 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Application System in Office Collaboration Scenarios
Mar 26, 2025This paper introduces a multi-agent application system designed to enhance office collaboration efficiency and work quality. The system integrates artificial intelligence, machine learning, and natural language processing technologies, achieving functionalities such as task allocation, progress monitoring, and information sharing. The agents within the system are capable of providing personalized collaboration support based on team members' needs and incorporate data analysis tools to improve decision-making quality. The paper also proposes an intelligent agent architecture that separates Plan and Solver, and through techniques such as multi-turn query rewriting and business tool retrieval, it enhances the agent's multi-intent and multi-turn dialogue capabilities. Furthermore, the paper details the design of tools and multi-turn dialogue in the context of office collaboration scenarios, and validates the system's effectiveness through experiments and evaluations. Ultimately, the system has demonstrated outstanding performance in real business applications, particularly in query understanding, task planning, and tool calling. Looking forward, the system is expected to play a more significant role in addressing complex interaction issues within dynamic environments and large-scale multi-agent systems.
ChatDyn: Language-Driven Multi-Actor Dynamics Generation in Street Scenes
Dec 11, 2024Generating realistic and interactive dynamics of traffic participants according to specific instruction is critical for street scene simulation. However, there is currently a lack of a comprehensive method that generates realistic dynamics of different types of participants including vehicles and pedestrians, with different kinds of interactions between them. In this paper, we introduce ChatDyn, the first system capable of generating interactive, controllable and realistic participant dynamics in street scenes based on language instructions. To achieve precise control through complex language, ChatDyn employs a multi-LLM-agent role-playing approach, which utilizes natural language inputs to plan the trajectories and behaviors for different traffic participants. To generate realistic fine-grained dynamics based on the planning, ChatDyn designs two novel executors: the PedExecutor, a unified multi-task executor that generates realistic pedestrian dynamics under different task plannings; and the VehExecutor, a physical transition-based policy that generates physically plausible vehicle dynamics. Extensive experiments show that ChatDyn can generate realistic driving scene dynamics with multiple vehicles and pedestrians, and significantly outperforms previous methods on subtasks. Code and model will be available at https://vfishc.github.io/chatdyn.
Language-Driven Interactive Traffic Trajectory Generation
May 24, 2024
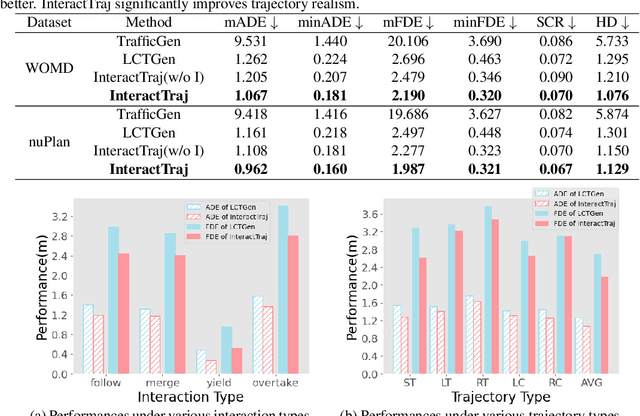

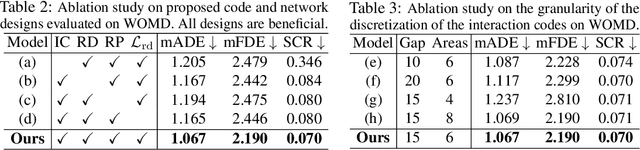
Realistic trajectory generation with natural language control is pivotal for advancing autonomous vehicle technology. However, previous methods focus on individual traffic participant trajectory generation, thus failing to account for the complexity of interactive traffic dynamics. In this work, we propose InteractTraj, the first language-driven traffic trajectory generator that can generate interactive traffic trajectories. InteractTraj interprets abstract trajectory descriptions into concrete formatted interaction-aware numerical codes and learns a mapping between these formatted codes and the final interactive trajectories. To interpret language descriptions, we propose a language-to-code encoder with a novel interaction-aware encoding strategy. To produce interactive traffic trajectories, we propose a code-to-trajectory decoder with interaction-aware feature aggregation that synergizes vehicle interactions with the environmental map and the vehicle moves. Extensive experiments show our method demonstrates superior performance over previous SoTA methods, offering a more realistic generation of interactive traffic trajectories with high controllability via diverse natural language commands. Our code is available at https://github.com/X1a-jk/InteractTraj.git
Ethical-Lens: Curbing Malicious Usages of Open-Source Text-to-Image Models
Apr 18, 2024



The burgeoning landscape of text-to-image models, exemplified by innovations such as Midjourney and DALLE 3, has revolutionized content creation across diverse sectors. However, these advancements bring forth critical ethical concerns, particularly with the misuse of open-source models to generate content that violates societal norms. Addressing this, we introduce Ethical-Lens, a framework designed to facilitate the value-aligned usage of text-to-image tools without necessitating internal model revision. Ethical-Lens ensures value alignment in text-to-image models across toxicity and bias dimensions by refining user commands and rectifying model outputs. Systematic evaluation metrics, combining GPT4-V, HEIM, and FairFace scores, assess alignment capability. Our experiments reveal that Ethical-Lens enhances alignment capabilities to levels comparable with or superior to commercial models like DALLE 3, ensuring user-generated content adheres to ethical standards while maintaining image quality. This study indicates the potential of Ethical-Lens to ensure the sustainable development of open-source text-to-image tools and their beneficial integration into society. Our code is available at https://github.com/yuzhu-cai/Ethical-Lens.
Towards Collaborative Autonomous Driving: Simulation Platform and End-to-End System
Apr 15, 2024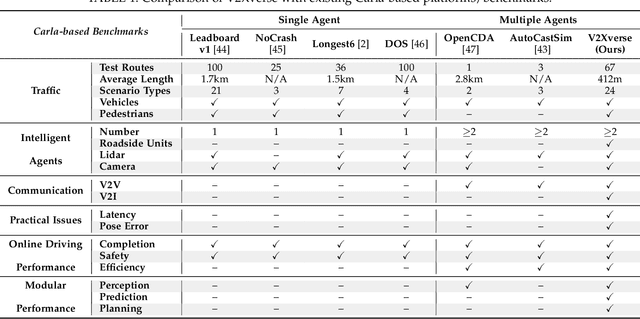
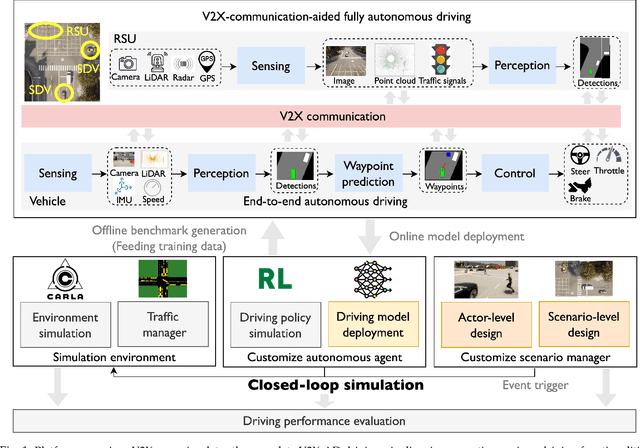

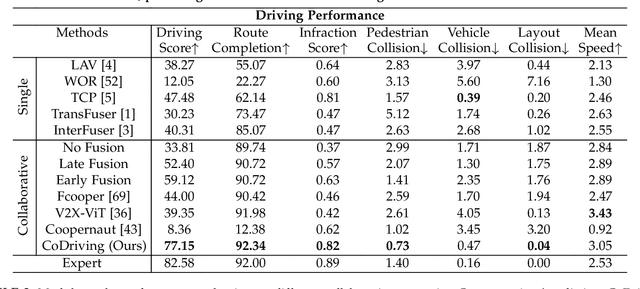
Vehicle-to-everything-aided autonomous driving (V2X-AD) has a huge potential to provide a safer driving solution. Despite extensive researches in transportation and communication to support V2X-AD, the actual utilization of these infrastructures and communication resources in enhancing driving performances remains largely unexplored. This highlights the necessity of collaborative autonomous driving: a machine learning approach that optimizes the information sharing strategy to improve the driving performance of each vehicle. This effort necessitates two key foundations: a platform capable of generating data to facilitate the training and testing of V2X-AD, and a comprehensive system that integrates full driving-related functionalities with mechanisms for information sharing. From the platform perspective, we present V2Xverse, a comprehensive simulation platform for collaborative autonomous driving. This platform provides a complete pipeline for collaborative driving. From the system perspective, we introduce CoDriving, a novel end-to-end collaborative driving system that properly integrates V2X communication over the entire autonomous pipeline, promoting driving with shared perceptual information. The core idea is a novel driving-oriented communication strategy. Leveraging this strategy, CoDriving improves driving performance while optimizing communication efficiency. We make comprehensive benchmarks with V2Xverse, analyzing both modular performance and closed-loop driving performance. Experimental results show that CoDriving: i) significantly improves the driving score by 62.49% and drastically reduces the pedestrian collision rate by 53.50% compared to the SOTA end-to-end driving method, and ii) achieves sustaining driving performance superiority over dynamic constraint communication conditions.
Decentralized and Lifelong-Adaptive Multi-Agent Collaborative Learning
Mar 11, 2024Decentralized and lifelong-adaptive multi-agent collaborative learning aims to enhance collaboration among multiple agents without a central server, with each agent solving varied tasks over time. To achieve efficient collaboration, agents should: i) autonomously identify beneficial collaborative relationships in a decentralized manner; and ii) adapt to dynamically changing task observations. In this paper, we propose DeLAMA, a decentralized multi-agent lifelong collaborative learning algorithm with dynamic collaboration graphs. To promote autonomous collaboration relationship learning, we propose a decentralized graph structure learning algorithm, eliminating the need for external priors. To facilitate adaptation to dynamic tasks, we design a memory unit to capture the agents' accumulated learning history and knowledge, while preserving finite storage consumption. To further augment the system's expressive capabilities and computational efficiency, we apply algorithm unrolling, leveraging the advantages of both mathematical optimization and neural networks. This allows the agents to `learn to collaborate' through the supervision of training tasks. Our theoretical analysis verifies that inter-agent collaboration is communication efficient under a small number of communication rounds. The experimental results verify its ability to facilitate the discovery of collaboration strategies and adaptation to dynamic learning scenarios, achieving a 98.80% reduction in MSE and a 188.87% improvement in classification accuracy. We expect our work can serve as a foundational technique to facilitate future works towards an intelligent, decentralized, and dynamic multi-agent system. Code is available at https://github.com/ShuoTang123/DeLAMA.
Editable Scene Simulation for Autonomous Driving via Collaborative LLM-Agents
Feb 08, 2024



Scene simulation in autonomous driving has gained significant attention because of its huge potential for generating customized data. However, existing editable scene simulation approaches face limitations in terms of user interaction efficiency, multi-camera photo-realistic rendering and external digital assets integration. To address these challenges, this paper introduces ChatSim, the first system that enables editable photo-realistic 3D driving scene simulations via natural language commands with external digital assets. To enable editing with high command flexibility,~ChatSim leverages a large language model (LLM) agent collaboration framework. To generate photo-realistic outcomes, ChatSim employs a novel multi-camera neural radiance field method. Furthermore, to unleash the potential of extensive high-quality digital assets, ChatSim employs a novel multi-camera lighting estimation method to achieve scene-consistent assets' rendering. Our experiments on Waymo Open Dataset demonstrate that ChatSim can handle complex language commands and generate corresponding photo-realistic scene videos.
Self-Supervised Bird's Eye View Motion Prediction with Cross-Modality Signals
Jan 21, 2024
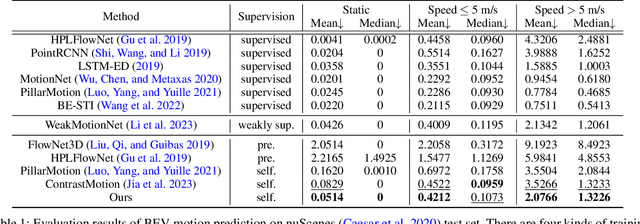
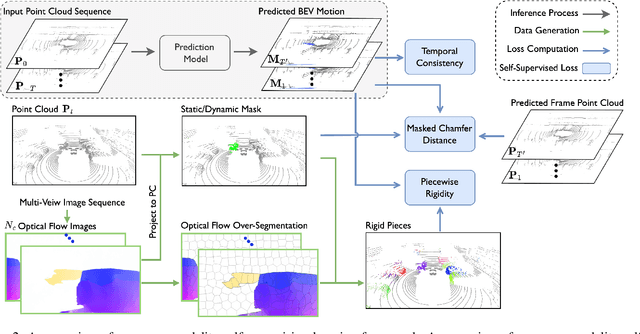
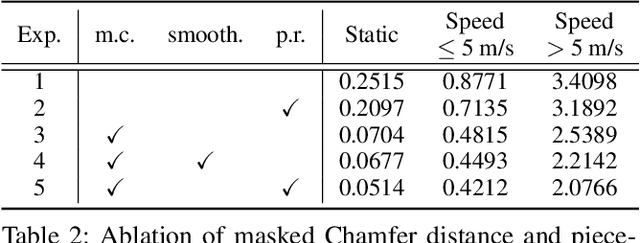
Learning the dense bird's eye view (BEV) motion flow in a self-supervised manner is an emerging research for robotics and autonomous driving. Current self-supervised methods mainly rely on point correspondences between point clouds, which may introduce the problems of fake flow and inconsistency, hindering the model's ability to learn accurate and realistic motion. In this paper, we introduce a novel cross-modality self-supervised training framework that effectively addresses these issues by leveraging multi-modality data to obtain supervision signals. We design three innovative supervision signals to preserve the inherent properties of scene motion, including the masked Chamfer distance loss, the piecewise rigidity loss, and the temporal consistency loss. Through extensive experiments, we demonstrate that our proposed self-supervised framework outperforms all previous self-supervision methods for the motion prediction task.
Compatible Transformer for Irregularly Sampled Multivariate Time Series
Oct 17, 2023



To analyze multivariate time series, most previous methods assume regular subsampling of time series, where the interval between adjacent measurements and the number of samples remain unchanged. Practically, data collection systems could produce irregularly sampled time series due to sensor failures and interventions. However, existing methods designed for regularly sampled multivariate time series cannot directly handle irregularity owing to misalignment along both temporal and variate dimensions. To fill this gap, we propose Compatible Transformer (CoFormer), a transformer-based encoder to achieve comprehensive temporal-interaction feature learning for each individual sample in irregular multivariate time series. In CoFormer, we view each sample as a unique variate-time point and leverage intra-variate/inter-variate attentions to learn sample-wise temporal/interaction features based on intra-variate/inter-variate neighbors. With CoFormer as the core, we can analyze irregularly sampled multivariate time series for many downstream tasks, including classification and prediction. We conduct extensive experiments on 3 real-world datasets and validate that the proposed CoFormer significantly and consistently outperforms existing methods.
Auxiliary Tasks Benefit 3D Skeleton-based Human Motion Prediction
Sep 02, 2023



Exploring spatial-temporal dependencies from observed motions is one of the core challenges of human motion prediction. Previous methods mainly focus on dedicated network structures to model the spatial and temporal dependencies. This paper considers a new direction by introducing a model learning framework with auxiliary tasks. In our auxiliary tasks, partial body joints' coordinates are corrupted by either masking or adding noise and the goal is to recover corrupted coordinates depending on the rest coordinates. To work with auxiliary tasks, we propose a novel auxiliary-adapted transformer, which can handle incomplete, corrupted motion data and achieve coordinate recovery via capturing spatial-temporal dependencies. Through auxiliary tasks, the auxiliary-adapted transformer is promoted to capture more comprehensive spatial-temporal dependencies among body joints' coordinates, leading to better feature learning. Extensive experimental results have shown that our method outperforms state-of-the-art methods by remarkable margins of 7.2%, 3.7%, and 9.4% in terms of 3D mean per joint position error (MPJPE) on the Human3.6M, CMU Mocap, and 3DPW datasets, respectively. We also demonstrate that our method is more robust under data missing cases and noisy data cases. Code is available at https://github.com/MediaBrain-SJTU/AuxFormer.