 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025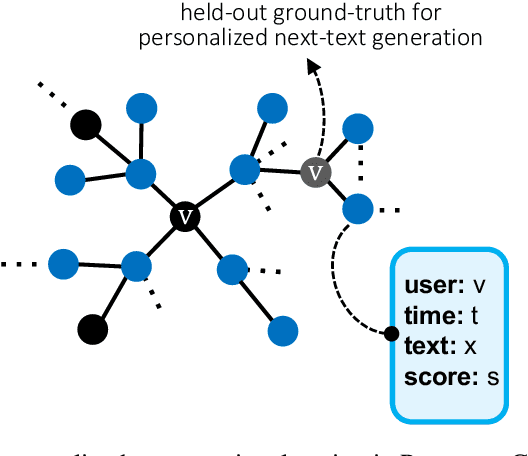
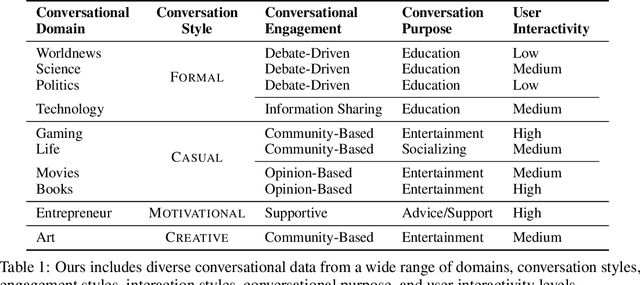
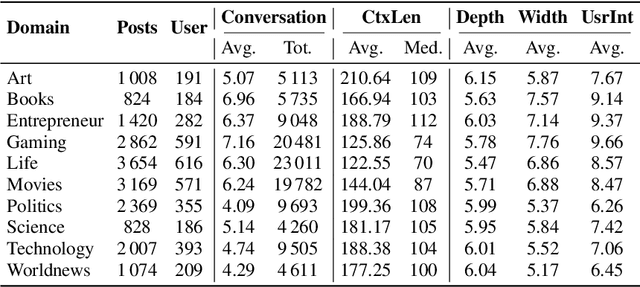
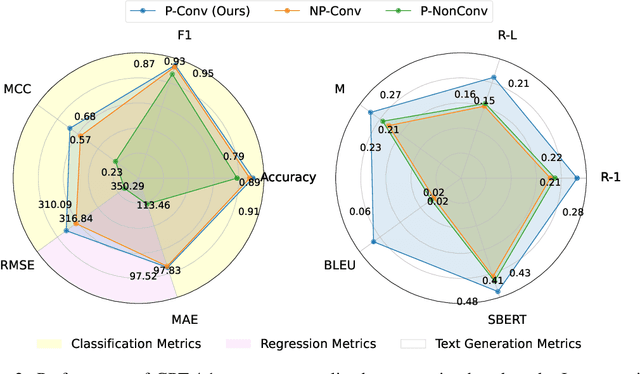
We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
GroomLight: Hybrid Inverse Rendering for Relightable Human Hair Appearance Modeling
Mar 13, 2025We present GroomLight, a novel method for relightable hair appearance modeling from multi-view images. Existing hair capture methods struggle to balance photorealistic rendering with relighting capabilities. Analytical material models, while physically grounded, often fail to fully capture appearance details. Conversely, neural rendering approaches excel at view synthesis but generalize poorly to novel lighting conditions. GroomLight addresses this challenge by combining the strengths of both paradigms. It employs an extended hair BSDF model to capture primary light transport and a light-aware residual model to reconstruct the remaining details. We further propose a hybrid inverse rendering pipeline to optimize both components, enabling high-fidelity relighting, view synthesis, and material editing. Extensive evaluations on real-world hair data demonstrate state-of-the-art performance of our method.
Secure On-Device Video OOD Detection Without Backpropagation
Mar 08, 2025Out-of-Distribution (OOD) detection is critical for ensuring the reliability of machine learning models in safety-critical applications such as autonomous driving and medical diagnosis. While deploying personalized OOD detection directly on edge devices is desirable, it remains challenging due to large model sizes and the computational infeasibility of on-device training. Federated learning partially addresses this but still requires gradient computation and backpropagation, exceeding the capabilities of many edge devices. To overcome these challenges, we propose SecDOOD, a secure cloud-device collaboration framework for efficient on-device OOD detection without requiring device-side backpropagation. SecDOOD utilizes cloud resources for model training while ensuring user data privacy by retaining sensitive information on-device. Central to SecDOOD is a HyperNetwork-based personalized parameter generation module, which adapts cloud-trained models to device-specific distributions by dynamically generating local weight adjustments, effectively combining central and local information without local fine-tuning. Additionally, our dynamic feature sampling and encryption strategy selectively encrypts only the most informative feature channels, largely reducing encryption overhead without compromising detection performance. Extensive experiments across multiple datasets and OOD scenarios demonstrate that SecDOOD achieves performance comparable to fully fine-tuned models, enabling secure, efficient, and personalized OOD detection on resource-limited edge devices. To enhance accessibility and reproducibility, our code is publicly available at https://github.com/Dystopians/SecDOOD.
Treble Counterfactual VLMs: A Causal Approach to Hallucination
Mar 08, 2025

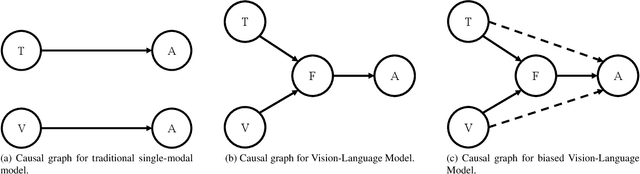

Vision-Language Models (VLMs) have advanced multi-modal tasks like image captioning, visual question answering, and reasoning. However, they often generate hallucinated outputs inconsistent with the visual context or prompt, limiting reliability in critical applications like autonomous driving and medical imaging. Existing studies link hallucination to statistical biases, language priors, and biased feature learning but lack a structured causal understanding. In this work, we introduce a causal perspective to analyze and mitigate hallucination in VLMs. We hypothesize that hallucination arises from unintended direct influences of either the vision or text modality, bypassing proper multi-modal fusion. To address this, we construct a causal graph for VLMs and employ counterfactual analysis to estimate the Natural Direct Effect (NDE) of vision, text, and their cross-modal interaction on the output. We systematically identify and mitigate these unintended direct effects to ensure that responses are primarily driven by genuine multi-modal fusion. Our approach consists of three steps: (1) designing structural causal graphs to distinguish correct fusion pathways from spurious modality shortcuts, (2) estimating modality-specific and cross-modal NDE using perturbed image representations, hallucinated text embeddings, and degraded visual inputs, and (3) implementing a test-time intervention module to dynamically adjust the model's dependence on each modality. Experimental results demonstrate that our method significantly reduces hallucination while preserving task performance, providing a robust and interpretable framework for improving VLM reliability. To enhance accessibility and reproducibility, our code is publicly available at https://github.com/TREE985/Treble-Counterfactual-VLMs.
PuYun: Medium-Range Global Weather Forecasting Using Large Kernel Attention Convolutional Networks
Sep 01, 2024



Accurate weather forecasting is essential for understanding and mitigating weather-related impacts. In this paper, we present PuYun, an autoregressive cascade model that leverages large kernel attention convolutional networks. The model's design inherently supports extended weather prediction horizons while broadening the effective receptive field. The integration of large kernel attention mechanisms within the convolutional layers enhances the model's capacity to capture fine-grained spatial details, thereby improving its predictive accuracy for meteorological phenomena. We introduce PuYun, comprising PuYun-Short for 0-5 day forecasts and PuYun-Medium for 5-10 day predictions. This approach enhances the accuracy of 10-day weather forecasting. Through evaluation, we demonstrate that PuYun-Short alone surpasses the performance of both GraphCast and FuXi-Short in generating accurate 10-day forecasts. Specifically, on the 10th day, PuYun-Short reduces the RMSE for Z500 to 720 $m^2/s^2$, compared to 732 $m^2/s^2$ for GraphCast and 740 $m^2/s^2$ for FuXi-Short. Additionally, the RMSE for T2M is reduced to 2.60 K, compared to 2.63 K for GraphCast and 2.65 K for FuXi-Short. Furthermore, when employing a cascaded approach by integrating PuYun-Short and PuYun-Medium, our method achieves superior results compared to the combined performance of FuXi-Short and FuXi-Medium. On the 10th day, the RMSE for Z500 is further reduced to 638 $m^2/s^2$, compared to 641 $m^2/s^2$ for FuXi. These findings underscore the effectiveness of our model ensemble in advancing medium-range weather prediction. Our training code and model will be open-sourced.
Domain-wise Invariant Learning for Panoptic Scene Graph Generation
Oct 09, 2023Panoptic Scene Graph Generation (PSG) involves the detection of objects and the prediction of their corresponding relationships (predicates). However, the presence of biased predicate annotations poses a significant challenge for PSG models, as it hinders their ability to establish a clear decision boundary among different predicates. This issue substantially impedes the practical utility and real-world applicability of PSG models. To address the intrinsic bias above, we propose a novel framework to infer potentially biased annotations by measuring the predicate prediction risks within each subject-object pair (domain), and adaptively transfer the biased annotations to consistent ones by learning invariant predicate representation embeddings. Experiments show that our method significantly improves the performance of benchmark models, achieving a new state-of-the-art performance, and shows great generalization and effectiveness on PSG dataset.
EgoLocate: Real-time Motion Capture, Localization, and Mapping with Sparse Body-mounted Sensors
May 02, 2023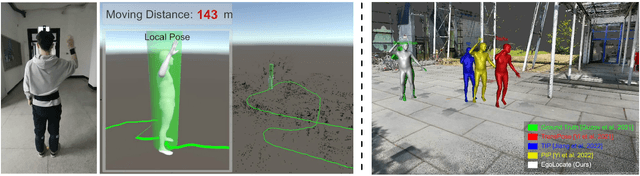



Human and environment sensing are two important topics in Computer Vision and Graphics. Human motion is often captured by inertial sensors, while the environment is mostly reconstructed using cameras. We integrate the two techniques together in EgoLocate, a system that simultaneously performs human motion capture (mocap), localization, and mapping in real time from sparse body-mounted sensors, including 6 inertial measurement units (IMUs) and a monocular phone camera. On one hand, inertial mocap suffers from large translation drift due to the lack of the global positioning signal. EgoLocate leverages image-based simultaneous localization and mapping (SLAM) techniques to locate the human in the reconstructed scene. On the other hand, SLAM often fails when the visual feature is poor. EgoLocate involves inertial mocap to provide a strong prior for the camera motion. Experiments show that localization, a key challenge for both two fields, is largely improved by our technique, compared with the state of the art of the two fields. Our codes are available for research at https://xinyu-yi.github.io/EgoLocate/.
TransPose: Real-time 3D Human Translation and Pose Estimation with Six Inertial Sensors
May 10, 2021

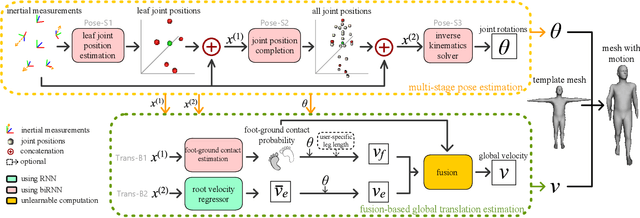

Motion capture is facing some new possibilities brought by the inertial sensing technologies which do not suffer from occlusion or wide-range recordings as vision-based solutions do. However, as the recorded signals are sparse and quite noisy, online performance and global translation estimation turn out to be two key difficulties. In this paper, we present TransPose, a DNN-based approach to perform full motion capture (with both global translations and body poses) from only 6 Inertial Measurement Units (IMUs) at over 90 fps. For body pose estimation, we propose a multi-stage network that estimates leaf-to-full joint positions as intermediate results. This design makes the pose estimation much easier, and thus achieves both better accuracy and lower computation cost. For global translation estimation, we propose a supporting-foot-based method and an RNN-based method to robustly solve for the global translations with a confidence-based fusion technique. Quantitative and qualitative comparisons show that our method outperforms the state-of-the-art learning- and optimization-based methods with a large margin in both accuracy and efficiency. As a purely inertial sensor-based approach, our method is not limited by environmental settings (e.g., fixed cameras), making the capture free from common difficulties such as wide-range motion space and strong occlusion.
Monocular Real-time Full Body Capture with Inter-part Correlations
Dec 11, 2020
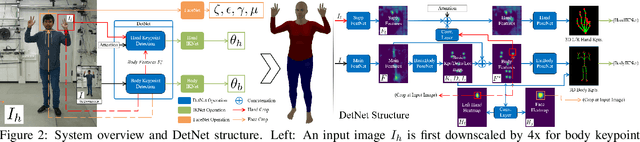
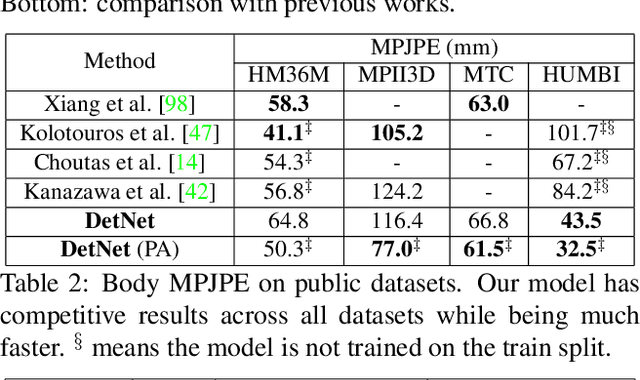
We present the first method for real-time full body capture that estimates shape and motion of body and hands together with a dynamic 3D face model from a single color image. Our approach uses a new neural network architecture that exploits correlations between body and hands at high computational efficiency. Unlike previous works, our approach is jointly trained on multiple datasets focusing on hand, body or face separately, without requiring data where all the parts are annotated at the same time, which is much more difficult to create at sufficient variety. The possibility of such multi-dataset training enables superior generalization ability. In contrast to earlier monocular full body methods, our approach captures more expressive 3D face geometry and color by estimating the shape, expression, albedo and illumination parameters of a statistical face model. Our method achieves competitive accuracy on public benchmarks, while being significantly faster and providing more complete face reconstructions.
Monocular Real-time Hand Shape and Motion Capture using Multi-modal Data
Apr 03, 2020
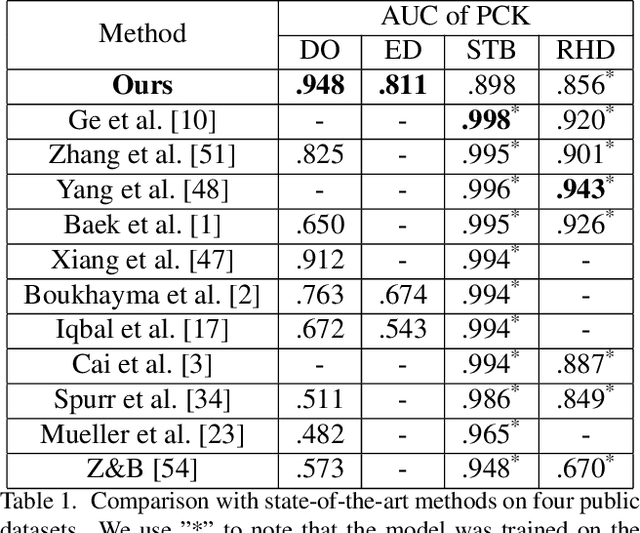
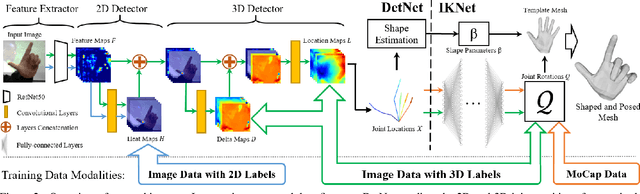
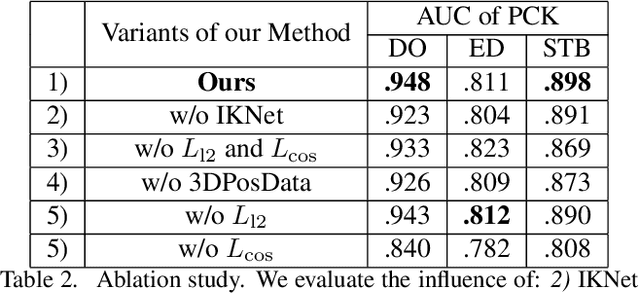
We present a novel method for monocular hand shape and pose estimation at unprecedented runtime performance of 100fps and at state-of-the-art accuracy. This is enabled by a new learning based architecture designed such that it can make use of all the sources of available hand training data: image data with either 2D or 3D annotations, as well as stand-alone 3D animations without corresponding image data. It features a 3D hand joint detection module and an inverse kinematics module which regresses not only 3D joint positions but also maps them to joint rotations in a single feed-forward pass. This output makes the method more directly usable for applications in computer vision and graphics compared to only regressing 3D joint positions. We demonstrate that our architectural design leads to a significant quantitative and qualitative improvement over the state of the art on several challenging benchmarks. Our model is publicly available for future research.