 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Graph Unleashed: A Novel Approach to Video Prediction
Oct 29, 2024We introduce motion graph, a novel approach to the video prediction problem, which predicts future video frames from limited past data. The motion graph transforms patches of video frames into interconnected graph nodes, to comprehensively describe the spatial-temporal relationships among them. This representation overcomes the limitations of existing motion representations such as image differences, optical flow, and motion matrix that either fall short in capturing complex motion patterns or suffer from excessive memory consumption. We further present a video prediction pipeline empowered by motion graph, exhibiting substantial performance improvements and cost reductions. Experiments on various datasets, including UCF Sports, KITTI and Cityscapes, highlight the strong representative ability of motion graph. Especially on UCF Sports, our method matches and outperforms the SOTA methods with a significant reduction in model size by 78% and a substantial decrease in GPU memory utilization by 47%.
Boosting Generalizability towards Zero-Shot Cross-Dataset Single-Image Indoor Depth by Meta-Initialization
Sep 04, 2024Indoor robots rely on depth to perform tasks like navigation or obstacle detection, and single-image depth estimation is widely used to assist perception. Most indoor single-image depth prediction focuses less on model generalizability to unseen datasets, concerned with in-the-wild robustness for system deployment. This work leverages gradient-based meta-learning to gain higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied meta-learning of image classification associated with explicit class labels, no explicit task boundaries exist for continuous depth values tied to highly varying indoor environments regarding object arrangement and scene composition. We propose fine-grained task that treats each RGB-D mini-batch as a task in our meta-learning formulation. We first show that our method on limited data induces a much better prior (max 27.8% in RMSE). Then, finetuning on meta-learned initialization consistently outperforms baselines without the meta approach. Aiming at generalization, we propose zero-shot cross-dataset protocols and validate higher generalizability induced by our meta-initialization, as a simple and useful plugin to many existing depth estimation methods. The work at the intersection of depth and meta-learning potentially drives both research to step closer to practical robotic and machine perception usage.
An Extensible Framework for Open Heterogeneous Collaborative Perception
Jan 25, 2024



Collaborative perception aims to mitigate the limitations of single-agent perception, such as occlusions, by facilitating data exchange among multiple agents. However, most current works consider a homogeneous scenario where all agents use identity sensors and perception models. In reality, heterogeneous agent types may continually emerge and inevitably face a domain gap when collaborating with existing agents. In this paper, we introduce a new open heterogeneous problem: how to accommodate continually emerging new heterogeneous agent types into collaborative perception, while ensuring high perception performance and low integration cost? To address this problem, we propose HEterogeneous ALliance (HEAL), a novel extensible collaborative perception framework. HEAL first establishes a unified feature space with initial agents via a novel multi-scale foreground-aware Pyramid Fusion network. When heterogeneous new agents emerge with previously unseen modalities or models, we align them to the established unified space with an innovative backward alignment. This step only involves individual training on the new agent type, thus presenting extremely low training costs and high extensibility. It also protects new agents' model details from disclosure since the training can be conducted by the agent owner locally. To enrich agents' data heterogeneity, we bring OPV2V-H, a new large-scale dataset with more diverse sensor types. Extensive experiments on OPV2V-H and DAIR-V2X datasets show that HEAL surpasses SOTA methods in performance while reducing the training parameters by 91.5% when integrating 3 new agent types. Code and data are available at: https://github.com/yifanlu0227/HEAL.
Self-Supervised Bird's Eye View Motion Prediction with Cross-Modality Signals
Jan 21, 2024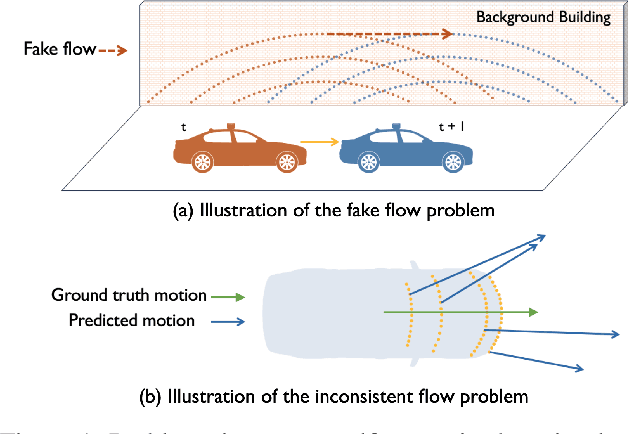
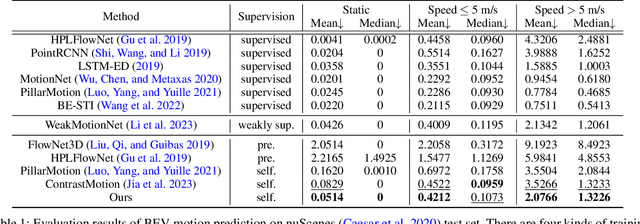
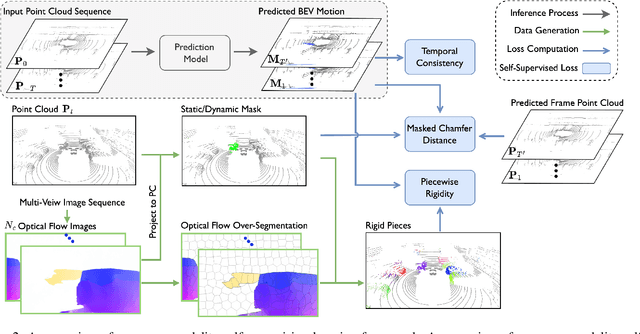
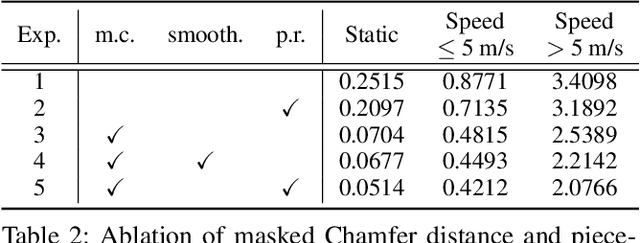
Learning the dense bird's eye view (BEV) motion flow in a self-supervised manner is an emerging research for robotics and autonomous driving. Current self-supervised methods mainly rely on point correspondences between point clouds, which may introduce the problems of fake flow and inconsistency, hindering the model's ability to learn accurate and realistic motion. In this paper, we introduce a novel cross-modality self-supervised training framework that effectively addresses these issues by leveraging multi-modality data to obtain supervision signals. We design three innovative supervision signals to preserve the inherent properties of scene motion, including the masked Chamfer distance loss, the piecewise rigidity loss, and the temporal consistency loss. Through extensive experiments, we demonstrate that our proposed self-supervised framework outperforms all previous self-supervision methods for the motion prediction task.
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Dec 01, 2023
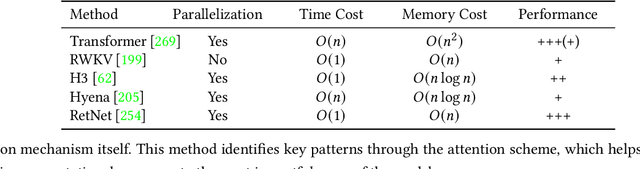
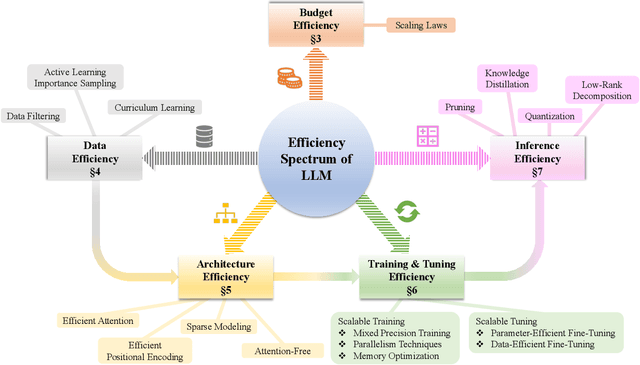
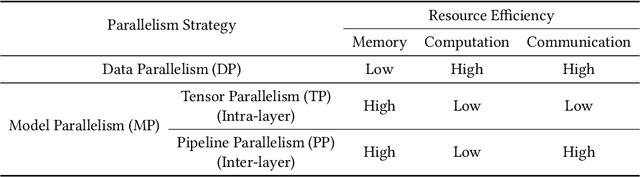
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.
Asynchrony-Robust Collaborative Perception via Bird's Eye View Flow
Oct 09, 2023



Collaborative perception can substantially boost each agent's perception ability by facilitating communication among multiple agents. However, temporal asynchrony among agents is inevitable in the real world due to communication delays, interruptions, and clock misalignments. This issue causes information mismatch during multi-agent fusion, seriously shaking the foundation of collaboration. To address this issue, we propose CoBEVFlow, an asynchrony-robust collaborative perception system based on bird's eye view (BEV) flow. The key intuition of CoBEVFlow is to compensate motions to align asynchronous collaboration messages sent by multiple agents. To model the motion in a scene, we propose BEV flow, which is a collection of the motion vector corresponding to each spatial location. Based on BEV flow, asynchronous perceptual features can be reassigned to appropriate positions, mitigating the impact of asynchrony. CoBEVFlow has two advantages: (i) CoBEVFlow can handle asynchronous collaboration messages sent at irregular, continuous time stamps without discretization; and (ii) with BEV flow, CoBEVFlow only transports the original perceptual features, instead of generating new perceptual features, avoiding additional noises. To validate CoBEVFlow's efficacy, we create IRregular V2V(IRV2V), the first synthetic collaborative perception dataset with various temporal asynchronies that simulate different real-world scenarios. Extensive experiments conducted on both IRV2V and the real-world dataset DAIR-V2X show that CoBEVFlow consistently outperforms other baselines and is robust in extremely asynchronous settings. The code is available at https://github.com/MediaBrain-SJTU/CoBEVFlow.
MMVP: Motion-Matrix-based Video Prediction
Aug 31, 2023



A central challenge of video prediction lies where the system has to reason the objects' future motions from image frames while simultaneously maintaining the consistency of their appearances across frames. This work introduces an end-to-end trainable two-stream video prediction framework, Motion-Matrix-based Video Prediction (MMVP), to tackle this challenge. Unlike previous methods that usually handle motion prediction and appearance maintenance within the same set of modules, MMVP decouples motion and appearance information by constructing appearance-agnostic motion matrices. The motion matrices represent the temporal similarity of each and every pair of feature patches in the input frames, and are the sole input of the motion prediction module in MMVP. This design improves video prediction in both accuracy and efficiency, and reduces the model size. Results of extensive experiments demonstrate that MMVP outperforms state-of-the-art systems on public data sets by non-negligible large margins (about 1 db in PSNR, UCF Sports) in significantly smaller model sizes (84% the size or smaller).
Backdoor Attacks Against Incremental Learners: An Empirical Evaluation Study
May 28, 2023Large amounts of incremental learning algorithms have been proposed to alleviate the catastrophic forgetting issue arises while dealing with sequential data on a time series. However, the adversarial robustness of incremental learners has not been widely verified, leaving potential security risks. Specifically, for poisoning-based backdoor attacks, we argue that the nature of streaming data in IL provides great convenience to the adversary by creating the possibility of distributed and cross-task attacks -- an adversary can affect \textbf{any unknown} previous or subsequent task by data poisoning \textbf{at any time or time series} with extremely small amount of backdoor samples injected (e.g., $0.1\%$ based on our observations). To attract the attention of the research community, in this paper, we empirically reveal the high vulnerability of 11 typical incremental learners against poisoning-based backdoor attack on 3 learning scenarios, especially the cross-task generalization effect of backdoor knowledge, while the poison ratios range from $5\%$ to as low as $0.1\%$. Finally, the defense mechanism based on activation clustering is found to be effective in detecting our trigger pattern to mitigate potential security risks.
Meta-Optimization for Higher Model Generalizability in Single-Image Depth Prediction
May 12, 2023



Model generalizability to unseen datasets, concerned with in-the-wild robustness, is less studied for indoor single-image depth prediction. We leverage gradient-based meta-learning for higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied image classification in meta-learning, depth is pixel-level continuous range values, and mappings from each image to depth vary widely across environments. Thus no explicit task boundaries exist. We instead propose fine-grained task that treats each RGB-D pair as a task in our meta-optimization. We first show meta-learning on limited data induces much better prior (max +29.4\%). Using meta-learned weights as initialization for following supervised learning, without involving extra data or information, it consistently outperforms baselines without the method. Compared to most indoor-depth methods that only train/ test on a single dataset, we propose zero-shot cross-dataset protocols, closely evaluate robustness, and show consistently higher generalizability and accuracy by our meta-initialization. The work at the intersection of depth and meta-learning potentially drives both research streams to step closer to practical use.
TBP-Former: Learning Temporal Bird's-Eye-View Pyramid for Joint Perception and Prediction in Vision-Centric Autonomous Driving
Mar 22, 2023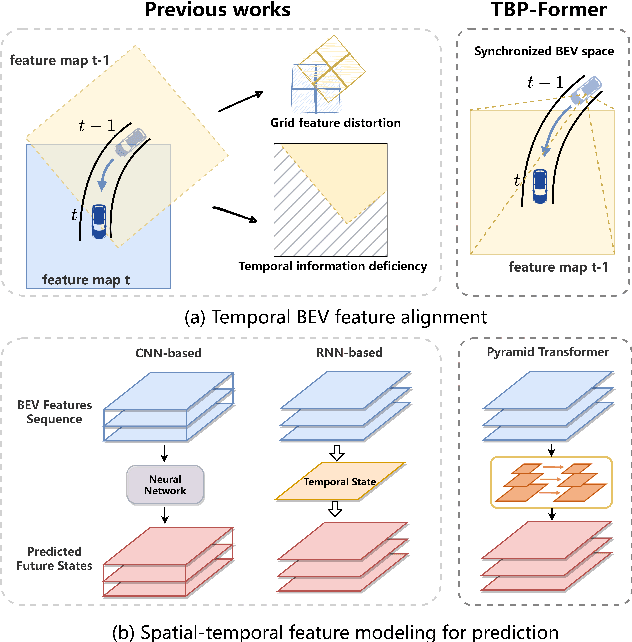

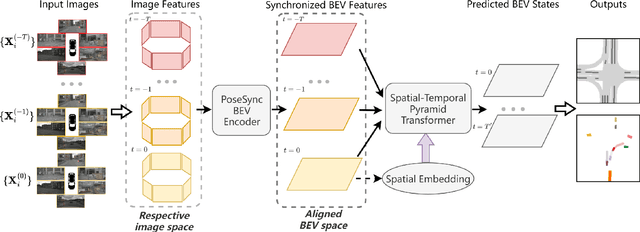

Vision-centric joint perception and prediction (PnP) has become an emerging trend in autonomous driving research. It predicts the future states of the traffic participants in the surrounding environment from raw RGB images. However, it is still a critical challenge to synchronize features obtained at multiple camera views and timestamps due to inevitable geometric distortions and further exploit those spatial-temporal features. To address this issue, we propose a temporal bird's-eye-view pyramid transformer (TBP-Former) for vision-centric PnP, which includes two novel designs. First, a pose-synchronized BEV encoder is proposed to map raw image inputs with any camera pose at any time to a shared and synchronized BEV space for better spatial-temporal synchronization. Second, a spatial-temporal pyramid transformer is introduced to comprehensively extract multi-scale BEV features and predict future BEV states with the support of spatial-temporal priors. Extensive experiments on nuScenes dataset show that our proposed framework overall outperforms all state-of-the-art vision-based prediction methods.