 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing Implicit Rewards: Prefix-Value Learning for Distribution-Level Optimization
Apr 14, 2026Process reward models (PRMs) provide fine-grained reward signals along the reasoning process, but training reliable PRMs often requires step annotations or heavy verification pipelines, making them expensive to scale and refresh during online RL. Implicit PRMs mitigate this cost by learning decomposable token- or step-level rewards from trajectory-level outcome labels. However, they suffer from a train-inference mismatch: training only constrains a sequence-level aggregate, whereas inference requires token-level scores to reflect local step quality. As a result, token-level credits are weakly identified and may fail to faithfully reflect which reasoning steps are actually correct. This unreliability undermines a key promise of implicit PRMs: scoring many candidate tokens. In practice, noisy per-token advantages may systematically reinforce incorrect continuations. We address this problem with a novel Implicit Prefix-Value Reward Model (IPVRM), which directly learns a prefix-conditioned value function estimating the probability of eventual correctness, and derives step signals via temporal-difference (TD) differences. IPVRM substantially improves step-verification F1 on ProcessBench. Building on these calibrated prefix values, we further propose Distribution-Level RL (DistRL), which computes TD advantages for both sampled tokens and high-probability candidate tokens, enabling dense counterfactual updates without additional rollouts. While DistRL offers limited gains when powered by miscalibrated implicit rewards, it consistently improves downstream reasoning once paired with IPVRM.
Stabilizing Policy Optimization via Logits Convexity
Mar 01, 2026While reinforcement learning (RL) has been central to the recent success of large language models (LLMs), RL optimization is notoriously unstable, especially when compared to supervised fine-tuning (SFT). In this work, we investigate the stability gap between SFT and RL from a gradient-based perspective, and show that the convexity of the SFT loss with respect to model logits plays a key role in enabling stable training. Our theoretical analysis demonstrates that this property induces favorable gradient directionality during optimization. In contrast, Proximal Policy Optimization (PPO), a widely adopted policy gradient algorithm utilizing a clipped surrogate objective, lacks this stabilizing property. Motivated by this observation, we propose Logits Convex Optimization (LCO), a simple yet effective policy optimization framework that aligns the learned policy with an optimal target derived from the original RL objective, thereby emulating the stabilizing effects of logits-level convexity. Extensive experiments across multiple model families show that our LCO framework consistently improves training stability and outperforms conventional RL methods on a broad range of benchmarks.
Discriminative Policy Optimization for Token-Level Reward Models
May 29, 2025Process reward models (PRMs) provide more nuanced supervision compared to outcome reward models (ORMs) for optimizing policy models, positioning them as a promising approach to enhancing the capabilities of LLMs in complex reasoning tasks. Recent efforts have advanced PRMs from step-level to token-level granularity by integrating reward modeling into the training of generative models, with reward scores derived from token generation probabilities. However, the conflict between generative language modeling and reward modeling may introduce instability and lead to inaccurate credit assignments. To address this challenge, we revisit token-level reward assignment by decoupling reward modeling from language generation and derive a token-level reward model through the optimization of a discriminative policy, termed the Q-function Reward Model (Q-RM). We theoretically demonstrate that Q-RM explicitly learns token-level Q-functions from preference data without relying on fine-grained annotations. In our experiments, Q-RM consistently outperforms all baseline methods across various benchmarks. For example, when integrated into PPO/REINFORCE algorithms, Q-RM enhances the average Pass@1 score by 5.85/4.70 points on mathematical reasoning tasks compared to the ORM baseline, and by 4.56/5.73 points compared to the token-level PRM counterpart. Moreover, reinforcement learning with Q-RM significantly enhances training efficiency, achieving convergence 12 times faster than ORM on GSM8K and 11 times faster than step-level PRM on MATH. Code and data are available at https://github.com/homzer/Q-RM.
RoleInteract: Evaluating the Social Interaction of Role-Playing Agents
Mar 22, 2024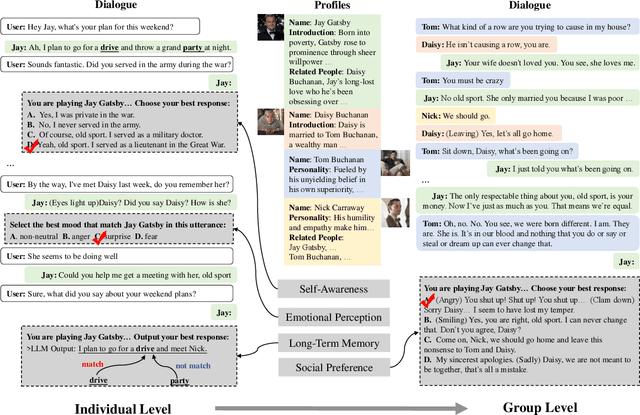
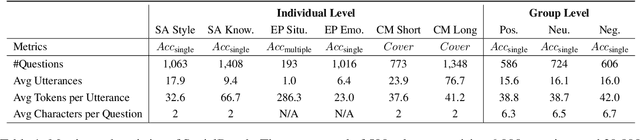
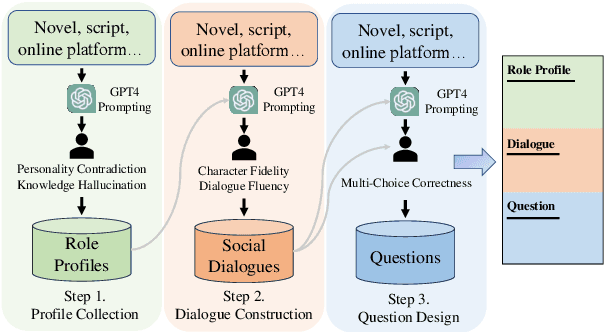
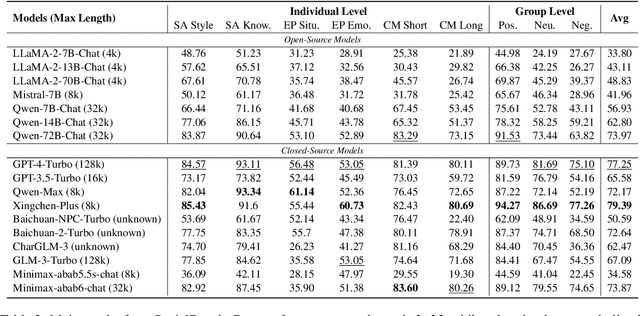
Large language models (LLMs) have advanced the development of various AI conversational agents, including role-playing conversational agents that mimic diverse characters and human behaviors. While prior research has predominantly focused on enhancing the conversational capability, role-specific knowledge, and stylistic attributes of these agents, there has been a noticeable gap in assessing their social intelligence. In this paper, we introduce RoleInteract, the first benchmark designed to systematically evaluate the sociality of role-playing conversational agents at both individual and group levels of social interactions. The benchmark is constructed from a variety of sources and covers a wide range of 500 characters and over 6,000 question prompts and 30,800 multi-turn role-playing utterances. We conduct comprehensive evaluations on this benchmark using mainstream open-source and closed-source LLMs. We find that agents excelling in individual level does not imply their proficiency in group level. Moreover, the behavior of individuals may drift as a result of the influence exerted by other agents within the group. Experimental results on RoleInteract confirm its significance as a testbed for assessing the social interaction of role-playing conversational agents. The benchmark is publicly accessible at https://github.com/X-PLUG/RoleInteract.
Small LLMs Are Weak Tool Learners: A Multi-LLM Agent
Feb 01, 2024



Large Language Model (LLM) agents significantly extend the capabilities of standalone LLMs, empowering them to interact with external tools (e.g., APIs, functions) and complete complex tasks in a self-directed fashion. The challenge of tool use demands that LLMs not only understand user queries and generate answers but also excel in task planning, memory management, tool invocation, and result summarization. While traditional approaches focus on training a single LLM with all these capabilities, performance limitations become apparent, particularly with smaller models. Moreover, the entire LLM may require retraining when tools are updated. To overcome these challenges, we propose a novel strategy that decomposes the aforementioned capabilities into a planner, caller, and summarizer. Each component is implemented by a single LLM that focuses on a specific capability and collaborates with other components to accomplish the task. This modular framework facilitates individual updates and the potential use of smaller LLMs for building each capability. To effectively train this framework, we introduce a two-stage training paradigm. First, we fine-tune a backbone LLM on the entire dataset without discriminating sub-tasks, providing the model with a comprehensive understanding of the task. Second, the fine-tuned LLM is used to instantiate the planner, caller, and summarizer respectively, which are continually fine-tuned on respective sub-tasks. Evaluation across various tool-use benchmarks illustrates that our proposed multi-LLM framework surpasses the traditional single-LLM approach, highlighting its efficacy and advantages in tool learning.
Knowledge Distillation for Closed-Source Language Models
Jan 13, 2024



Closed-source language models such as GPT-4 have achieved remarkable performance. Many recent studies focus on enhancing the capabilities of smaller models through knowledge distillation from closed-source language models. However, due to the incapability to directly access the weights, hidden states, and output distributions of these closed-source models, the distillation can only be performed by fine-tuning smaller models with data samples generated by closed-source language models, which constrains the effectiveness of knowledge distillation. In this paper, we propose to estimate the output distributions of closed-source language models within a Bayesian estimation framework, involving both prior and posterior estimation. The prior estimation aims to derive a prior distribution by utilizing the corpus generated by closed-source language models, while the posterior estimation employs a proxy model to update the prior distribution and derive a posterior distribution. By leveraging the estimated output distribution of closed-source language models, traditional knowledge distillation can be executed. Experimental results demonstrate that our method surpasses the performance of current models directly fine-tuned on data generated by closed-source language models.
MCC-KD: Multi-CoT Consistent Knowledge Distillation
Oct 24, 2023



Large language models (LLMs) have showcased remarkable capabilities in complex reasoning through chain of thought (CoT) prompting. Recently, there has been a growing interest in transferring these reasoning abilities from LLMs to smaller models. However, achieving both the diversity and consistency in rationales presents a challenge. In this paper, we focus on enhancing these two aspects and propose Multi-CoT Consistent Knowledge Distillation (MCC-KD) to efficiently distill the reasoning capabilities. In MCC-KD, we generate multiple rationales for each question and enforce consistency among the corresponding predictions by minimizing the bidirectional KL-divergence between the answer distributions. We investigate the effectiveness of MCC-KD with different model architectures (LLaMA/FlanT5) and various model scales (3B/7B/11B/13B) on both mathematical reasoning and commonsense reasoning benchmarks. The empirical results not only confirm MCC-KD's superior performance on in-distribution datasets but also highlight its robust generalization ability on out-of-distribution datasets.
AD-KD: Attribution-Driven Knowledge Distillation for Language Model Compression
May 17, 2023Knowledge distillation has attracted a great deal of interest recently to compress pre-trained language models. However, existing knowledge distillation methods suffer from two limitations. First, the student model simply imitates the teacher's behavior while ignoring the underlying reasoning. Second, these methods usually focus on the transfer of sophisticated model-specific knowledge but overlook data-specific knowledge. In this paper, we present a novel attribution-driven knowledge distillation approach, which explores the token-level rationale behind the teacher model based on Integrated Gradients (IG) and transfers attribution knowledge to the student model. To enhance the knowledge transfer of model reasoning and generalization, we further explore multi-view attribution distillation on all potential decisions of the teacher. Comprehensive experiments are conducted with BERT on the GLUE benchmark. The experimental results demonstrate the superior performance of our approach to several state-of-the-art methods.