 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpusQA: A 10 Million Token Benchmark for Corpus-Level Analysis and Reasoning
Jan 21, 2026While large language models now handle million-token contexts, their capacity for reasoning across entire document repositories remains largely untested. Existing benchmarks are inadequate, as they are mostly limited to single long texts or rely on a "sparse retrieval" assumption-that answers can be derived from a few relevant chunks. This assumption fails for true corpus-level analysis, where evidence is highly dispersed across hundreds of documents and answers require global integration, comparison, and statistical aggregation. To address this critical gap, we introduce CorpusQA, a new benchmark scaling up to 10 million tokens, generated via a novel data synthesis framework. By decoupling reasoning from textual representation, this framework creates complex, computation-intensive queries with programmatically guaranteed ground-truth answers, challenging systems to perform holistic reasoning over vast, unstructured text without relying on fallible human annotation. We further demonstrate the utility of our framework beyond evaluation, showing that fine-tuning on our synthesized data effectively enhances an LLM's general long-context reasoning capabilities. Extensive experiments reveal that even state-of-the-art long-context LLMs struggle as input length increases, and standard retrieval-augmented generation systems collapse entirely. Our findings indicate that memory-augmented agentic architectures offer a more robust alternative, suggesting a critical shift is needed from simply extending context windows to developing advanced architectures for global information synthesis.
Incentivizing In-depth Reasoning over Long Contexts with Process Advantage Shaping
Jan 18, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective in enhancing LLMs short-context reasoning, but its performance degrades in long-context scenarios that require both precise grounding and robust long-range reasoning. We identify the "almost-there" phenomenon in long-context reasoning, where trajectories are largely correct but fail at the final step, and attribute this failure to two factors: (1) the lack of high reasoning density in long-context QA data that push LLMs beyond mere grounding toward sophisticated multi-hop reasoning; and (2) the loss of valuable learning signals during long-context RL training due to the indiscriminate penalization of partially correct trajectories with incorrect outcomes. To overcome this bottleneck, we propose DeepReasonQA, a KG-driven synthesis framework that controllably constructs high-difficulty, multi-hop long-context QA pairs with inherent reasoning chains. Building on this, we introduce Long-context Process Advantage Shaping (LongPAS), a simple yet effective method that performs fine-grained credit assignment by evaluating reasoning steps along Validity and Relevance dimensions, which captures critical learning signals from "almost-there" trajectories. Experiments on three long-context reasoning benchmarks show that our approach substantially outperforms RLVR baselines and matches frontier LLMs while using far fewer parameters. Further analysis confirms the effectiveness of our methods in strengthening long-context reasoning while maintaining stable RL training.
AgentOCR: Reimagining Agent History via Optical Self-Compression
Jan 08, 2026Recent advances in large language models (LLMs) enable agentic systems trained with reinforcement learning (RL) over multi-turn interaction trajectories, but practical deployment is bottlenecked by rapidly growing textual histories that inflate token budgets and memory usage. We introduce AgentOCR, a framework that exploits the superior information density of visual tokens by representing the accumulated observation-action history as a compact rendered image. To make multi-turn rollouts scalable, AgentOCR proposes segment optical caching. By decomposing history into hashable segments and maintaining a visual cache, this mechanism eliminates redundant re-rendering. Beyond fixed rendering, AgentOCR introduces agentic self-compression, where the agent actively emits a compression rate and is trained with compression-aware reward to adaptively balance task success and token efficiency. We conduct extensive experiments on challenging agentic benchmarks, ALFWorld and search-based QA. Remarkably, results demonstrate that AgentOCR preserves over 95\% of text-based agent performance while substantially reducing token consumption (>50\%), yielding consistent token and memory efficiency. Our further analysis validates a 20x rendering speedup from segment optical caching and the effective strategic balancing of self-compression.
Real-Time Lane Detection via Efficient Feature Alignment and Covariance Optimization for Low-Power Embedded Systems
Jan 05, 2026Real-time lane detection in embedded systems encounters significant challenges due to subtle and sparse visual signals in RGB images, often constrained by limited computational resources and power consumption. Although deep learning models for lane detection categorized into segmentation-based, anchor-based, and curve-based methods there remains a scarcity of universally applicable optimization techniques tailored for low-power embedded environments. To overcome this, we propose an innovative Covariance Distribution Optimization (CDO) module specifically designed for efficient, real-time applications. The CDO module aligns lane feature distributions closely with ground-truth labels, significantly enhancing detection accuracy without increasing computational complexity. Evaluations were conducted on six diverse models across all three method categories, including two optimized for real-time applications and four state-of-the-art (SOTA) models, tested comprehensively on three major datasets: CULane, TuSimple, and LLAMAS. Experimental results demonstrate accuracy improvements ranging from 0.01% to 1.5%. The proposed CDO module is characterized by ease of integration into existing systems without structural modifications and utilizes existing model parameters to facilitate ongoing training, thus offering substantial benefits in performance, power efficiency, and operational flexibility in embedded systems.
QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
Dec 15, 2025We introduce QwenLong-L1.5, a model that achieves superior long-context reasoning capabilities through systematic post-training innovations. The key technical breakthroughs of QwenLong-L1.5 are as follows: (1) Long-Context Data Synthesis Pipeline: We develop a systematic synthesis framework that generates challenging reasoning tasks requiring multi-hop grounding over globally distributed evidence. By deconstructing documents into atomic facts and their underlying relationships, and then programmatically composing verifiable reasoning questions, our approach creates high-quality training data at scale, moving substantially beyond simple retrieval tasks to enable genuine long-range reasoning capabilities. (2) Stabilized Reinforcement Learning for Long-Context Training: To overcome the critical instability in long-context RL, we introduce task-balanced sampling with task-specific advantage estimation to mitigate reward bias, and propose Adaptive Entropy-Controlled Policy Optimization (AEPO) that dynamically regulates exploration-exploitation trade-offs. (3) Memory-Augmented Architecture for Ultra-Long Contexts: Recognizing that even extended context windows cannot accommodate arbitrarily long sequences, we develop a memory management framework with multi-stage fusion RL training that seamlessly integrates single-pass reasoning with iterative memory-based processing for tasks exceeding 4M tokens. Based on Qwen3-30B-A3B-Thinking, QwenLong-L1.5 achieves performance comparable to GPT-5 and Gemini-2.5-Pro on long-context reasoning benchmarks, surpassing its baseline by 9.90 points on average. On ultra-long tasks (1M~4M tokens), QwenLong-L1.5's memory-agent framework yields a 9.48-point gain over the agent baseline. Additionally, the acquired long-context reasoning ability translates to enhanced performance in general domains like scientific reasoning, memory tool using, and extended dialogue.
Zero-shot 3D Map Generation with LLM Agents: A Dual-Agent Architecture for Procedural Content Generation
Dec 12, 2025



Procedural Content Generation (PCG) offers scalable methods for algorithmically creating complex, customizable worlds. However, controlling these pipelines requires the precise configuration of opaque technical parameters. We propose a training-free architecture that utilizes LLM agents for zero-shot PCG parameter configuration. While Large Language Models (LLMs) promise a natural language interface for PCG tools, off-the-shelf models often fail to bridge the semantic gap between abstract user instructions and strict parameter specifications. Our system pairs an Actor agent with a Critic agent, enabling an iterative workflow where the system autonomously reasons over tool parameters and refines configurations to progressively align with human design preferences. We validate this approach on the generation of various 3D maps, establishing a new benchmark for instruction-following in PCG. Experiments demonstrate that our approach outperforms single-agent baselines, producing diverse and structurally valid environments from natural language descriptions. These results demonstrate that off-the-shelf LLMs can be effectively repurposed as generalized agents for arbitrary PCG tools. By shifting the burden from model training to architectural reasoning, our method offers a scalable framework for mastering complex software without task-specific fine-tuning.
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025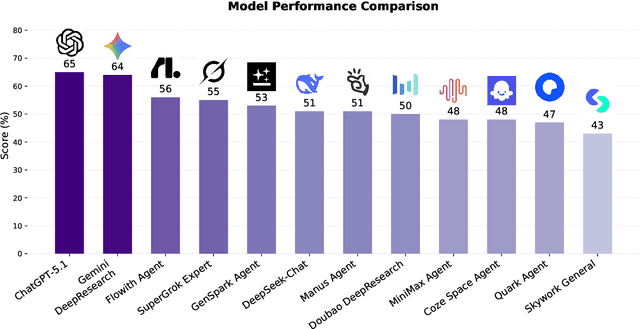
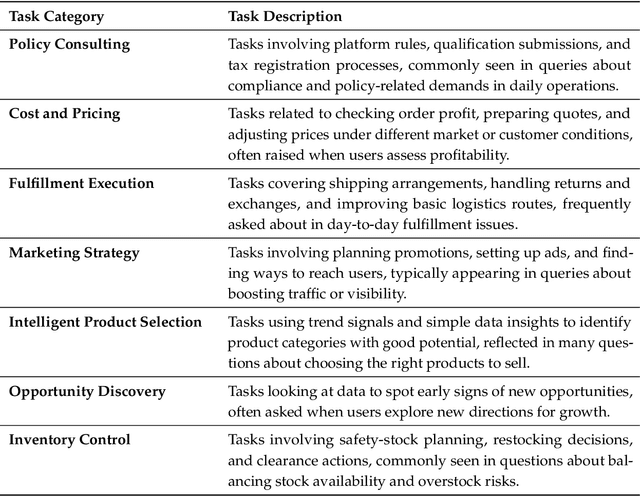

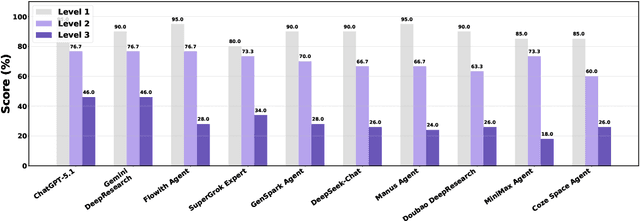
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
Efficient and Effective In-context Demonstration Selection with Coreset
Nov 12, 2025In-context learning (ICL) has emerged as a powerful paradigm for Large Visual Language Models (LVLMs), enabling them to leverage a few examples directly from input contexts. However, the effectiveness of this approach is heavily reliant on the selection of demonstrations, a process that is NP-hard. Traditional strategies, including random, similarity-based sampling and infoscore-based sampling, often lead to inefficiencies or suboptimal performance, struggling to balance both efficiency and effectiveness in demonstration selection. In this paper, we propose a novel demonstration selection framework named Coreset-based Dual Retrieval (CoDR). We show that samples within a diverse subset achieve a higher expected mutual information. To implement this, we introduce a cluster-pruning method to construct a diverse coreset that aligns more effectively with the query while maintaining diversity. Additionally, we develop a dual retrieval mechanism that enhances the selection process by achieving global demonstration selection while preserving efficiency. Experimental results demonstrate that our method significantly improves the ICL performance compared to the existing strategies, providing a robust solution for effective and efficient demonstration selection.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
Sep 16, 2025



This paper tackles open-ended deep research (OEDR), a complex challenge where AI agents must synthesize vast web-scale information into insightful reports. Current approaches are plagued by dual-fold limitations: static research pipelines that decouple planning from evidence acquisition and one-shot generation paradigms that easily suffer from long-context failure issues like "loss in the middle" and hallucinations. To address these challenges, we introduce WebWeaver, a novel dual-agent framework that emulates the human research process. The planner operates in a dynamic cycle, iteratively interleaving evidence acquisition with outline optimization to produce a comprehensive, source-grounded outline linking to a memory bank of evidence. The writer then executes a hierarchical retrieval and writing process, composing the report section by section. By performing targeted retrieval of only the necessary evidence from the memory bank for each part, it effectively mitigates long-context issues. Our framework establishes a new state-of-the-art across major OEDR benchmarks, including DeepResearch Bench, DeepConsult, and DeepResearchGym. These results validate our human-centric, iterative methodology, demonstrating that adaptive planning and focused synthesis are crucial for producing high-quality, reliable, and well-structured reports.