 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Adapt: In-Context Learning Beyond Stationarity
Apr 13, 2026Transformer models have become foundational across a wide range of scientific and engineering domains due to their strong empirical performance. A key capability underlying their success is in-context learning (ICL): when presented with a short prompt from an unseen task, transformers can perform per-token and next-token predictions without any parameter updates. Recent theoretical efforts have begun to uncover the mechanisms behind this phenomenon, particularly in supervised regression settings. However, these analyses predominantly assume stationary task distributions, which overlook a broad class of real-world scenarios where the target function varies over time. In this work, we bridge this gap by providing a theoretical analysis of ICL under non-stationary regression problems. We study how the gated linear attention (GLA) mechanism adapts to evolving input-output relationships and rigorously characterize its advantages over standard linear attention in this dynamic setting. To model non-stationarity, we adopt a first-order autoregressive process and show that GLA achieves lower training and testing errors by adaptively modulating the influence of past inputs -- effectively implementing a learnable recency bias. Our theoretical findings are further supported by empirical results, which validate the benefits of gating mechanisms in non-stationary ICL tasks.
LLMs Struggle with Abstract Meaning Comprehension More Than Expected
Apr 13, 2026Understanding abstract meanings is crucial for advanced language comprehension. Despite extensive research, abstract words remain challenging due to their non-concrete, high-level semantics. SemEval-2021 Task 4 (ReCAM) evaluates models' ability to interpret abstract concepts by presenting passages with questions and five abstract options in a cloze-style format. Key findings include: (1) Most large language models (LLMs), including GPT-4o, struggle with abstract meaning comprehension under zero-shot, one-shot, and few-shot settings, while fine-tuned models like BERT and RoBERTa perform better. (2) A proposed bidirectional attention classifier, inspired by human cognitive strategies, enhances fine-tuned models by dynamically attending to passages and options. This approach improves accuracy by 4.06 percent on Task 1 and 3.41 percent on Task 2, demonstrating its potential for abstract meaning comprehension.
DeltaEvolve: Accelerating Scientific Discovery through Momentum-Driven Evolution
Feb 02, 2026LLM-driven evolutionary systems have shown promise for automated science discovery, yet existing approaches such as AlphaEvolve rely on full-code histories that are context-inefficient and potentially provide weak evolutionary guidance. In this work, we first formalize the evolutionary agents as a general Expectation-Maximization framework, where the language model samples candidate programs (E-step) and the system updates the control context based on evaluation feedback (M-step). Under this view, constructing context via full-code snapshots constitutes a suboptimal M-step, as redundant implement details dilutes core algorithmic ideas, making it difficult to provide clear inspirations for evolution. To address this, we propose DeltaEvolve, a momentum-driven evolutionary framework that replaces full-code history with structured semantic delta capturing how and why modifications between successive nodes affect performance. As programs are often decomposable, semantic delta usually contains many effective components which are transferable and more informative to drive improvement. By organizing semantic delta through multi-level database and progressive disclosure mechanism, input tokens are further reduced. Empirical evaluations on tasks across diverse scientific domains show that our framework can discover better solution with less token consumption over full-code-based evolutionary agents.
From Emergence to Control: Probing and Modulating Self-Reflection in Language Models
Jun 13, 2025Self-reflection -- the ability of a large language model (LLM) to revisit, evaluate, and revise its own reasoning -- has recently emerged as a powerful behavior enabled by reinforcement learning with verifiable rewards (RLVR). While self-reflection correlates with improved reasoning accuracy, its origin and underlying mechanisms remain poorly understood. In this work, {\it we first show that self-reflection is not exclusive to RLVR fine-tuned models: it already emerges, albeit rarely, in pretrained models}. To probe this latent ability, we introduce Reflection-Inducing Probing, a method that injects reflection-triggering reasoning traces from fine-tuned models into pretrained models. This intervention raises self-reflection frequency of Qwen2.5 from 0.6\% to 18.6\%, revealing a hidden capacity for reflection. Moreover, our analysis of internal representations shows that both pretrained and fine-tuned models maintain hidden states that distinctly separate self-reflective from non-reflective contexts. Leveraging this observation, {\it we then construct a self-reflection vector, a direction in activation space associated with self-reflective reasoning}. By manipulating this vector, we enable bidirectional control over the self-reflective behavior for both pretrained and fine-tuned models. Experiments across multiple reasoning benchmarks show that enhancing these vectors improves reasoning performance by up to 12\%, while suppressing them reduces computational cost, providing a flexible mechanism to navigate the trade-off between reasoning quality and efficiency without requiring additional training. Our findings further our understanding of self-reflection and support a growing body of work showing that understanding model internals can enable precise behavioral control.
Understanding Task Vectors in In-Context Learning: Emergence, Functionality, and Limitations
Jun 10, 2025Task vectors offer a compelling mechanism for accelerating inference in in-context learning (ICL) by distilling task-specific information into a single, reusable representation. Despite their empirical success, the underlying principles governing their emergence and functionality remain unclear. This work proposes the Linear Combination Conjecture, positing that task vectors act as single in-context demonstrations formed through linear combinations of the original ones. We provide both theoretical and empirical support for this conjecture. First, we show that task vectors naturally emerge in linear transformers trained on triplet-formatted prompts through loss landscape analysis. Next, we predict the failure of task vectors on representing high-rank mappings and confirm this on practical LLMs. Our findings are further validated through saliency analyses and parameter visualization, suggesting an enhancement of task vectors by injecting multiple ones into few-shot prompts. Together, our results advance the understanding of task vectors and shed light on the mechanisms underlying ICL in transformer-based models.
ProCrop: Learning Aesthetic Image Cropping from Professional Compositions
May 28, 2025Image cropping is crucial for enhancing the visual appeal and narrative impact of photographs, yet existing rule-based and data-driven approaches often lack diversity or require annotated training data. We introduce ProCrop, a retrieval-based method that leverages professional photography to guide cropping decisions. By fusing features from professional photographs with those of the query image, ProCrop learns from professional compositions, significantly boosting performance. Additionally, we present a large-scale dataset of 242K weakly-annotated images, generated by out-painting professional images and iteratively refining diverse crop proposals. This composition-aware dataset generation offers diverse high-quality crop proposals guided by aesthetic principles and becomes the largest publicly available dataset for image cropping. Extensive experiments show that ProCrop significantly outperforms existing methods in both supervised and weakly-supervised settings. Notably, when trained on the new dataset, our ProCrop surpasses previous weakly-supervised methods and even matches fully supervised approaches. Both the code and dataset will be made publicly available to advance research in image aesthetics and composition analysis.
Analyzing Fine-Grained Alignment and Enhancing Vision Understanding in Multimodal Language Models
May 22, 2025Achieving better alignment between vision embeddings and Large Language Models (LLMs) is crucial for enhancing the abilities of Multimodal LLMs (MLLMs), particularly for recent models that rely on powerful pretrained vision encoders and LLMs. A common approach to connect the pretrained vision encoder and LLM is through a projector applied after the vision encoder. However, the projector is often trained to enable the LLM to generate captions, and hence the mechanism by which LLMs understand each vision token remains unclear. In this work, we first investigate the role of the projector in compressing vision embeddings and aligning them with word embeddings. We show that the projector significantly compresses visual information, removing redundant details while preserving essential elements necessary for the LLM to understand visual content. We then examine patch-level alignment -- the alignment between each vision patch and its corresponding semantic words -- and propose a *multi-semantic alignment hypothesis*. Our analysis indicates that the projector trained by caption loss improves patch-level alignment but only to a limited extent, resulting in weak and coarse alignment. To address this issue, we propose *patch-aligned training* to efficiently enhance patch-level alignment. Our experiments show that patch-aligned training (1) achieves stronger compression capability and improved patch-level alignment, enabling the MLLM to generate higher-quality captions, (2) improves the MLLM's performance by 16% on referring expression grounding tasks, 4% on question-answering tasks, and 3% on modern instruction-following benchmarks when using the same supervised fine-tuning (SFT) setting. The proposed method can be easily extended to other multimodal models.
From Compression to Expansion: A Layerwise Analysis of In-Context Learning
May 22, 2025In-context learning (ICL) enables large language models (LLMs) to adapt to new tasks without weight updates by learning from demonstration sequences. While ICL shows strong empirical performance, its internal representational mechanisms are not yet well understood. In this work, we conduct a statistical geometric analysis of ICL representations to investigate how task-specific information is captured across layers. Our analysis reveals an intriguing phenomenon, which we term *Layerwise Compression-Expansion*: early layers progressively produce compact and discriminative representations that encode task information from the input demonstrations, while later layers expand these representations to incorporate the query and generate the prediction. This phenomenon is observed consistently across diverse tasks and a range of contemporary LLM architectures. We demonstrate that it has important implications for ICL performance -- improving with model size and the number of demonstrations -- and for robustness in the presence of noisy examples. To further understand the effect of the compact task representation, we propose a bias-variance decomposition and provide a theoretical analysis showing how attention mechanisms contribute to reducing both variance and bias, thereby enhancing performance as the number of demonstrations increases. Our findings reveal an intriguing layerwise dynamic in ICL, highlight how structured representations emerge within LLMs, and showcase that analyzing internal representations can facilitate a deeper understanding of model behavior.
On Layer-wise Representation Similarity: Application for Multi-Exit Models with a Single Classifier
Jun 20, 2024



Analyzing the similarity of internal representations within and across different models has been an important technique for understanding the behavior of deep neural networks. Most existing methods for analyzing the similarity between representations of high dimensions, such as those based on Canonical Correlation Analysis (CCA) and widely used Centered Kernel Alignment (CKA), rely on statistical properties of the representations for a set of data points. In this paper, we focus on transformer models and study the similarity of representations between the hidden layers of individual transformers. In this context, we show that a simple sample-wise cosine similarity metric is capable of capturing the similarity and aligns with the complicated CKA. Our experimental results on common transformers reveal that representations across layers are positively correlated, albeit the similarity decreases when layers are far apart. We then propose an aligned training approach to enhance the similarity between internal representations, with trained models that enjoy the following properties: (1) the last-layer classifier can be directly applied right after any hidden layers, yielding intermediate layer accuracies much higher than those under standard training, (2) the layer-wise accuracies monotonically increase and reveal the minimal depth needed for the given task, (3) when served as multi-exit models, they achieve on-par performance with standard multi-exit architectures which consist of additional classifiers designed for early exiting in shallow layers. To our knowledge, our work is the first to show that one common classifier is sufficient for multi-exit models. We conduct experiments on both vision and NLP tasks to demonstrate the performance of the proposed aligned training.
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Dec 01, 2023
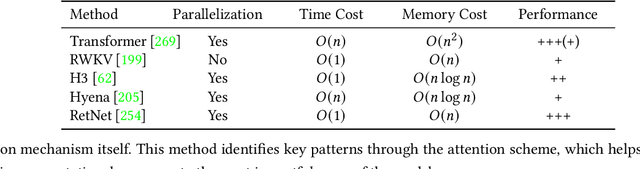
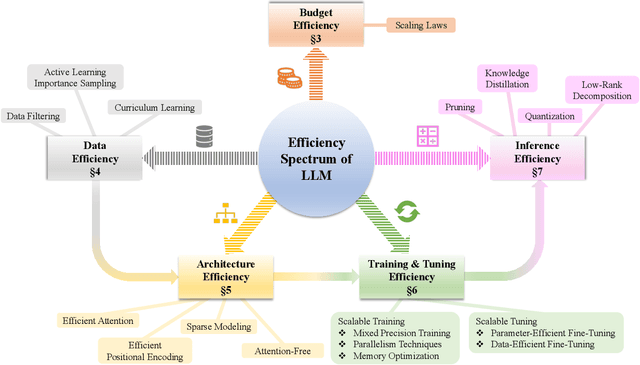
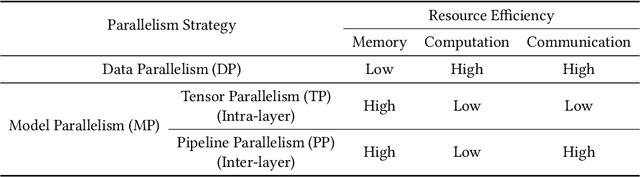
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.