 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Reality Gap: Zero-Shot Sim-to-Real Deployment for Dexterous Force-Based Grasping and Manipulation
Jan 06, 2026Human-like dexterous hands with multiple fingers offer human-level manipulation capabilities, but training control policies that can directly deploy on real hardware remains difficult due to contact-rich physics and imperfect actuation. We close this gap with a practical sim-to-real reinforcement learning (RL) framework that utilizes dense tactile feedback combined with joint torque sensing to explicitly regulate physical interactions. To enable effective sim-to-real transfer, we introduce (i) a computationally fast tactile simulation that computes distances between dense virtual tactile units and the object via parallel forward kinematics, providing high-rate, high-resolution touch signals needed by RL; (ii) a current-to-torque calibration that eliminates the need for torque sensors on dexterous hands by mapping motor current to joint torque; and (iii) actuator dynamics modeling to bridge the actuation gaps with randomization of non-ideal effects such as backlash, torque-speed saturation. Using an asymmetric actor-critic PPO pipeline trained entirely in simulation, our policies deploy directly to a five-finger hand. The resulting policies demonstrated two essential skills: (1) command-based, controllable grasp force tracking, and (2) reorientation of objects in the hand, both of which were robustly executed without fine-tuning on the robot. By combining tactile and torque in the observation space with effective sensing/actuation modeling, our system provides a practical solution to achieve reliable dexterous manipulation. To our knowledge, this is the first demonstration of controllable grasping on a multi-finger dexterous hand trained entirely in simulation and transferred zero-shot on real hardware.
DemoBot: Efficient Learning of Bimanual Manipulation with Dexterous Hands From Third-Person Human Videos
Jan 04, 2026This work presents DemoBot, a learning framework that enables a dual-arm, multi-finger robotic system to acquire complex manipulation skills from a single unannotated RGB-D video demonstration. The method extracts structured motion trajectories of both hands and objects from raw video data. These trajectories serve as motion priors for a novel reinforcement learning (RL) pipeline that learns to refine them through contact-rich interactions, thereby eliminating the need to learn from scratch. To address the challenge of learning long-horizon manipulation skills, we introduce: (1) Temporal-segment based RL to enforce temporal alignment of the current state with demonstrations; (2) Success-Gated Reset strategy to balance the refinement of readily acquired skills and the exploration of subsequent task stages; and (3) Event-Driven Reward curriculum with adaptive thresholding to guide the RL learning of high-precision manipulation. The novel video processing and RL framework successfully achieved long-horizon synchronous and asynchronous bimanual assembly tasks, offering a scalable approach for direct skill acquisition from human videos.
DiffCap: Diffusion-based Real-time Human Motion Capture using Sparse IMUs and a Monocular Camera
Aug 08, 2025
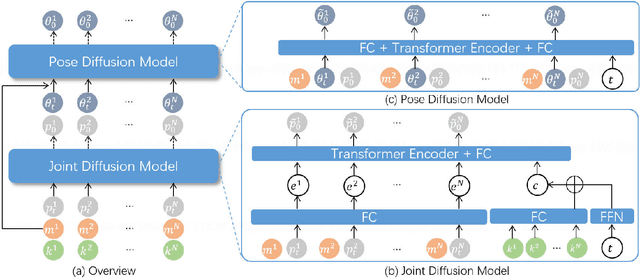
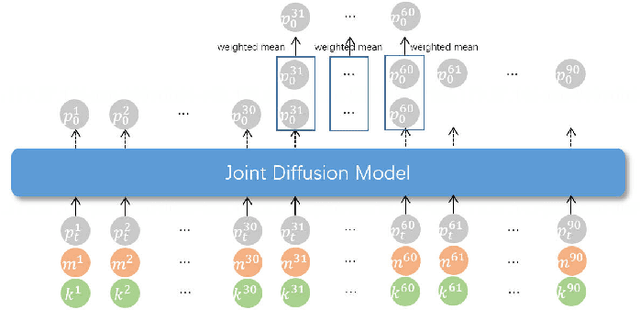

Combining sparse IMUs and a monocular camera is a new promising setting to perform real-time human motion capture. This paper proposes a diffusion-based solution to learn human motion priors and fuse the two modalities of signals together seamlessly in a unified framework. By delicately considering the characteristics of the two signals, the sequential visual information is considered as a whole and transformed into a condition embedding, while the inertial measurement is concatenated with the noisy body pose frame by frame to construct a sequential input for the diffusion model. Firstly, we observe that the visual information may be unavailable in some frames due to occlusions or subjects moving out of the camera view. Thus incorporating the sequential visual features as a whole to get a single feature embedding is robust to the occasional degenerations of visual information in those frames. On the other hand, the IMU measurements are robust to occlusions and always stable when signal transmission has no problem. So incorporating them frame-wisely could better explore the temporal information for the system. Experiments have demonstrated the effectiveness of the system design and its state-of-the-art performance in pose estimation compared with the previous works. Our codes are available for research at https://shaohua-pan.github.io/diffcap-page.
Transformer IMU Calibrator: Dynamic On-body IMU Calibration for Inertial Motion Capture
Jun 12, 2025In this paper, we propose a novel dynamic calibration method for sparse inertial motion capture systems, which is the first to break the restrictive absolute static assumption in IMU calibration, i.e., the coordinate drift RG'G and measurement offset RBS remain constant during the entire motion, thereby significantly expanding their application scenarios. Specifically, we achieve real-time estimation of RG'G and RBS under two relaxed assumptions: i) the matrices change negligibly in a short time window; ii) the human movements/IMU readings are diverse in such a time window. Intuitively, the first assumption reduces the number of candidate matrices, and the second assumption provides diverse constraints, which greatly reduces the solution space and allows for accurate estimation of RG'G and RBS from a short history of IMU readings in real time. To achieve this, we created synthetic datasets of paired RG'G, RBS matrices and IMU readings, and learned their mappings using a Transformer-based model. We also designed a calibration trigger based on the diversity of IMU readings to ensure that assumption ii) is met before applying our method. To our knowledge, we are the first to achieve implicit IMU calibration (i.e., seamlessly putting IMUs into use without the need for an explicit calibration process), as well as the first to enable long-term and accurate motion capture using sparse IMUs. The code and dataset are available at https://github.com/ZuoCX1996/TIC.
Hand-Object Interaction Controller (HOIC): Deep Reinforcement Learning for Reconstructing Interactions with Physics
May 04, 2024
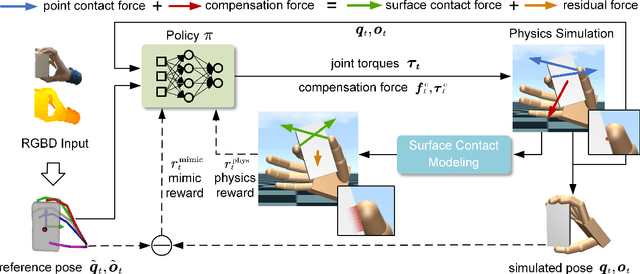
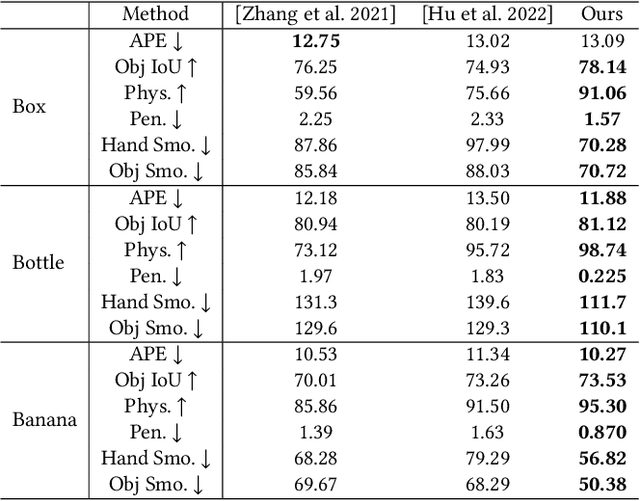
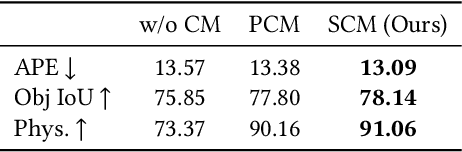
Hand manipulating objects is an important interaction motion in our daily activities. We faithfully reconstruct this motion with a single RGBD camera by a novel deep reinforcement learning method to leverage physics. Firstly, we propose object compensation control which establishes direct object control to make the network training more stable. Meanwhile, by leveraging the compensation force and torque, we seamlessly upgrade the simple point contact model to a more physical-plausible surface contact model, further improving the reconstruction accuracy and physical correctness. Experiments indicate that without involving any heuristic physical rules, this work still successfully involves physics in the reconstruction of hand-object interactions which are complex motions hard to imitate with deep reinforcement learning. Our code and data are available at https://github.com/hu-hy17/HOIC.
Fusing Monocular Images and Sparse IMU Signals for Real-time Human Motion Capture
Sep 01, 2023Either RGB images or inertial signals have been used for the task of motion capture (mocap), but combining them together is a new and interesting topic. We believe that the combination is complementary and able to solve the inherent difficulties of using one modality input, including occlusions, extreme lighting/texture, and out-of-view for visual mocap and global drifts for inertial mocap. To this end, we propose a method that fuses monocular images and sparse IMUs for real-time human motion capture. Our method contains a dual coordinate strategy to fully explore the IMU signals with different goals in motion capture. To be specific, besides one branch transforming the IMU signals to the camera coordinate system to combine with the image information, there is another branch to learn from the IMU signals in the body root coordinate system to better estimate body poses. Furthermore, a hidden state feedback mechanism is proposed for both two branches to compensate for their own drawbacks in extreme input cases. Thus our method can easily switch between the two kinds of signals or combine them in different cases to achieve a robust mocap. %The two divided parts can help each other for better mocap results under different conditions. Quantitative and qualitative results demonstrate that by delicately designing the fusion method, our technique significantly outperforms the state-of-the-art vision, IMU, and combined methods on both global orientation and local pose estimation. Our codes are available for research at https://shaohua-pan.github.io/robustcap-page/.
EgoLocate: Real-time Motion Capture, Localization, and Mapping with Sparse Body-mounted Sensors
May 02, 2023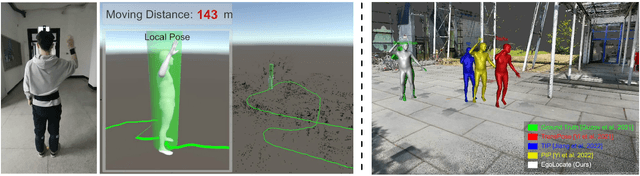



Human and environment sensing are two important topics in Computer Vision and Graphics. Human motion is often captured by inertial sensors, while the environment is mostly reconstructed using cameras. We integrate the two techniques together in EgoLocate, a system that simultaneously performs human motion capture (mocap), localization, and mapping in real time from sparse body-mounted sensors, including 6 inertial measurement units (IMUs) and a monocular phone camera. On one hand, inertial mocap suffers from large translation drift due to the lack of the global positioning signal. EgoLocate leverages image-based simultaneous localization and mapping (SLAM) techniques to locate the human in the reconstructed scene. On the other hand, SLAM often fails when the visual feature is poor. EgoLocate involves inertial mocap to provide a strong prior for the camera motion. Experiments show that localization, a key challenge for both two fields, is largely improved by our technique, compared with the state of the art of the two fields. Our codes are available for research at https://xinyu-yi.github.io/EgoLocate/.
Physical Interaction: Reconstructing Hand-object Interactions with Physics
Sep 22, 2022

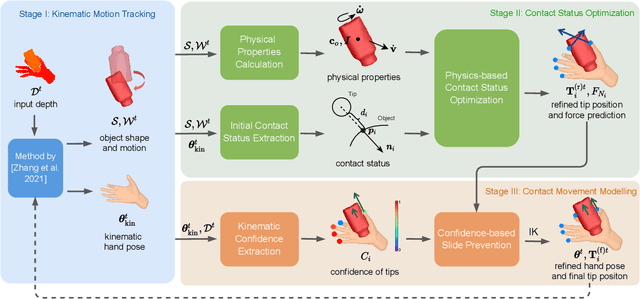

Single view-based reconstruction of hand-object interaction is challenging due to the severe observation missing caused by occlusions. This paper proposes a physics-based method to better solve the ambiguities in the reconstruction. It first proposes a force-based dynamic model of the in-hand object, which not only recovers the unobserved contacts but also solves for plausible contact forces. Next, a confidence-based slide prevention scheme is proposed, which combines both the kinematic confidences and the contact forces to jointly model static and sliding contact motion. Qualitative and quantitative experiments show that the proposed technique reconstructs both physically plausible and more accurate hand-object interaction and estimates plausible contact forces in real-time with a single RGBD sensor.
TransPose: Real-time 3D Human Translation and Pose Estimation with Six Inertial Sensors
May 10, 2021

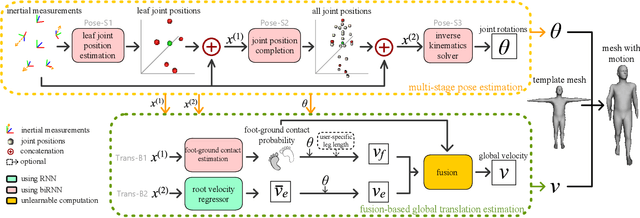

Motion capture is facing some new possibilities brought by the inertial sensing technologies which do not suffer from occlusion or wide-range recordings as vision-based solutions do. However, as the recorded signals are sparse and quite noisy, online performance and global translation estimation turn out to be two key difficulties. In this paper, we present TransPose, a DNN-based approach to perform full motion capture (with both global translations and body poses) from only 6 Inertial Measurement Units (IMUs) at over 90 fps. For body pose estimation, we propose a multi-stage network that estimates leaf-to-full joint positions as intermediate results. This design makes the pose estimation much easier, and thus achieves both better accuracy and lower computation cost. For global translation estimation, we propose a supporting-foot-based method and an RNN-based method to robustly solve for the global translations with a confidence-based fusion technique. Quantitative and qualitative comparisons show that our method outperforms the state-of-the-art learning- and optimization-based methods with a large margin in both accuracy and efficiency. As a purely inertial sensor-based approach, our method is not limited by environmental settings (e.g., fixed cameras), making the capture free from common difficulties such as wide-range motion space and strong occlusion.