 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGH: Dynamic Gaussian Hair
Dec 18, 2025The creation of photorealistic dynamic hair remains a major challenge in digital human modeling because of the complex motions, occlusions, and light scattering. Existing methods often resort to static capture and physics-based models that do not scale as they require manual parameter fine-tuning to handle the diversity of hairstyles and motions, and heavy computation to obtain high-quality appearance. In this paper, we present Dynamic Gaussian Hair (DGH), a novel framework that efficiently learns hair dynamics and appearance. We propose: (1) a coarse-to-fine model that learns temporally coherent hair motion dynamics across diverse hairstyles; (2) a strand-guided optimization module that learns a dynamic 3D Gaussian representation for hair appearance with support for differentiable rendering, enabling gradient-based learning of view-consistent appearance under motion. Unlike prior simulation-based pipelines, our approach is fully data-driven, scales with training data, and generalizes across various hairstyles and head motion sequences. Additionally, DGH can be seamlessly integrated into a 3D Gaussian avatar framework, enabling realistic, animatable hair for high-fidelity avatar representation. DGH achieves promising geometry and appearance results, providing a scalable, data-driven alternative to physics-based simulation and rendering.
Motion Graph Unleashed: A Novel Approach to Video Prediction
Oct 29, 2024We introduce motion graph, a novel approach to the video prediction problem, which predicts future video frames from limited past data. The motion graph transforms patches of video frames into interconnected graph nodes, to comprehensively describe the spatial-temporal relationships among them. This representation overcomes the limitations of existing motion representations such as image differences, optical flow, and motion matrix that either fall short in capturing complex motion patterns or suffer from excessive memory consumption. We further present a video prediction pipeline empowered by motion graph, exhibiting substantial performance improvements and cost reductions. Experiments on various datasets, including UCF Sports, KITTI and Cityscapes, highlight the strong representative ability of motion graph. Especially on UCF Sports, our method matches and outperforms the SOTA methods with a significant reduction in model size by 78% and a substantial decrease in GPU memory utilization by 47%.
Boosting Generalizability towards Zero-Shot Cross-Dataset Single-Image Indoor Depth by Meta-Initialization
Sep 04, 2024Indoor robots rely on depth to perform tasks like navigation or obstacle detection, and single-image depth estimation is widely used to assist perception. Most indoor single-image depth prediction focuses less on model generalizability to unseen datasets, concerned with in-the-wild robustness for system deployment. This work leverages gradient-based meta-learning to gain higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied meta-learning of image classification associated with explicit class labels, no explicit task boundaries exist for continuous depth values tied to highly varying indoor environments regarding object arrangement and scene composition. We propose fine-grained task that treats each RGB-D mini-batch as a task in our meta-learning formulation. We first show that our method on limited data induces a much better prior (max 27.8% in RMSE). Then, finetuning on meta-learned initialization consistently outperforms baselines without the meta approach. Aiming at generalization, we propose zero-shot cross-dataset protocols and validate higher generalizability induced by our meta-initialization, as a simple and useful plugin to many existing depth estimation methods. The work at the intersection of depth and meta-learning potentially drives both research to step closer to practical robotic and machine perception usage.
InSpaceType: Dataset and Benchmark for Reconsidering Cross-Space Type Performance in Indoor Monocular Depth
Aug 25, 2024Indoor monocular depth estimation helps home automation, including robot navigation or AR/VR for surrounding perception. Most previous methods primarily experiment with the NYUv2 Dataset and concentrate on the overall performance in their evaluation. However, their robustness and generalization to diversely unseen types or categories for indoor spaces (spaces types) have yet to be discovered. Researchers may empirically find degraded performance in a released pretrained model on custom data or less-frequent types. This paper studies the common but easily overlooked factor-space type and realizes a model's performance variances across spaces. We present InSpaceType Dataset, a high-quality RGBD dataset for general indoor scenes, and benchmark 13 recent state-of-the-art methods on InSpaceType. Our examination shows that most of them suffer from performance imbalance between head and tailed types, and some top methods are even more severe. The work reveals and analyzes underlying bias in detail for transparency and robustness. We extend the analysis to a total of 4 datasets and discuss the best practice in synthetic data curation for training indoor monocular depth. Further, dataset ablation is conducted to find out the key factor in generalization. This work marks the first in-depth investigation of performance variances across space types and, more importantly, releases useful tools, including datasets and codes, to closely examine your pretrained depth models. Data and code: https://depthcomputation.github.io/DepthPublic/
GaussianFlow: Splatting Gaussian Dynamics for 4D Content Creation
Mar 19, 2024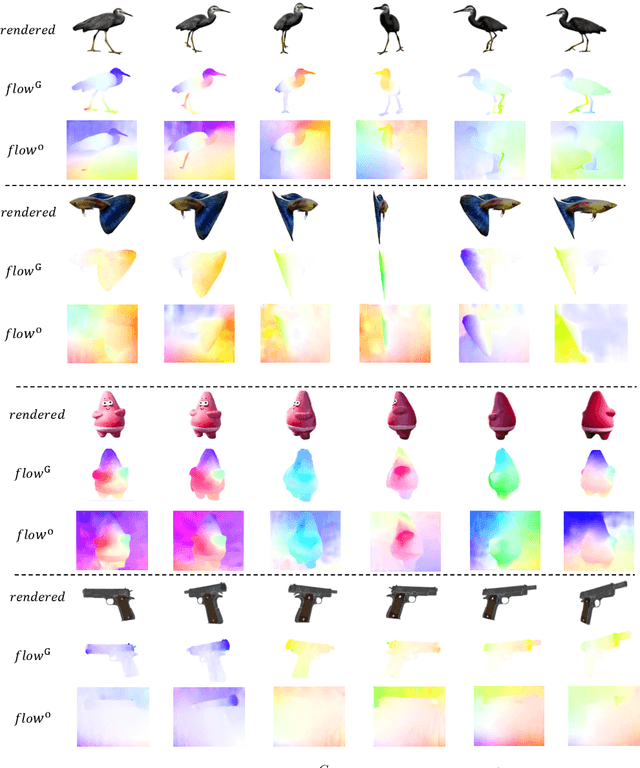
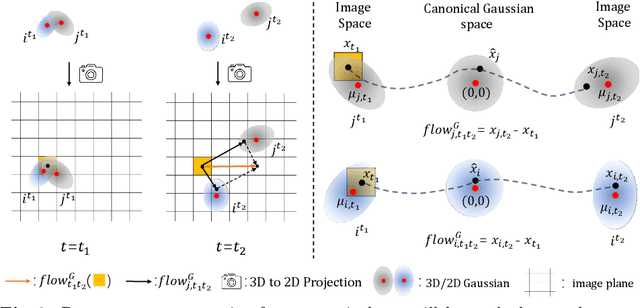
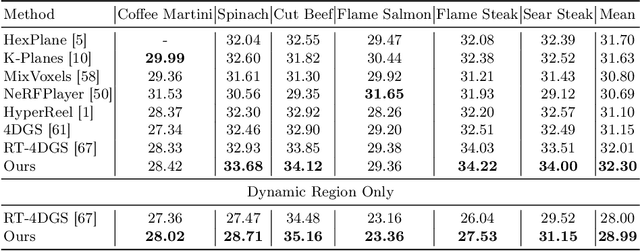

Creating 4D fields of Gaussian Splatting from images or videos is a challenging task due to its under-constrained nature. While the optimization can draw photometric reference from the input videos or be regulated by generative models, directly supervising Gaussian motions remains underexplored. In this paper, we introduce a novel concept, Gaussian flow, which connects the dynamics of 3D Gaussians and pixel velocities between consecutive frames. The Gaussian flow can be efficiently obtained by splatting Gaussian dynamics into the image space. This differentiable process enables direct dynamic supervision from optical flow. Our method significantly benefits 4D dynamic content generation and 4D novel view synthesis with Gaussian Splatting, especially for contents with rich motions that are hard to be handled by existing methods. The common color drifting issue that happens in 4D generation is also resolved with improved Guassian dynamics. Superior visual quality on extensive experiments demonstrates our method's effectiveness. Quantitative and qualitative evaluations show that our method achieves state-of-the-art results on both tasks of 4D generation and 4D novel view synthesis. Project page: https://zerg-overmind.github.io/GaussianFlow.github.io/
InSpaceType: Reconsider Space Type in Indoor Monocular Depth Estimation
Sep 24, 2023Indoor monocular depth estimation has attracted increasing research interest. Most previous works have been focusing on methodology, primarily experimenting with NYU-Depth-V2 (NYUv2) Dataset, and only concentrated on the overall performance over the test set. However, little is known regarding robustness and generalization when it comes to applying monocular depth estimation methods to real-world scenarios where highly varying and diverse functional \textit{space types} are present such as library or kitchen. A study for performance breakdown into space types is essential to realize a pretrained model's performance variance. To facilitate our investigation for robustness and address limitations of previous works, we collect InSpaceType, a high-quality and high-resolution RGBD dataset for general indoor environments. We benchmark 11 recent methods on InSpaceType and find they severely suffer from performance imbalance concerning space types, which reveals their underlying bias. We extend our analysis to 4 other datasets, 3 mitigation approaches, and the ability to generalize to unseen space types. Our work marks the first in-depth investigation of performance imbalance across space types for indoor monocular depth estimation, drawing attention to potential safety concerns for model deployment without considering space types, and further shedding light on potential ways to improve robustness. See \url{https://depthcomputation.github.io/DepthPublic} for data.
MMVP: Motion-Matrix-based Video Prediction
Aug 31, 2023



A central challenge of video prediction lies where the system has to reason the objects' future motions from image frames while simultaneously maintaining the consistency of their appearances across frames. This work introduces an end-to-end trainable two-stream video prediction framework, Motion-Matrix-based Video Prediction (MMVP), to tackle this challenge. Unlike previous methods that usually handle motion prediction and appearance maintenance within the same set of modules, MMVP decouples motion and appearance information by constructing appearance-agnostic motion matrices. The motion matrices represent the temporal similarity of each and every pair of feature patches in the input frames, and are the sole input of the motion prediction module in MMVP. This design improves video prediction in both accuracy and efficiency, and reduces the model size. Results of extensive experiments demonstrate that MMVP outperforms state-of-the-art systems on public data sets by non-negligible large margins (about 1 db in PSNR, UCF Sports) in significantly smaller model sizes (84% the size or smaller).
Strivec: Sparse Tri-Vector Radiance Fields
Jul 25, 2023



We propose Strivec, a novel neural representation that models a 3D scene as a radiance field with sparsely distributed and compactly factorized local tensor feature grids. Our approach leverages tensor decomposition, following the recent work TensoRF, to model the tensor grids. In contrast to TensoRF which uses a global tensor and focuses on their vector-matrix decomposition, we propose to utilize a cloud of local tensors and apply the classic CANDECOMP/PARAFAC (CP) decomposition to factorize each tensor into triple vectors that express local feature distributions along spatial axes and compactly encode a local neural field. We also apply multi-scale tensor grids to discover the geometry and appearance commonalities and exploit spatial coherence with the tri-vector factorization at multiple local scales. The final radiance field properties are regressed by aggregating neural features from multiple local tensors across all scales. Our tri-vector tensors are sparsely distributed around the actual scene surface, discovered by a fast coarse reconstruction, leveraging the sparsity of a 3D scene. We demonstrate that our model can achieve better rendering quality while using significantly fewer parameters than previous methods, including TensoRF and Instant-NGP.
Meta-Optimization for Higher Model Generalizability in Single-Image Depth Prediction
May 12, 2023



Model generalizability to unseen datasets, concerned with in-the-wild robustness, is less studied for indoor single-image depth prediction. We leverage gradient-based meta-learning for higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied image classification in meta-learning, depth is pixel-level continuous range values, and mappings from each image to depth vary widely across environments. Thus no explicit task boundaries exist. We instead propose fine-grained task that treats each RGB-D pair as a task in our meta-optimization. We first show meta-learning on limited data induces much better prior (max +29.4\%). Using meta-learned weights as initialization for following supervised learning, without involving extra data or information, it consistently outperforms baselines without the method. Compared to most indoor-depth methods that only train/ test on a single dataset, we propose zero-shot cross-dataset protocols, closely evaluate robustness, and show consistently higher generalizability and accuracy by our meta-initialization. The work at the intersection of depth and meta-learning potentially drives both research streams to step closer to practical use.
Aware of the History: Trajectory Forecasting with the Local Behavior Data
Jul 20, 2022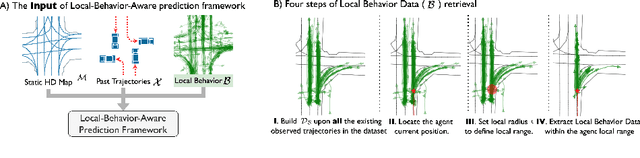
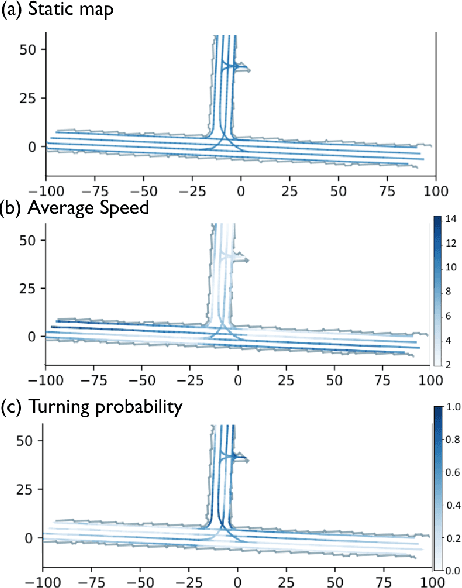

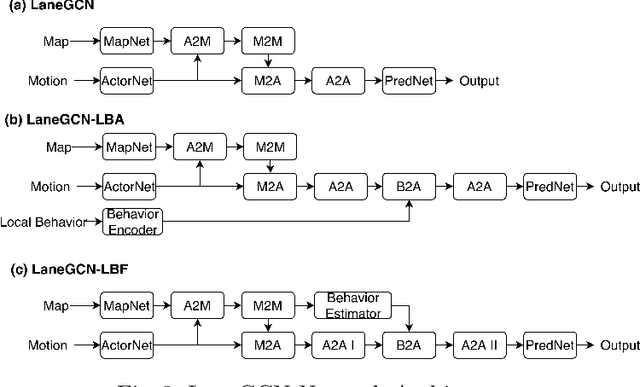
The historical trajectories previously passing through a location may help infer the future trajectory of an agent currently at this location. Despite great improvements in trajectory forecasting with the guidance of high-definition maps, only a few works have explored such local historical information. In this work, we re-introduce this information as a new type of input data for trajectory forecasting systems: the local behavior data, which we conceptualize as a collection of location-specific historical trajectories. Local behavior data helps the systems emphasize the prediction locality and better understand the impact of static map objects on moving agents. We propose a novel local-behavior-aware (LBA) prediction framework that improves forecasting accuracy by fusing information from observed trajectories, HD maps, and local behavior data. Also, where such historical data is insufficient or unavailable, we employ a local-behavior-free (LBF) prediction framework, which adopts a knowledge-distillation-based architecture to infer the impact of missing data. Extensive experiments demonstrate that upgrading existing methods with these two frameworks significantly improves their performances. Especially, the LBA framework boosts the SOTA methods' performance on the nuScenes dataset by at least 14% for the K=1 metrics.