 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-and-Language Training Helps Deploy Taxonomic Knowledge but Does Not Fundamentally Alter It
Jul 17, 2025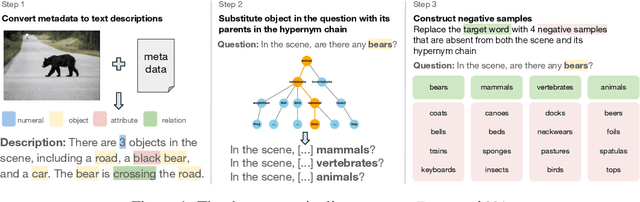
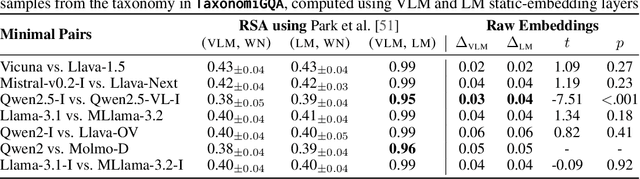
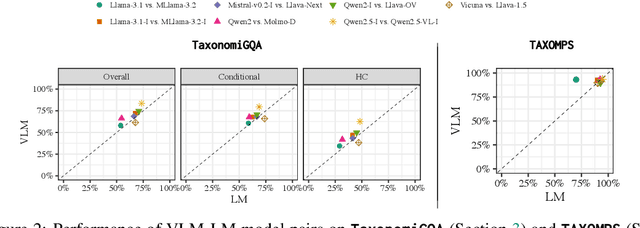
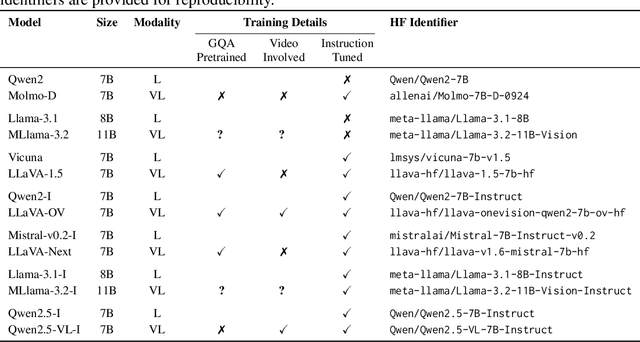
Does vision-and-language (VL) training change the linguistic representations of language models in meaningful ways? Most results in the literature have shown inconsistent or marginal differences, both behaviorally and representationally. In this work, we start from the hypothesis that the domain in which VL training could have a significant effect is lexical-conceptual knowledge, in particular its taxonomic organization. Through comparing minimal pairs of text-only LMs and their VL-trained counterparts, we first show that the VL models often outperform their text-only counterparts on a text-only question-answering task that requires taxonomic understanding of concepts mentioned in the questions. Using an array of targeted behavioral and representational analyses, we show that the LMs and VLMs do not differ significantly in terms of their taxonomic knowledge itself, but they differ in how they represent questions that contain concepts in a taxonomic relation vs. a non-taxonomic relation. This implies that the taxonomic knowledge itself does not change substantially through additional VL training, but VL training does improve the deployment of this knowledge in the context of a specific task, even when the presentation of the task is purely linguistic.
Human-Robot Dialogue Annotation for Multi-Modal Common Ground
Nov 19, 2024In this paper, we describe the development of symbolic representations annotated on human-robot dialogue data to make dimensions of meaning accessible to autonomous systems participating in collaborative, natural language dialogue, and to enable common ground with human partners. A particular challenge for establishing common ground arises in remote dialogue (occurring in disaster relief or search-and-rescue tasks), where a human and robot are engaged in a joint navigation and exploration task of an unfamiliar environment, but where the robot cannot immediately share high quality visual information due to limited communication constraints. Engaging in a dialogue provides an effective way to communicate, while on-demand or lower-quality visual information can be supplemented for establishing common ground. Within this paradigm, we capture propositional semantics and the illocutionary force of a single utterance within the dialogue through our Dialogue-AMR annotation, an augmentation of Abstract Meaning Representation. We then capture patterns in how different utterances within and across speaker floors relate to one another in our development of a multi-floor Dialogue Structure annotation schema. Finally, we begin to annotate and analyze the ways in which the visual modalities provide contextual information to the dialogue for overcoming disparities in the collaborators' understanding of the environment. We conclude by discussing the use-cases, architectures, and systems we have implemented from our annotations that enable physical robots to autonomously engage with humans in bi-directional dialogue and navigation.
* 52 pages, 14 figures
SCOUT: A Situated and Multi-Modal Human-Robot Dialogue Corpus
Nov 19, 2024



We introduce the Situated Corpus Of Understanding Transactions (SCOUT), a multi-modal collection of human-robot dialogue in the task domain of collaborative exploration. The corpus was constructed from multiple Wizard-of-Oz experiments where human participants gave verbal instructions to a remotely-located robot to move and gather information about its surroundings. SCOUT contains 89,056 utterances and 310,095 words from 278 dialogues averaging 320 utterances per dialogue. The dialogues are aligned with the multi-modal data streams available during the experiments: 5,785 images and 30 maps. The corpus has been annotated with Abstract Meaning Representation and Dialogue-AMR to identify the speaker's intent and meaning within an utterance, and with Transactional Units and Relations to track relationships between utterances to reveal patterns of the Dialogue Structure. We describe how the corpus and its annotations have been used to develop autonomous human-robot systems and enable research in open questions of how humans speak to robots. We release this corpus to accelerate progress in autonomous, situated, human-robot dialogue, especially in the context of navigation tasks where details about the environment need to be discovered.
* 14 pages, 7 figures
ConvoFusion: Multi-Modal Conversational Diffusion for Co-Speech Gesture Synthesis
Mar 26, 2024



Gestures play a key role in human communication. Recent methods for co-speech gesture generation, while managing to generate beat-aligned motions, struggle generating gestures that are semantically aligned with the utterance. Compared to beat gestures that align naturally to the audio signal, semantically coherent gestures require modeling the complex interactions between the language and human motion, and can be controlled by focusing on certain words. Therefore, we present ConvoFusion, a diffusion-based approach for multi-modal gesture synthesis, which can not only generate gestures based on multi-modal speech inputs, but can also facilitate controllability in gesture synthesis. Our method proposes two guidance objectives that allow the users to modulate the impact of different conditioning modalities (e.g. audio vs text) as well as to choose certain words to be emphasized during gesturing. Our method is versatile in that it can be trained either for generating monologue gestures or even the conversational gestures. To further advance the research on multi-party interactive gestures, the DnD Group Gesture dataset is released, which contains 6 hours of gesture data showing 5 people interacting with one another. We compare our method with several recent works and demonstrate effectiveness of our method on a variety of tasks. We urge the reader to watch our supplementary video at our website.
AMR Parsing is Far from Solved: GrAPES, the Granular AMR Parsing Evaluation Suite
Dec 06, 2023We present the Granular AMR Parsing Evaluation Suite (GrAPES), a challenge set for Abstract Meaning Representation (AMR) parsing with accompanying evaluation metrics. AMR parsers now obtain high scores on the standard AMR evaluation metric Smatch, close to or even above reported inter-annotator agreement. But that does not mean that AMR parsing is solved; in fact, human evaluation in previous work indicates that current parsers still quite frequently make errors on node labels or graph structure that substantially distort sentence meaning. Here, we provide an evaluation suite that tests AMR parsers on a range of phenomena of practical, technical, and linguistic interest. Our 36 categories range from seen and unseen labels, to structural generalization, to coreference. GrAPES reveals in depth the abilities and shortcomings of current AMR parsers.
Cultural Adaptation of Recipes
Oct 26, 2023Building upon the considerable advances in Large Language Models (LLMs), we are now equipped to address more sophisticated tasks demanding a nuanced understanding of cross-cultural contexts. A key example is recipe adaptation, which goes beyond simple translation to include a grasp of ingredients, culinary techniques, and dietary preferences specific to a given culture. We introduce a new task involving the translation and cultural adaptation of recipes between Chinese and English-speaking cuisines. To support this investigation, we present CulturalRecipes, a unique dataset comprised of automatically paired recipes written in Mandarin Chinese and English. This dataset is further enriched with a human-written and curated test set. In this intricate task of cross-cultural recipe adaptation, we evaluate the performance of various methods, including GPT-4 and other LLMs, traditional machine translation, and information retrieval techniques. Our comprehensive analysis includes both automatic and human evaluation metrics. While GPT-4 exhibits impressive abilities in adapting Chinese recipes into English, it still lags behind human expertise when translating English recipes into Chinese. This underscores the multifaceted nature of cultural adaptations. We anticipate that these insights will significantly contribute to future research on culturally-aware language models and their practical application in culturally diverse contexts.
SLOG: A Structural Generalization Benchmark for Semantic Parsing
Oct 23, 2023The goal of compositional generalization benchmarks is to evaluate how well models generalize to new complex linguistic expressions. Existing benchmarks often focus on lexical generalization, the interpretation of novel lexical items in syntactic structures familiar from training; structural generalization tasks, where a model needs to interpret syntactic structures that are themselves unfamiliar from training, are often underrepresented, resulting in overly optimistic perceptions of how well models can generalize. We introduce SLOG, a semantic parsing dataset that extends COGS (Kim and Linzen, 2020) with 17 structural generalization cases. In our experiments, the generalization accuracy of Transformer models, including pretrained ones, only reaches 40.6%, while a structure-aware parser only achieves 70.8%. These results are far from the near-perfect accuracy existing models achieve on COGS, demonstrating the role of SLOG in foregrounding the large discrepancy between models' lexical and structural generalization capacities.
Spanish Abstract Meaning Representation: Annotation of a General Corpus
Apr 15, 2022
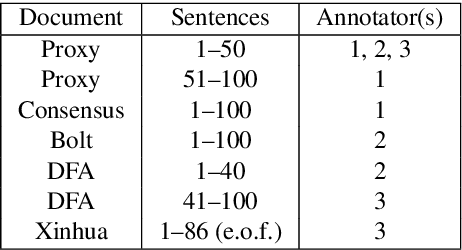


The Abstract Meaning Representation (AMR) formalism, designed originally for English, has been adapted to a number of languages. We build on previous work proposing the annotation of AMR in Spanish, which resulted in the release of 50 Spanish AMR annotations for the fictional text "The Little Prince." In this work, we present the first sizable, general annotation project for Spanish Abstract Meaning Representation. Our approach to annotation makes use of Spanish rolesets from the AnCora-Net lexicon and extends English AMR with semantic features specific to Spanish. In addition to our guidelines, we release an annotated corpus (586 annotations total, for 486 unique sentences) of multiple genres of documents from the "Abstract Meaning Representation 2.0 - Four Translations" sembank. This corpus is commonly used for evaluation of AMR parsing and generation, but does not include gold AMRs; we hope that providing gold annotations for this dataset can result in a more complete approach to cross-lingual AMR parsing. Finally, we perform a disagreement analysis and discuss the implications of our work on the adaptability of AMR to languages other than English.
Compositional Generalization Requires Compositional Parsers
Feb 24, 2022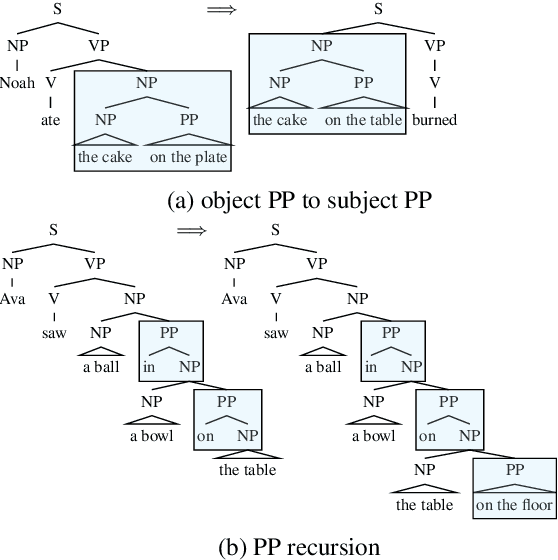
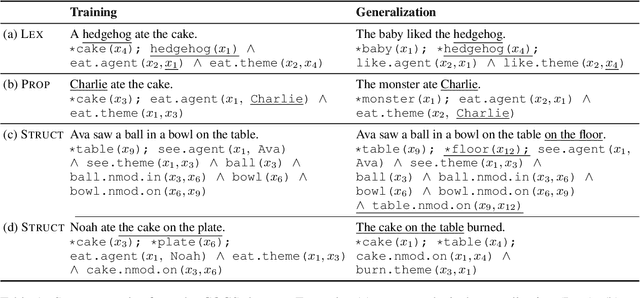
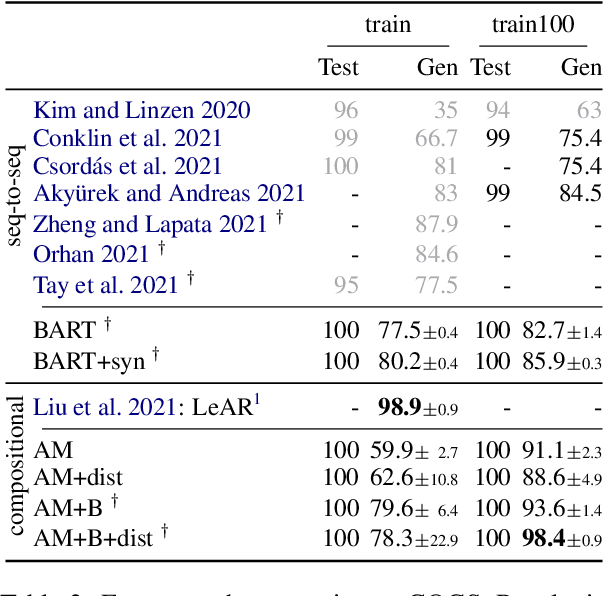
A rapidly growing body of research on compositional generalization investigates the ability of a semantic parser to dynamically recombine linguistic elements seen in training into unseen sequences. We present a systematic comparison of sequence-to-sequence models and models guided by compositional principles on the recent COGS corpus (Kim and Linzen, 2020). Though seq2seq models can perform well on lexical tasks, they perform with near-zero accuracy on structural generalization tasks that require novel syntactic structures; this holds true even when they are trained to predict syntax instead of semantics. In contrast, compositional models achieve near-perfect accuracy on structural generalization; we present new results confirming this from the AM parser (Groschwitz et al., 2021). Our findings show structural generalization is a key measure of compositional generalization and requires models that are aware of complex structure.
Normalizing Compositional Structures Across Graphbanks
Apr 30, 2020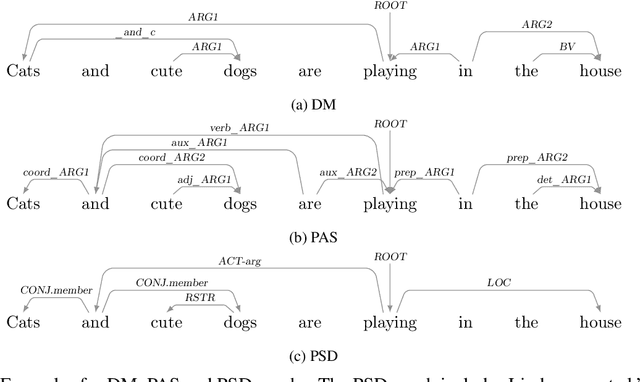
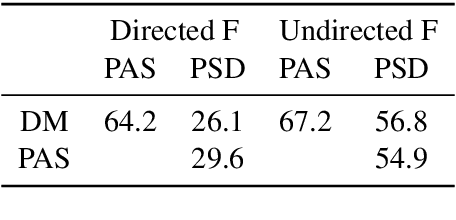

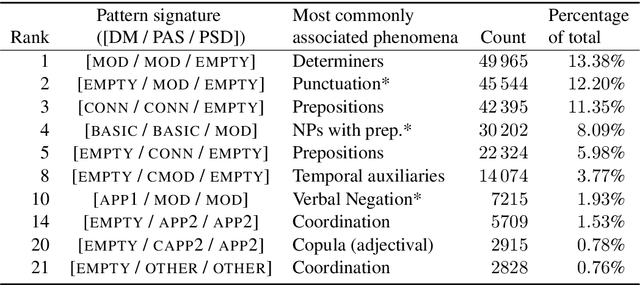
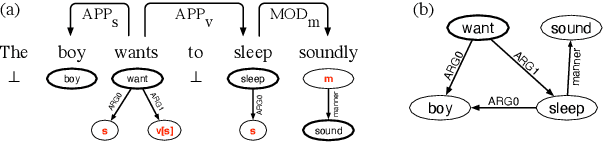
The emergence of a variety of graph-based meaning representations (MRs) has sparked an important conversation about how to adequately represent semantic structure. These MRs exhibit structural differences that reflect different theoretical and design considerations, presenting challenges to uniform linguistic analysis and cross-framework semantic parsing. Here, we ask the question of which design differences between MRs are meaningful and semantically-rooted, and which are superficial. We present a methodology for normalizing discrepancies between MRs at the compositional level (Lindemann et al., 2019), finding that we can normalize the majority of divergent phenomena using linguistically-grounded rules. Our work significantly increases the match in compositional structure between MRs and improves multi-task learning (MTL) in a low-resource setting, demonstrating the usefulness of careful MR design analysis and comparison.