 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Robot Dialogue Annotation for Multi-Modal Common Ground
Nov 19, 2024In this paper, we describe the development of symbolic representations annotated on human-robot dialogue data to make dimensions of meaning accessible to autonomous systems participating in collaborative, natural language dialogue, and to enable common ground with human partners. A particular challenge for establishing common ground arises in remote dialogue (occurring in disaster relief or search-and-rescue tasks), where a human and robot are engaged in a joint navigation and exploration task of an unfamiliar environment, but where the robot cannot immediately share high quality visual information due to limited communication constraints. Engaging in a dialogue provides an effective way to communicate, while on-demand or lower-quality visual information can be supplemented for establishing common ground. Within this paradigm, we capture propositional semantics and the illocutionary force of a single utterance within the dialogue through our Dialogue-AMR annotation, an augmentation of Abstract Meaning Representation. We then capture patterns in how different utterances within and across speaker floors relate to one another in our development of a multi-floor Dialogue Structure annotation schema. Finally, we begin to annotate and analyze the ways in which the visual modalities provide contextual information to the dialogue for overcoming disparities in the collaborators' understanding of the environment. We conclude by discussing the use-cases, architectures, and systems we have implemented from our annotations that enable physical robots to autonomously engage with humans in bi-directional dialogue and navigation.
* 52 pages, 14 figures
SCOUT: A Situated and Multi-Modal Human-Robot Dialogue Corpus
Nov 19, 2024



We introduce the Situated Corpus Of Understanding Transactions (SCOUT), a multi-modal collection of human-robot dialogue in the task domain of collaborative exploration. The corpus was constructed from multiple Wizard-of-Oz experiments where human participants gave verbal instructions to a remotely-located robot to move and gather information about its surroundings. SCOUT contains 89,056 utterances and 310,095 words from 278 dialogues averaging 320 utterances per dialogue. The dialogues are aligned with the multi-modal data streams available during the experiments: 5,785 images and 30 maps. The corpus has been annotated with Abstract Meaning Representation and Dialogue-AMR to identify the speaker's intent and meaning within an utterance, and with Transactional Units and Relations to track relationships between utterances to reveal patterns of the Dialogue Structure. We describe how the corpus and its annotations have been used to develop autonomous human-robot systems and enable research in open questions of how humans speak to robots. We release this corpus to accelerate progress in autonomous, situated, human-robot dialogue, especially in the context of navigation tasks where details about the environment need to be discovered.
* 14 pages, 7 figures
Schema-Guided Culture-Aware Complex Event Simulation with Multi-Agent Role-Play
Oct 24, 2024



Complex news events, such as natural disasters and socio-political conflicts, require swift responses from the government and society. Relying on historical events to project the future is insufficient as such events are sparse and do not cover all possible conditions and nuanced situations. Simulation of these complex events can help better prepare and reduce the negative impact. We develop a controllable complex news event simulator guided by both the event schema representing domain knowledge about the scenario and user-provided assumptions representing case-specific conditions. As event dynamics depend on the fine-grained social and cultural context, we further introduce a geo-diverse commonsense and cultural norm-aware knowledge enhancement component. To enhance the coherence of the simulation, apart from the global timeline of events, we take an agent-based approach to simulate the individual character states, plans, and actions. By incorporating the schema and cultural norms, our generated simulations achieve much higher coherence and appropriateness and are received favorably by participants from a humanitarian assistance organization.
What Else Do I Need to Know? The Effect of Background Information on Users' Reliance on AI Systems
May 23, 2023AI systems have shown impressive performance at answering questions by retrieving relevant context. However, with the increasingly large models, it is impossible and often undesirable to constrain models' knowledge or reasoning to only the retrieved context. This leads to a mismatch between the information that these models access to derive the answer and the information available to the user consuming the AI predictions to assess the AI predicted answer. In this work, we study how users interact with AI systems in absence of sufficient information to assess AI predictions. Further, we ask the question of whether adding the requisite background alleviates the concerns around over-reliance in AI predictions. Our study reveals that users rely on AI predictions even in the absence of sufficient information needed to assess its correctness. Providing the relevant background, however, helps users catch AI errors better, reducing over-reliance on incorrect AI predictions. On the flip side, background information also increases users' confidence in their correct as well as incorrect judgments. Contrary to common expectation, aiding a user's perusal of the context and the background through highlights is not helpful in alleviating the issue of over-confidence stemming from availability of more information. Our work aims to highlight the gap between how NLP developers perceive informational need in human-AI interaction and the actual human interaction with the information available to them.
Language Model Pre-Training with Sparse Latent Typing
Oct 26, 2022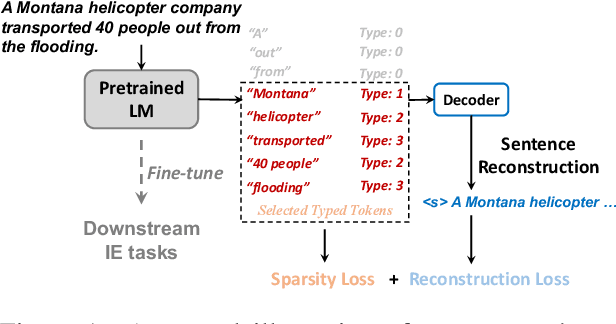
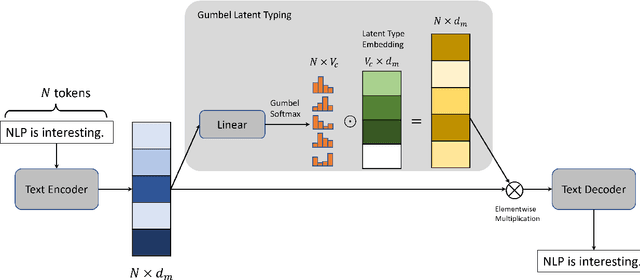

Modern large-scale Pre-trained Language Models (PLMs) have achieved tremendous success on a wide range of downstream tasks. However, most of the LM pre-training objectives only focus on text reconstruction, but have not sought to learn latent-level interpretable representations of sentences. In this paper, we manage to push the language models to obtain a deeper understanding of sentences by proposing a new pre-training objective, Sparse Latent Typing, which enables the model to sparsely extract sentence-level keywords with diverse latent types. Experimental results show that our model is able to learn interpretable latent type categories in a self-supervised manner without using any external knowledge. Besides, the language model pre-trained with such an objective also significantly improves Information Extraction related downstream tasks in both supervised and few-shot settings. Our code is publicly available at: https://github.com/renll/SparseLT.
Visual Understanding and Narration: A Deeper Understanding and Explanation of Visual Scenes
May 31, 2019
We describe the task of Visual Understanding and Narration, in which a robot (or agent) generates text for the images that it collects when navigating its environment, by answering open-ended questions, such as 'what happens, or might have happened, here?'
A Pipeline for Creative Visual Storytelling
Jul 21, 2018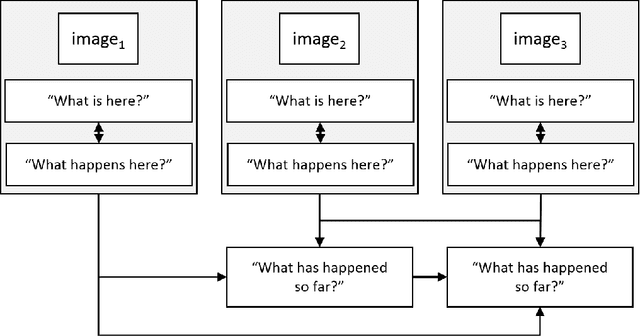



Computational visual storytelling produces a textual description of events and interpretations depicted in a sequence of images. These texts are made possible by advances and cross-disciplinary approaches in natural language processing, generation, and computer vision. We define a computational creative visual storytelling as one with the ability to alter the telling of a story along three aspects: to speak about different environments, to produce variations based on narrative goals, and to adapt the narrative to the audience. These aspects of creative storytelling and their effect on the narrative have yet to be explored in visual storytelling. This paper presents a pipeline of task-modules, Object Identification, Single-Image Inferencing, and Multi-Image Narration, that serve as a preliminary design for building a creative visual storyteller. We have piloted this design for a sequence of images in an annotation task. We present and analyze the collected corpus and describe plans towards automation.
Consequences and Factors of Stylistic Differences in Human-Robot Dialogue
Jul 21, 2018

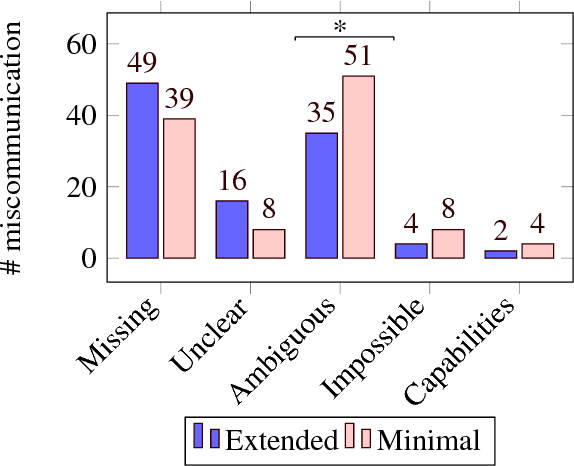
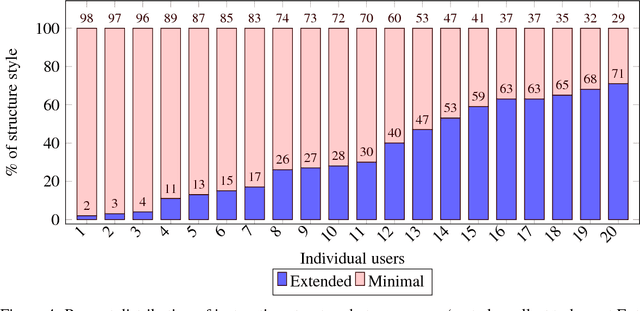
This paper identifies stylistic differences in instruction-giving observed in a corpus of human-robot dialogue. Differences in verbosity and structure (i.e., single-intent vs. multi-intent instructions) arose naturally without restrictions or prior guidance on how users should speak with the robot. Different styles were found to produce different rates of miscommunication, and correlations were found between style differences and individual user variation, trust, and interaction experience with the robot. Understanding potential consequences and factors that influence style can inform design of dialogue systems that are robust to natural variation from human users.
ScoutBot: A Dialogue System for Collaborative Navigation
Jul 21, 2018
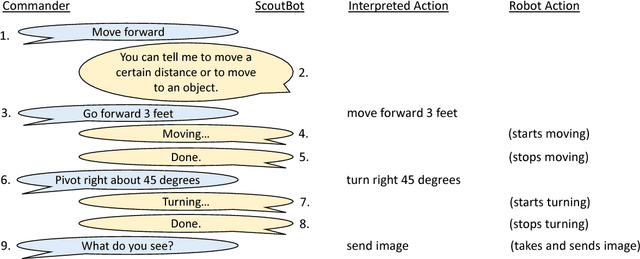
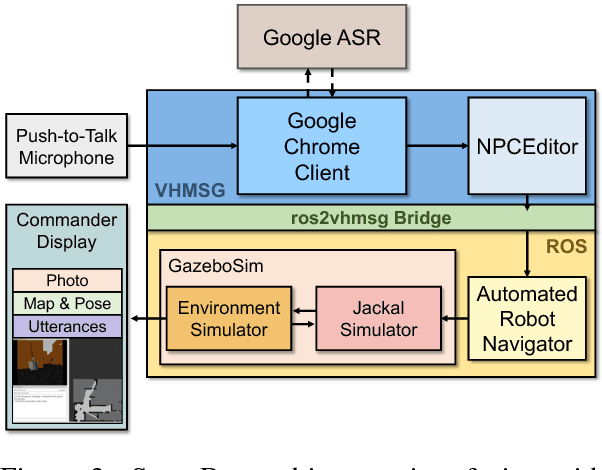

ScoutBot is a dialogue interface to physical and simulated robots that supports collaborative exploration of environments. The demonstration will allow users to issue unconstrained spoken language commands to ScoutBot. ScoutBot will prompt for clarification if the user's instruction needs additional input. It is trained on human-robot dialogue collected from Wizard-of-Oz experiments, where robot responses were initiated by a human wizard in previous interactions. The demonstration will show a simulated ground robot (Clearpath Jackal) in a simulated environment supported by ROS (Robot Operating System).
Laying Down the Yellow Brick Road: Development of a Wizard-of-Oz Interface for Collecting Human-Robot Dialogue
Oct 17, 2017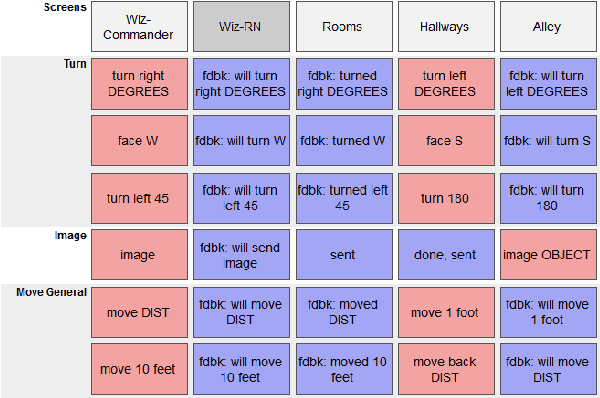
We describe the adaptation and refinement of a graphical user interface designed to facilitate a Wizard-of-Oz (WoZ) approach to collecting human-robot dialogue data. The data collected will be used to develop a dialogue system for robot navigation. Building on an interface previously used in the development of dialogue systems for virtual agents and video playback, we add templates with open parameters which allow the wizard to quickly produce a wide variety of utterances. Our research demonstrates that this approach to data collection is viable as an intermediate step in developing a dialogue system for physical robots in remote locations from their users - a domain in which the human and robot need to regularly verify and update a shared understanding of the physical environment. We show that our WoZ interface and the fixed set of utterances and templates therein provide for a natural pace of dialogue with good coverage of the navigation domain.