 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvoFusion: Multi-Modal Conversational Diffusion for Co-Speech Gesture Synthesis
Mar 26, 2024



Gestures play a key role in human communication. Recent methods for co-speech gesture generation, while managing to generate beat-aligned motions, struggle generating gestures that are semantically aligned with the utterance. Compared to beat gestures that align naturally to the audio signal, semantically coherent gestures require modeling the complex interactions between the language and human motion, and can be controlled by focusing on certain words. Therefore, we present ConvoFusion, a diffusion-based approach for multi-modal gesture synthesis, which can not only generate gestures based on multi-modal speech inputs, but can also facilitate controllability in gesture synthesis. Our method proposes two guidance objectives that allow the users to modulate the impact of different conditioning modalities (e.g. audio vs text) as well as to choose certain words to be emphasized during gesturing. Our method is versatile in that it can be trained either for generating monologue gestures or even the conversational gestures. To further advance the research on multi-party interactive gestures, the DnD Group Gesture dataset is released, which contains 6 hours of gesture data showing 5 people interacting with one another. We compare our method with several recent works and demonstrate effectiveness of our method on a variety of tasks. We urge the reader to watch our supplementary video at our website.
Imitator: Personalized Speech-driven 3D Facial Animation
Dec 30, 2022Speech-driven 3D facial animation has been widely explored, with applications in gaming, character animation, virtual reality, and telepresence systems. State-of-the-art methods deform the face topology of the target actor to sync the input audio without considering the identity-specific speaking style and facial idiosyncrasies of the target actor, thus, resulting in unrealistic and inaccurate lip movements. To address this, we present Imitator, a speech-driven facial expression synthesis method, which learns identity-specific details from a short input video and produces novel facial expressions matching the identity-specific speaking style and facial idiosyncrasies of the target actor. Specifically, we train a style-agnostic transformer on a large facial expression dataset which we use as a prior for audio-driven facial expressions. Based on this prior, we optimize for identity-specific speaking style based on a short reference video. To train the prior, we introduce a novel loss function based on detected bilabial consonants to ensure plausible lip closures and consequently improve the realism of the generated expressions. Through detailed experiments and a user study, we show that our approach produces temporally coherent facial expressions from input audio while preserving the speaking style of the target actors.
Learning Speech-driven 3D Conversational Gestures from Video
Feb 13, 2021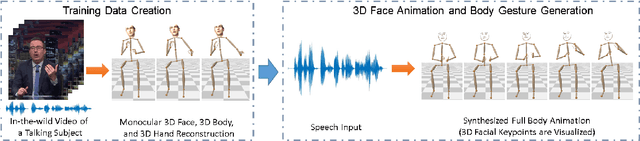
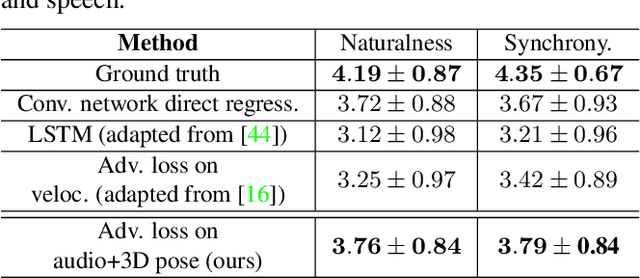
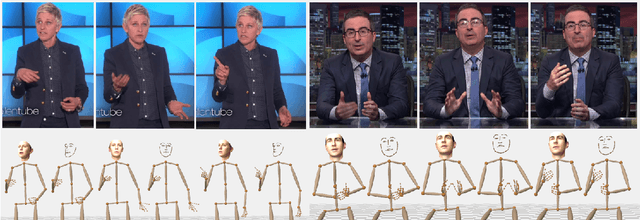
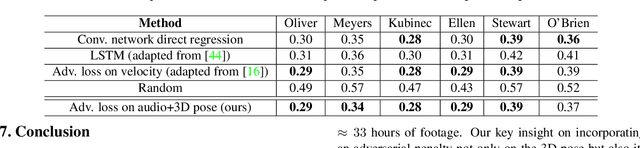
We propose the first approach to automatically and jointly synthesize both the synchronous 3D conversational body and hand gestures, as well as 3D face and head animations, of a virtual character from speech input. Our algorithm uses a CNN architecture that leverages the inherent correlation between facial expression and hand gestures. Synthesis of conversational body gestures is a multi-modal problem since many similar gestures can plausibly accompany the same input speech. To synthesize plausible body gestures in this setting, we train a Generative Adversarial Network (GAN) based model that measures the plausibility of the generated sequences of 3D body motion when paired with the input audio features. We also contribute a new way to create a large corpus of more than 33 hours of annotated body, hand, and face data from in-the-wild videos of talking people. To this end, we apply state-of-the-art monocular approaches for 3D body and hand pose estimation as well as dense 3D face performance capture to the video corpus. In this way, we can train on orders of magnitude more data than previous algorithms that resort to complex in-studio motion capture solutions, and thereby train more expressive synthesis algorithms. Our experiments and user study show the state-of-the-art quality of our speech-synthesized full 3D character animations.
Monocular Real-time Full Body Capture with Inter-part Correlations
Dec 11, 2020
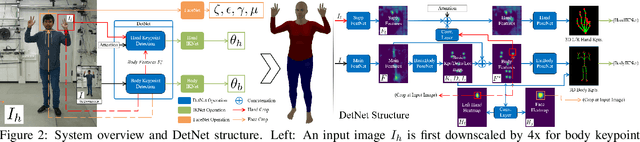
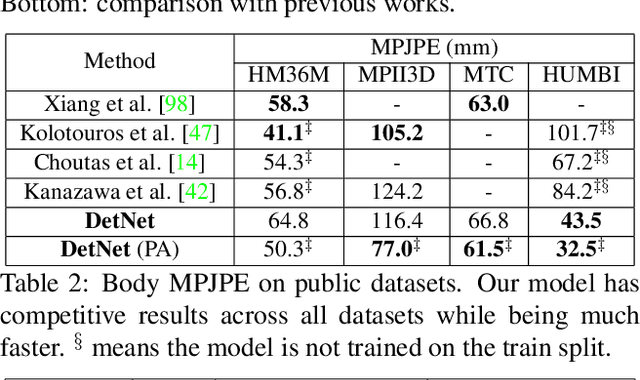
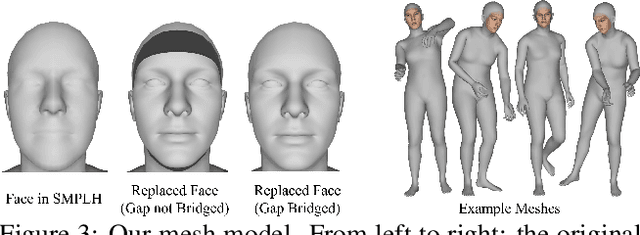
We present the first method for real-time full body capture that estimates shape and motion of body and hands together with a dynamic 3D face model from a single color image. Our approach uses a new neural network architecture that exploits correlations between body and hands at high computational efficiency. Unlike previous works, our approach is jointly trained on multiple datasets focusing on hand, body or face separately, without requiring data where all the parts are annotated at the same time, which is much more difficult to create at sufficient variety. The possibility of such multi-dataset training enables superior generalization ability. In contrast to earlier monocular full body methods, our approach captures more expressive 3D face geometry and color by estimating the shape, expression, albedo and illumination parameters of a statistical face model. Our method achieves competitive accuracy on public benchmarks, while being significantly faster and providing more complete face reconstructions.
Monocular Real-time Hand Shape and Motion Capture using Multi-modal Data
Apr 03, 2020
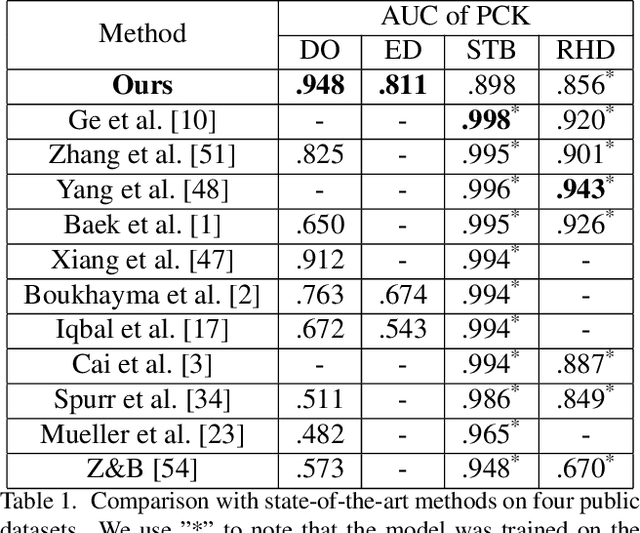
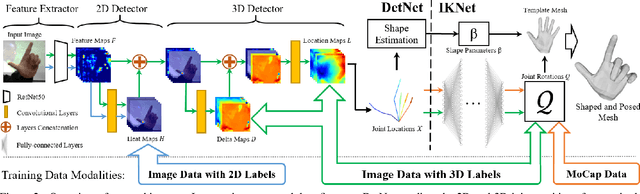
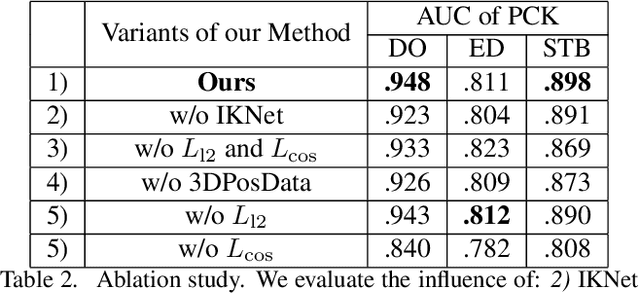
We present a novel method for monocular hand shape and pose estimation at unprecedented runtime performance of 100fps and at state-of-the-art accuracy. This is enabled by a new learning based architecture designed such that it can make use of all the sources of available hand training data: image data with either 2D or 3D annotations, as well as stand-alone 3D animations without corresponding image data. It features a 3D hand joint detection module and an inverse kinematics module which regresses not only 3D joint positions but also maps them to joint rotations in a single feed-forward pass. This output makes the method more directly usable for applications in computer vision and graphics compared to only regressing 3D joint positions. We demonstrate that our architectural design leads to a significant quantitative and qualitative improvement over the state of the art on several challenging benchmarks. Our model is publicly available for future research.
In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations
Apr 05, 2019
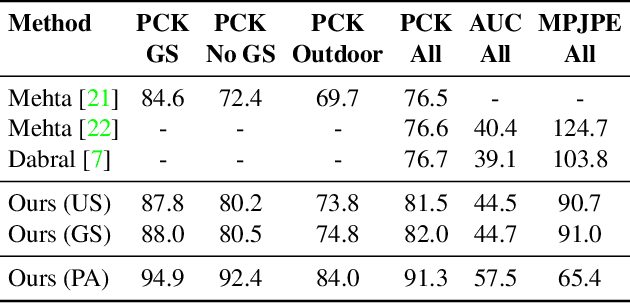

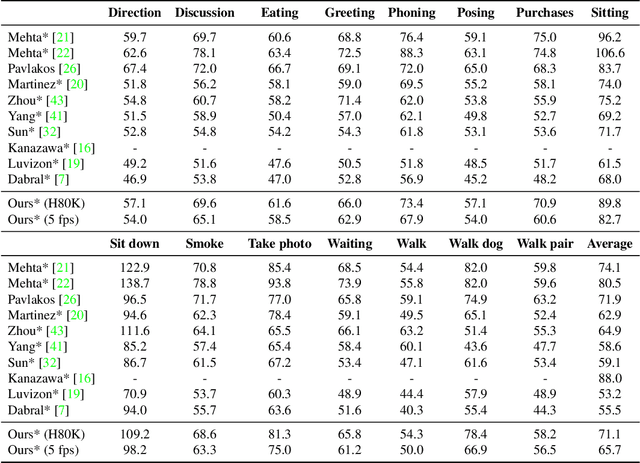
Convolutional Neural Network based approaches for monocular 3D human pose estimation usually require a large amount of training images with 3D pose annotations. While it is feasible to provide 2D joint annotations for large corpora of in-the-wild images with humans, providing accurate 3D annotations to such in-the-wild corpora is hardly feasible in practice. Most existing 3D labelled data sets are either synthetically created or feature in-studio images. 3D pose estimation algorithms trained on such data often have limited ability to generalize to real world scene diversity. We therefore propose a new deep learning based method for monocular 3D human pose estimation that shows high accuracy and generalizes better to in-the-wild scenes. It has a network architecture that comprises a new disentangled hidden space encoding of explicit 2D and 3D features, and uses supervision by a new learned projection model from predicted 3D pose. Our algorithm can be jointly trained on image data with 3D labels and image data with only 2D labels. It achieves state-of-the-art accuracy on challenging in-the-wild data.