 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAC-Tuning: LLM Multi-Compositional Problem Reasoning with Enhanced Knowledge Boundary Awareness
Apr 30, 2025With the widespread application of large language models (LLMs), the issue of generating non-existing facts, known as hallucination, has garnered increasing attention. Previous research in enhancing LLM confidence estimation mainly focuses on the single problem setting. However, LLM awareness of its internal parameterized knowledge boundary under the more challenging multi-problem setting, which requires answering multiple problems accurately simultaneously, remains underexplored. To bridge this gap, we introduce a novel method, Multiple Answers and Confidence Stepwise Tuning (MAC-Tuning), that separates the learning of answer prediction and confidence estimation during fine-tuning on instruction data. Extensive experiments demonstrate that our method outperforms baselines by up to 25% in average precision.
Enhancing Language Multi-Agent Learning with Multi-Agent Credit Re-Assignment for Interactive Environment Generalization
Feb 20, 2025LLM-based agents have made significant advancements in interactive environments, such as mobile operations and web browsing, and other domains beyond computer using. Current multi-agent systems universally excel in performance, compared to single agents, but struggle with generalization across environments due to predefined roles and inadequate strategies for generalizing language agents. The challenge of achieving both strong performance and good generalization has hindered the progress of multi-agent systems for interactive environments. To address these issues, we propose CollabUIAgents, a multi-agent reinforcement learning framework with a novel multi-agent credit re-assignment (CR) strategy, assigning process rewards with LLMs rather than environment-specific rewards and learning with synthesized preference data, in order to foster generalizable, collaborative behaviors among the role-free agents' policies. Empirical results show that our framework improves both performance and cross-environment generalizability of multi-agent systems. Moreover, our 7B-parameter system achieves results on par with or exceed strong closed-source models, and the LLM that guides the CR. We also provide insights in using granular CR rewards effectively for environment generalization, and accommodating trained LLMs in multi-agent systems.
CALM: Unleashing the Cross-Lingual Self-Aligning Ability of Language Model Question Answering
Jan 30, 2025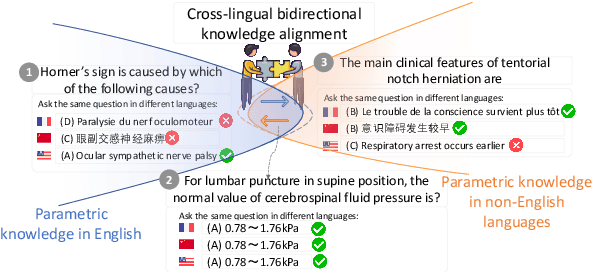



Large Language Models (LLMs) are pretrained on extensive multilingual corpora to acquire both language-specific cultural knowledge and general knowledge. Ideally, while LLMs should provide consistent responses to culture-independent questions across languages, we observe significant performance disparities. To address this, we explore the Cross-Lingual Self-Aligning ability of Language Models (CALM) to align knowledge across languages. Specifically, for a given question, we sample multiple responses across different languages, and select the most self-consistent response as the target, leaving the remaining responses as negative examples. We then employ direct preference optimization (DPO) to align the model's knowledge across different languages. Evaluations on the MEDQA and X-CSQA datasets demonstrate CALM's effectiveness in enhancing cross-lingual knowledge question answering, both in zero-shot and retrieval augmented settings. We also found that increasing the number of languages involved in CALM training leads to even higher accuracy and consistency. We offer a qualitative analysis of how cross-lingual consistency can enhance knowledge alignment and explore the method's generalizability. The source code and data of this paper are available on GitHub.
Schema-Guided Culture-Aware Complex Event Simulation with Multi-Agent Role-Play
Oct 24, 2024



Complex news events, such as natural disasters and socio-political conflicts, require swift responses from the government and society. Relying on historical events to project the future is insufficient as such events are sparse and do not cover all possible conditions and nuanced situations. Simulation of these complex events can help better prepare and reduce the negative impact. We develop a controllable complex news event simulator guided by both the event schema representing domain knowledge about the scenario and user-provided assumptions representing case-specific conditions. As event dynamics depend on the fine-grained social and cultural context, we further introduce a geo-diverse commonsense and cultural norm-aware knowledge enhancement component. To enhance the coherence of the simulation, apart from the global timeline of events, we take an agent-based approach to simulate the individual character states, plans, and actions. By incorporating the schema and cultural norms, our generated simulations achieve much higher coherence and appropriateness and are received favorably by participants from a humanitarian assistance organization.
MentalArena: Self-play Training of Language Models for Diagnosis and Treatment of Mental Health Disorders
Oct 09, 2024



Mental health disorders are one of the most serious diseases in the world. Most people with such a disease lack access to adequate care, which highlights the importance of training models for the diagnosis and treatment of mental health disorders. However, in the mental health domain, privacy concerns limit the accessibility of personalized treatment data, making it challenging to build powerful models. In this paper, we introduce MentalArena, a self-play framework to train language models by generating domain-specific personalized data, where we obtain a better model capable of making a personalized diagnosis and treatment (as a therapist) and providing information (as a patient). To accurately model human-like mental health patients, we devise Symptom Encoder, which simulates a real patient from both cognition and behavior perspectives. To address intent bias during patient-therapist interactions, we propose Symptom Decoder to compare diagnosed symptoms with encoded symptoms, and dynamically manage the dialogue between patient and therapist according to the identified deviations. We evaluated MentalArena against 6 benchmarks, including biomedicalQA and mental health tasks, compared to 6 advanced models. Our models, fine-tuned on both GPT-3.5 and Llama-3-8b, significantly outperform their counterparts, including GPT-4o. We hope that our work can inspire future research on personalized care. Code is available in https://github.com/Scarelette/MentalArena/tree/main
Aligning LLMs with Individual Preferences via Interaction
Oct 04, 2024As large language models (LLMs) demonstrate increasingly advanced capabilities, aligning their behaviors with human values and preferences becomes crucial for their wide adoption. While previous research focuses on general alignment to principles such as helpfulness, harmlessness, and honesty, the need to account for individual and diverse preferences has been largely overlooked, potentially undermining customized human experiences. To address this gap, we train LLMs that can ''interact to align'', essentially cultivating the meta-skill of LLMs to implicitly infer the unspoken personalized preferences of the current user through multi-turn conversations, and then dynamically align their following behaviors and responses to these inferred preferences. Our approach involves establishing a diverse pool of 3,310 distinct user personas by initially creating seed examples, which are then expanded through iterative self-generation and filtering. Guided by distinct user personas, we leverage multi-LLM collaboration to develop a multi-turn preference dataset containing 3K+ multi-turn conversations in tree structures. Finally, we apply supervised fine-tuning and reinforcement learning to enhance LLMs using this dataset. For evaluation, we establish the ALOE (ALign With CustOmized PrEferences) benchmark, consisting of 100 carefully selected examples and well-designed metrics to measure the customized alignment performance during conversations. Experimental results demonstrate the effectiveness of our method in enabling dynamic, personalized alignment via interaction.