 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEPHand: View-Efficient Photometric Hand Performance Capture at Scale
Jun 18, 2026Robust, high-fidelity 3D hand capture, while fundamental to digital human creation, remains challenging with practical multi-view systems that balance rich photometry with the geometric ambiguities of reconstruction arising from limited viewpoint density. This paper presents an end-to-end pipeline for dynamic hand performance capture and registration, specifically designed for view-efficient setups ($\sim$20 views). We address key challenges with two primary innovations. First, to overcome reconstruction difficulties like limited view overlap and background clutter, our mask-free neural method robustly extracts detailed hand geometry and appearance from unmasked images using scene parameterization and scenario-specific density regularization. Second, addressing registration challenges such as accurately capturing non-linear skin deformations and ensuring plausible results during severe self-contact, we propose a physics-inspired framework. It aligns reconstructions to a personalized hand model by optimizing intrinsic volumetric offsets within its canonical tetrahedral mesh, alongside pose parameters. This approach, supported by robust losses and optimization, captures fine surface deformations, ensures plausible results under severe articulation and self-contact, and demonstrates strong tolerance to input noise. We demonstrate the scalability and robustness of our automated pipeline on an extensive dataset of over 12,000 sequences, from which we also derive a large-scale, high-quality synthetic 2D/3D hand dataset for training downstream tasks. This showcases its effectiveness for single hands, intricate two-hand interactions, and natural hand-object manipulations. Our method achieves state-of-the-art reconstruction fidelity in view-efficient, unmasked scenarios and highly accurate registration. Our project page are available at https://vephand.github.io/.
DSA: Dynamic Step Allocation for Fast Autoregressive Video Generation
Jun 03, 2026Video diffusion transformers have achieved state-of-the-art visual quality, but their high inference cost remains a major bottleneck for real-time applications. Recent distillation frameworks produce autoregressive video diffusion models with reduced latency, yet these models still use a fixed number of denoising steps per frame, wasting computation on predictable frames and under-refining challenging ones. We present DSA, a confidence-guided adaptive computation framework for AR video diffusion. DSA introduces a lightweight confidence head, trained jointly with the generator under a distribution-matching distillation objective, to estimate per-frame denoising reliability. At inference, this confidence signal dynamically adjusts the number of diffusion steps: simple frames terminate early for speed, while complex frames receive additional refinement. Our method requires no extra video data, no heuristics, and little architectural modification. Experiments show that DSA achieves real-time autoregressive video generation, reaching 22.63 FPS with sub-second latency on H100 GPUs, while maintaining competitive or superior VBench quality compared to recent autoregressive and bidirectional video diffusion models. Our results demonstrate that confidence-guided adaptive sampling provides an effective and practical path toward interactive video generation.
Frontier-Eng: Benchmarking Self-Evolving Agents on Real-World Engineering Tasks with Generative Optimization
Apr 14, 2026Current LLM agent benchmarks, which predominantly focus on binary pass/fail tasks such as code generation or search-based question answering, often neglect the value of real-world engineering that is often captured through the iterative optimization of feasible designs. To this end, we introduce Frontier-Eng, a human-verified benchmark for generative optimization -- an iterative propose-execute-evaluate loop in which an agent generates candidate artifacts, receives executable verifier feedback, and revises them under a fixed interaction budget -- spanning $47$ tasks across five broad engineering categories. Unlike previous suites, Frontier-Eng tasks are grounded in industrial-grade simulators and verifiers that provide continuous reward signals and enforce hard feasibility constraints under constrained budgets. We evaluate eight frontier language models using representative search frameworks, finding that while Claude 4.6 Opus achieves the most robust performance, the benchmark remains challenging for all models. Our analysis suggests a dual power-law decay in improvement frequency ($\sim$ 1/iteration) and magnitude ($\sim$ 1/improvement count). We further show that although width improves parallelism and diversity, depth remains crucial for hard-won improvements under a fixed budget. Frontier-Eng establishes a new standard for assessing the capacity of AI agents to integrate domain knowledge with executable feedback to solve complex, open-ended engineering problems.
The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
Apr 02, 2026Latent space is rapidly emerging as a native substrate for language-based models. While modern systems are still commonly understood through explicit token-level generation, an increasing body of work shows that many critical internal processes are more naturally carried out in continuous latent space than in human-readable verbal traces. This shift is driven by the structural limitations of explicit-space computation, including linguistic redundancy, discretization bottlenecks, sequential inefficiency, and semantic loss. This survey aims to provide a unified and up-to-date landscape of latent space in language-based models. We organize the survey into five sequential perspectives: Foundation, Evolution, Mechanism, Ability, and Outlook. We begin by delineating the scope of latent space, distinguishing it from explicit or verbal space and from the latent spaces commonly studied in generative visual models. We then trace the field's evolution from early exploratory efforts to the current large-scale expansion. To organize the technical landscape, we examine existing work through the complementary lenses of mechanism and ability. From the perspective of Mechanism, we identify four major lines of development: Architecture, Representation, Computation, and Optimization. From the perspective of Ability, we show how latent space supports a broad capability spectrum spanning Reasoning, Planning, Modeling, Perception, Memory, Collaboration, and Embodiment. Beyond consolidation, we discuss the key open challenges, and outline promising directions for future research. We hope this survey serves not only as a reference for existing work, but also as a foundation for understanding latent space as a general computational and systems paradigm for next-generation intelligence.
RoboRouter: Training-Free Policy Routing for Robotic Manipulation
Mar 12, 2026Research on robotic manipulation has developed a diverse set of policy paradigms, including vision-language-action (VLA) models, vision-action (VA) policies, and code-based compositional approaches. Concrete policies typically attain high success rates on specific task distributions but lim-ited generalization beyond it. Rather than proposing an other monolithic policy, we propose to leverage the complementary strengths of existing approaches through intelligent policy routing. We introduce RoboRouter, a training-free framework that maintains a pool of heterogeneous policies and learns to select the best-performing policy for each task through accumulated execution experience. Given a new task, RoboRouter constructs a semantic task representation, retrieves historical records of similar tasks, predicts the optimal policy choice without requiring trial-and-error, and incorporates structured feedback to refine subsequent routing decisions. Integrating a new policy into the system requires only lightweight evaluation and incurs no training overhead. Across simulation benchmark and real-world evaluations, RoboRouter consistently outperforms than in-dividual policies, improving average success rate by more than 3% in simulation and over 13% in real-world settings, while preserving execution efficiency. Our results demonstrate that intelligent routing across heterogeneous, off-the-shelf policies provides a practical and scalable pathway toward building more capable robotic systems.
RoboStriker: Hierarchical Decision-Making for Autonomous Humanoid Boxing
Jan 30, 2026Achieving human-level competitive intelligence and physical agility in humanoid robots remains a major challenge, particularly in contact-rich and highly dynamic tasks such as boxing. While Multi-Agent Reinforcement Learning (MARL) offers a principled framework for strategic interaction, its direct application to humanoid control is hindered by high-dimensional contact dynamics and the absence of strong physical motion priors. We propose RoboStriker, a hierarchical three-stage framework that enables fully autonomous humanoid boxing by decoupling high-level strategic reasoning from low-level physical execution. The framework first learns a comprehensive repertoire of boxing skills by training a single-agent motion tracker on human motion capture data. These skills are subsequently distilled into a structured latent manifold, regularized by projecting the Gaussian-parameterized distribution onto a unit hypersphere. This topological constraint effectively confines exploration to the subspace of physically plausible motions. In the final stage, we introduce Latent-Space Neural Fictitious Self-Play (LS-NFSP), where competing agents learn competitive tactics by interacting within the latent action space rather than the raw motor space, significantly stabilizing multi-agent training. Experimental results demonstrate that RoboStriker achieves superior competitive performance in simulation and exhibits sim-to-real transfer. Our website is available at RoboStriker.
T2AV-Compass: Towards Unified Evaluation for Text-to-Audio-Video Generation
Dec 24, 2025Text-to-Audio-Video (T2AV) generation aims to synthesize temporally coherent video and semantically synchronized audio from natural language, yet its evaluation remains fragmented, often relying on unimodal metrics or narrowly scoped benchmarks that fail to capture cross-modal alignment, instruction following, and perceptual realism under complex prompts. To address this limitation, we present T2AV-Compass, a unified benchmark for comprehensive evaluation of T2AV systems, consisting of 500 diverse and complex prompts constructed via a taxonomy-driven pipeline to ensure semantic richness and physical plausibility. Besides, T2AV-Compass introduces a dual-level evaluation framework that integrates objective signal-level metrics for video quality, audio quality, and cross-modal alignment with a subjective MLLM-as-a-Judge protocol for instruction following and realism assessment. Extensive evaluation of 11 representative T2AVsystems reveals that even the strongest models fall substantially short of human-level realism and cross-modal consistency, with persistent failures in audio realism, fine-grained synchronization, instruction following, etc. These results indicate significant improvement room for future models and highlight the value of T2AV-Compass as a challenging and diagnostic testbed for advancing text-to-audio-video generation.
Ego4o: Egocentric Human Motion Capture and Understanding from Multi-Modal Input
Apr 11, 2025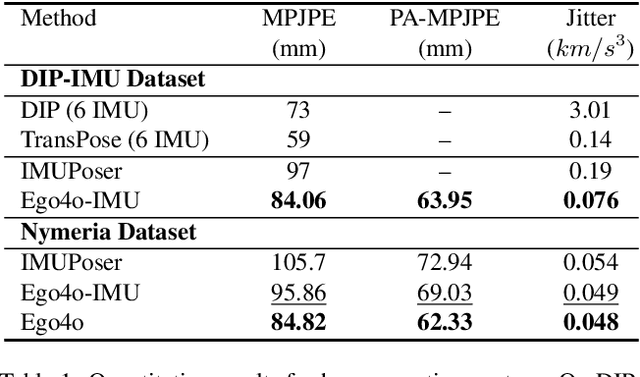
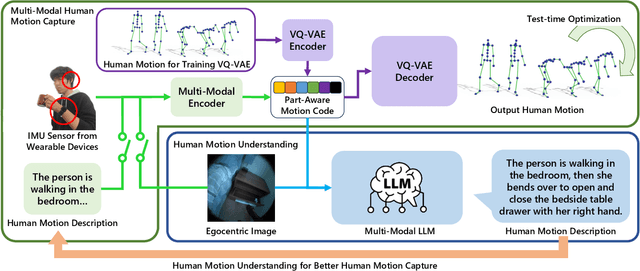

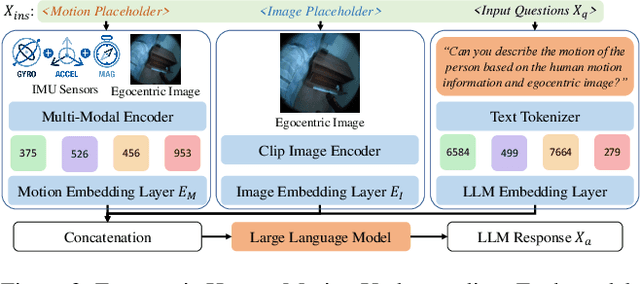
This work focuses on tracking and understanding human motion using consumer wearable devices, such as VR/AR headsets, smart glasses, cellphones, and smartwatches. These devices provide diverse, multi-modal sensor inputs, including egocentric images, and 1-3 sparse IMU sensors in varied combinations. Motion descriptions can also accompany these signals. The diverse input modalities and their intermittent availability pose challenges for consistent motion capture and understanding. In this work, we present Ego4o (o for omni), a new framework for simultaneous human motion capture and understanding from multi-modal egocentric inputs. This method maintains performance with partial inputs while achieving better results when multiple modalities are combined. First, the IMU sensor inputs, the optional egocentric image, and text description of human motion are encoded into the latent space of a motion VQ-VAE. Next, the latent vectors are sent to the VQ-VAE decoder and optimized to track human motion. When motion descriptions are unavailable, the latent vectors can be input into a multi-modal LLM to generate human motion descriptions, which can further enhance motion capture accuracy. Quantitative and qualitative evaluations demonstrate the effectiveness of our method in predicting accurate human motion and high-quality motion descriptions.
Exploring Intrinsic Language-specific Subspaces in Fine-tuning Multilingual Neural Machine Translation
Sep 08, 2024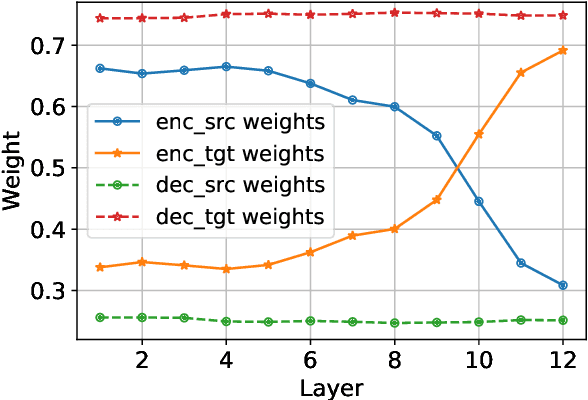
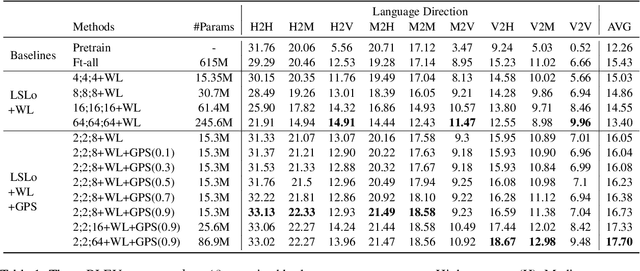
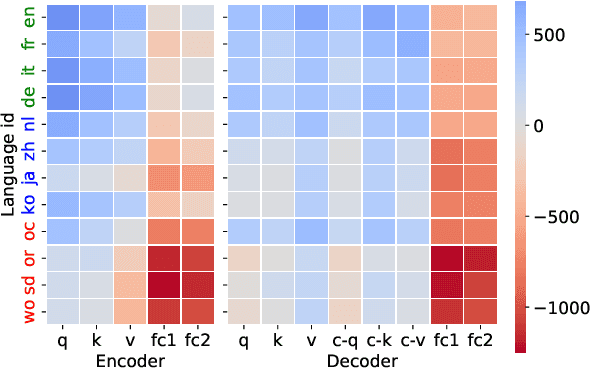

Multilingual neural machine translation models support fine-tuning hundreds of languages simultaneously. However, fine-tuning on full parameters solely is inefficient potentially leading to negative interactions among languages. In this work, we demonstrate that the fine-tuning for a language occurs in its intrinsic language-specific subspace with a tiny fraction of entire parameters. Thus, we propose language-specific LoRA to isolate intrinsic language-specific subspaces. Furthermore, we propose architecture learning techniques and introduce a gradual pruning schedule during fine-tuning to exhaustively explore the optimal setting and the minimal intrinsic subspaces for each language, resulting in a lightweight yet effective fine-tuning procedure. The experimental results on a 12-language subset and a 30-language subset of FLORES-101 show that our methods not only outperform full-parameter fine-tuning up to 2.25 spBLEU scores but also reduce trainable parameters to $0.4\%$ for high and medium-resource languages and $1.6\%$ for low-resource ones.
Achieving More with Less: A Tensor-Optimization-Powered Ensemble Method
Aug 06, 2024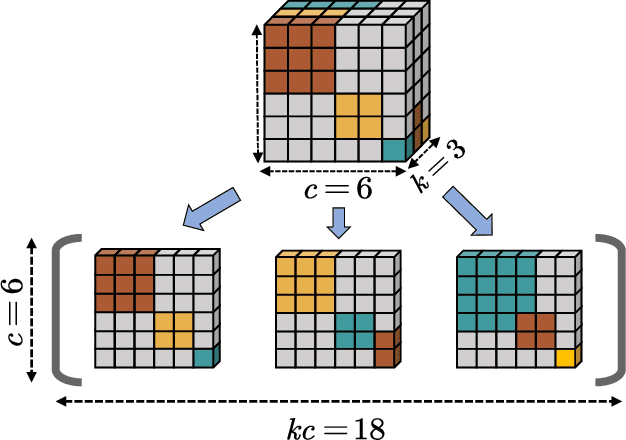
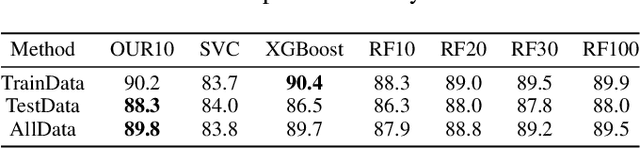
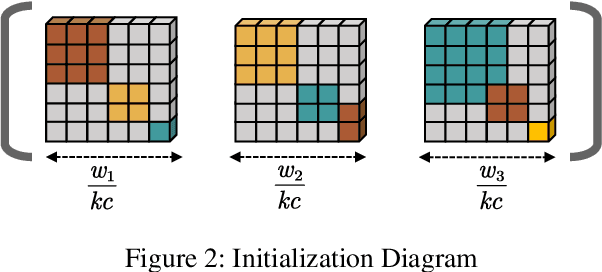
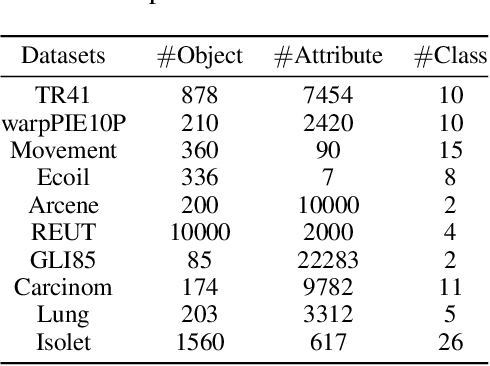
Ensemble learning is a method that leverages weak learners to produce a strong learner. However, obtaining a large number of base learners requires substantial time and computational resources. Therefore, it is meaningful to study how to achieve the performance typically obtained with many base learners using only a few. We argue that to achieve this, it is essential to enhance both classification performance and generalization ability during the ensemble process. To increase model accuracy, each weak base learner needs to be more efficiently integrated. It is observed that different base learners exhibit varying levels of accuracy in predicting different classes. To capitalize on this, we introduce confidence tensors $\tilde{\mathbf{\Theta}}$ and $\tilde{\mathbf{\Theta}}_{rst}$ signifies that the $t$-th base classifier assigns the sample to class $r$ while it actually belongs to class $s$. To the best of our knowledge, this is the first time an evaluation of the performance of base classifiers across different classes has been proposed. The proposed confidence tensor compensates for the strengths and weaknesses of each base classifier in different classes, enabling the method to achieve superior results with a smaller number of base learners. To enhance generalization performance, we design a smooth and convex objective function that leverages the concept of margin, making the strong learner more discriminative. Furthermore, it is proved that in gradient matrix of the loss function, the sum of each column's elements is zero, allowing us to solve a constrained optimization problem using gradient-based methods. We then compare our algorithm with random forests of ten times the size and other classical methods across numerous datasets, demonstrating the superiority of our approach.