimal trajectories further exacerbate the difficulty of policy learning. To address these challenges, we proposes QGA, a novel Q-value regularized Generative Auto-bidding method. In QGA, we propose to plug a Q-value regularization with double Q-learning strategy into the Decision Transformer backbone. This design enables joint optimization of policy imitation and action-value maximization, allowing the learned bidding policy to both leverage experience from the dataset and alleviate the adverse impact of the suboptimal trajectories. Furthermore, to safely explore the policy space beyond the data distribution, we propose a Q-value guided dual-exploration mechanism, in which the DT model is conditioned on multiple return-to-go targets and locally perturbed actions. This entire exploration process is dynamically guided by the aforementioned Q-value module, which provides principled evaluation for each candidate action. Experiments on public benchmarks and simulation environments demonstrate that QGA consistently achieves superior or highly competitive results compared to existing alternatives. Notably, in large-scale real-world A/B testing, QGA achieves a 3.27% increase in Ad GMV and a 2.49% improvement in Ad ROI.
QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
Dec 15, 2025We introduce QwenLong-L1.5, a model that achieves superior long-context reasoning capabilities through systematic post-training innovations. The key technical breakthroughs of QwenLong-L1.5 are as follows: (1) Long-Context Data Synthesis Pipeline: We develop a systematic synthesis framework that generates challenging reasoning tasks requiring multi-hop grounding over globally distributed evidence. By deconstructing documents into atomic facts and their underlying relationships, and then programmatically composing verifiable reasoning questions, our approach creates high-quality training data at scale, moving substantially beyond simple retrieval tasks to enable genuine long-range reasoning capabilities. (2) Stabilized Reinforcement Learning for Long-Context Training: To overcome the critical instability in long-context RL, we introduce task-balanced sampling with task-specific advantage estimation to mitigate reward bias, and propose Adaptive Entropy-Controlled Policy Optimization (AEPO) that dynamically regulates exploration-exploitation trade-offs. (3) Memory-Augmented Architecture for Ultra-Long Contexts: Recognizing that even extended context windows cannot accommodate arbitrarily long sequences, we develop a memory management framework with multi-stage fusion RL training that seamlessly integrates single-pass reasoning with iterative memory-based processing for tasks exceeding 4M tokens. Based on Qwen3-30B-A3B-Thinking, QwenLong-L1.5 achieves performance comparable to GPT-5 and Gemini-2.5-Pro on long-context reasoning benchmarks, surpassing its baseline by 9.90 points on average. On ultra-long tasks (1M~4M tokens), QwenLong-L1.5's memory-agent framework yields a 9.48-point gain over the agent baseline. Additionally, the acquired long-context reasoning ability translates to enhanced performance in general domains like scientific reasoning, memory tool using, and extended dialogue.
LFD: Layer Fused Decoding to Exploit External Knowledge in Retrieval-Augmented Generation
Aug 27, 2025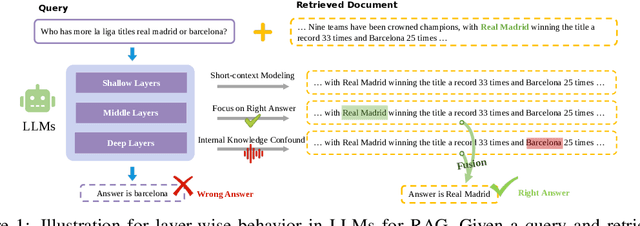
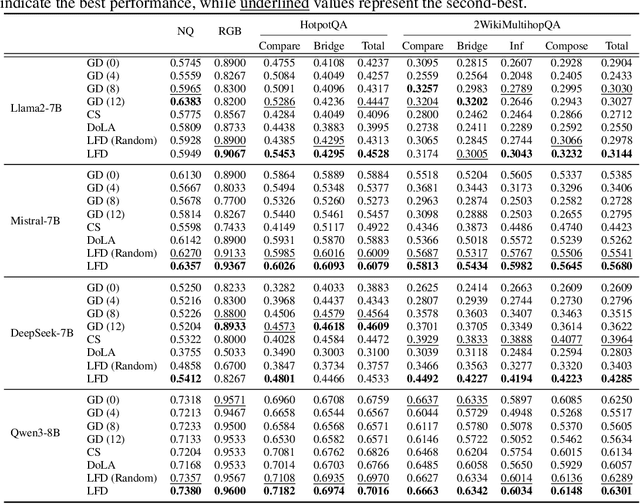
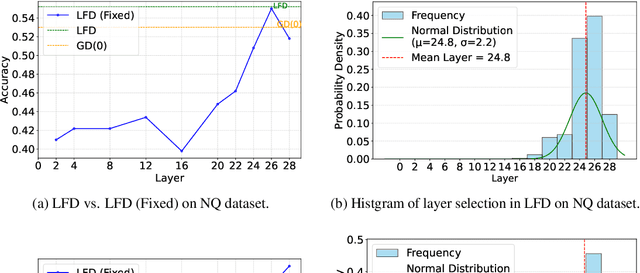

Retrieval-augmented generation (RAG) incorporates external knowledge into large language models (LLMs), improving their adaptability to downstream tasks and enabling information updates. Surprisingly, recent empirical evidence demonstrates that injecting noise into retrieved relevant documents paradoxically facilitates exploitation of external knowledge and improves generation quality. Although counterintuitive and challenging to apply in practice, this phenomenon enables granular control and rigorous analysis of how LLMs integrate external knowledge. Therefore, in this paper, we intervene on noise injection and establish a layer-specific functional demarcation within the LLM: shallow layers specialize in local context modeling, intermediate layers focus on integrating long-range external factual knowledge, and deeper layers primarily rely on parametric internal knowledge. Building on this insight, we propose Layer Fused Decoding (LFD), a simple decoding strategy that directly combines representations from an intermediate layer with final-layer decoding outputs to fully exploit the external factual knowledge. To identify the optimal intermediate layer, we introduce an internal knowledge score (IKS) criterion that selects the layer with the lowest IKS value in the latter half of layers. Experimental results across multiple benchmarks demonstrate that LFD helps RAG systems more effectively surface retrieved context knowledge with minimal cost.
Multi-Interest Recommendation: A Survey
Jun 18, 2025Existing recommendation methods often struggle to model users' multifaceted preferences due to the diversity and volatility of user behavior, as well as the inherent uncertainty and ambiguity of item attributes in practical scenarios. Multi-interest recommendation addresses this challenge by extracting multiple interest representations from users' historical interactions, enabling fine-grained preference modeling and more accurate recommendations. It has drawn broad interest in recommendation research. However, current recommendation surveys have either specialized in frontier recommendation methods or delved into specific tasks and downstream applications. In this work, we systematically review the progress, solutions, challenges, and future directions of multi-interest recommendation by answering the following three questions: (1) Why is multi-interest modeling significantly important for recommendation? (2) What aspects are focused on by multi-interest modeling in recommendation? and (3) How can multi-interest modeling be applied, along with the technical details of the representative modules? We hope that this survey establishes a fundamental framework and delivers a preliminary overview for researchers interested in this field and committed to further exploration. The implementation of multi-interest recommendation summarized in this survey is maintained at https://github.com/WHUIR/Multi-Interest-Recommendation-A-Survey.
Writing-RL: Advancing Long-form Writing via Adaptive Curriculum Reinforcement Learning
Jun 06, 2025Recent advances in Large Language Models (LLMs) have enabled strong performance in long-form writing, yet existing supervised fine-tuning (SFT) approaches suffer from limitations such as data saturation and restricted learning capacity bounded by teacher signals. In this work, we present Writing-RL: an Adaptive Curriculum Reinforcement Learning framework to advance long-form writing capabilities beyond SFT. The framework consists of three key components: Margin-aware Data Selection strategy that prioritizes samples with high learning potential, Pairwise Comparison Reward mechanism that provides discriminative learning signals in the absence of verifiable rewards, and Dynamic Reference Scheduling approach, which plays a particularly critical role by adaptively adjusting task difficulty based on evolving model performance. Experiments on 7B-scale writer models show that our RL framework largely improves long-form writing performance over strong SFT baselines. Furthermore, we observe that models trained with long-output RL generalize surprisingly well to long-input reasoning tasks, potentially offering a promising perspective for rethinking long-context training.
MUSEG: Reinforcing Video Temporal Understanding via Timestamp-Aware Multi-Segment Grounding
May 27, 2025Video temporal understanding is crucial for multimodal large language models (MLLMs) to reason over events in videos. Despite recent advances in general video understanding, current MLLMs still struggle with fine-grained temporal reasoning. While reinforcement learning (RL) has been explored to address this issue recently, existing RL approaches remain limited in effectiveness. In this work, we propose MUSEG, a novel RL-based method that enhances temporal understanding by introducing timestamp-aware multi-segment grounding. MUSEG enables MLLMs to align queries with multiple relevant video segments, promoting more comprehensive temporal reasoning. To facilitate effective learning, we design a customized RL training recipe with phased rewards that progressively guides the model toward temporally grounded reasoning. Extensive experiments on temporal grounding and time-sensitive video QA tasks demonstrate that MUSEG significantly outperforms existing methods and generalizes well across diverse temporal understanding scenarios. View our project at https://github.com/THUNLP-MT/MUSEG.
QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
May 23, 2025Recent large reasoning models (LRMs) have demonstrated strong reasoning capabilities through reinforcement learning (RL). These improvements have primarily been observed within the short-context reasoning tasks. In contrast, extending LRMs to effectively process and reason on long-context inputs via RL remains a critical unsolved challenge. To bridge this gap, we first formalize the paradigm of long-context reasoning RL, and identify key challenges in suboptimal training efficiency and unstable optimization process. To address these issues, we propose QwenLong-L1, a framework that adapts short-context LRMs to long-context scenarios via progressive context scaling. Specifically, we utilize a warm-up supervised fine-tuning (SFT) stage to establish a robust initial policy, followed by a curriculum-guided phased RL technique to stabilize the policy evolution, and enhanced with a difficulty-aware retrospective sampling strategy to incentivize the policy exploration. Experiments on seven long-context document question-answering benchmarks demonstrate that QwenLong-L1-32B outperforms flagship LRMs like OpenAI-o3-mini and Qwen3-235B-A22B, achieving performance on par with Claude-3.7-Sonnet-Thinking, demonstrating leading performance among state-of-the-art LRMs. This work advances the development of practical long-context LRMs capable of robust reasoning across information-intensive environments.
QwenLong-CPRS: Towards $\infty$-LLMs with Dynamic Context Optimization
May 23, 2025This technical report presents QwenLong-CPRS, a context compression framework designed for explicit long-context optimization, addressing prohibitive computation overhead during the prefill stage and the "lost in the middle" performance degradation of large language models (LLMs) during long sequence processing. Implemented through a novel dynamic context optimization mechanism, QwenLong-CPRS enables multi-granularity context compression guided by natural language instructions, achieving both efficiency gains and improved performance. Evolved from the Qwen architecture series, QwenLong-CPRS introduces four key innovations: (1) Natural language-guided dynamic optimization, (2) Bidirectional reasoning layers for enhanced boundary awareness, (3) Token critic mechanisms with language modeling heads, and (4) Window-parallel inference. Comprehensive evaluations across five benchmarks (4K-2M word contexts) demonstrate QwenLong-CPRS's threefold effectiveness: (1) Consistent superiority over other context management methods like RAG and sparse attention in both accuracy and efficiency. (2) Architecture-agnostic integration with all flagship LLMs, including GPT-4o, Gemini2.0-pro, Claude3.7-sonnet, DeepSeek-v3, and Qwen2.5-max, achieves 21.59$\times$ context compression alongside 19.15-point average performance gains; (3) Deployed with Qwen2.5-32B-Instruct, QwenLong-CPRS surpasses leading proprietary LLMs by 4.85 and 10.88 points on Ruler-128K and InfiniteBench, establishing new SOTA performance.