 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual Fairness In Strategic Classification
Feb 04, 2026Strategic classification, where individuals modify their features to influence machine learning (ML) decisions, presents critical fairness challenges. While group fairness in this setting has been widely studied, individual fairness remains underexplored. We analyze threshold-based classifiers and prove that deterministic thresholds violate individual fairness. Then, we investigate the possibility of using a randomized classifier to achieve individual fairness. We introduce conditions under which a randomized classifier ensures individual fairness and leverage these conditions to find an optimal and individually fair randomized classifier through a linear programming problem. Additionally, we demonstrate that our approach can be extended to group fairness notions. Experiments on real-world datasets confirm that our method effectively mitigates unfairness and improves the fairness-accuracy trade-off.
From Emergence to Control: Probing and Modulating Self-Reflection in Language Models
Jun 13, 2025Self-reflection -- the ability of a large language model (LLM) to revisit, evaluate, and revise its own reasoning -- has recently emerged as a powerful behavior enabled by reinforcement learning with verifiable rewards (RLVR). While self-reflection correlates with improved reasoning accuracy, its origin and underlying mechanisms remain poorly understood. In this work, {\it we first show that self-reflection is not exclusive to RLVR fine-tuned models: it already emerges, albeit rarely, in pretrained models}. To probe this latent ability, we introduce Reflection-Inducing Probing, a method that injects reflection-triggering reasoning traces from fine-tuned models into pretrained models. This intervention raises self-reflection frequency of Qwen2.5 from 0.6\% to 18.6\%, revealing a hidden capacity for reflection. Moreover, our analysis of internal representations shows that both pretrained and fine-tuned models maintain hidden states that distinctly separate self-reflective from non-reflective contexts. Leveraging this observation, {\it we then construct a self-reflection vector, a direction in activation space associated with self-reflective reasoning}. By manipulating this vector, we enable bidirectional control over the self-reflective behavior for both pretrained and fine-tuned models. Experiments across multiple reasoning benchmarks show that enhancing these vectors improves reasoning performance by up to 12\%, while suppressing them reduces computational cost, providing a flexible mechanism to navigate the trade-off between reasoning quality and efficiency without requiring additional training. Our findings further our understanding of self-reflection and support a growing body of work showing that understanding model internals can enable precise behavioral control.
Towards Understanding and Improving Refusal in Compressed Models via Mechanistic Interpretability
Apr 05, 2025The rapid growth of large language models has spurred significant interest in model compression as a means to enhance their accessibility and practicality. While extensive research has explored model compression through the lens of safety, findings suggest that safety-aligned models often lose elements of trustworthiness post-compression. Simultaneously, the field of mechanistic interpretability has gained traction, with notable discoveries, such as the identification of a single direction in the residual stream mediating refusal behaviors across diverse model architectures. In this work, we investigate the safety of compressed models by examining the mechanisms of refusal, adopting a novel interpretability-driven perspective to evaluate model safety. Furthermore, leveraging insights from our interpretability analysis, we propose a lightweight, computationally efficient method to enhance the safety of compressed models without compromising their performance or utility.
Post-processing for Fair Regression via Explainable SVD
Apr 04, 2025

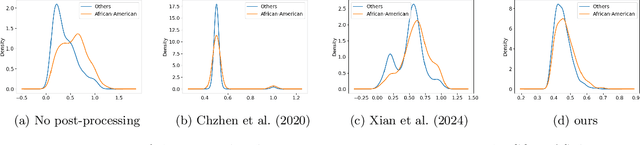

This paper presents a post-processing algorithm for training fair neural network regression models that satisfy statistical parity, utilizing an explainable singular value decomposition (SVD) of the weight matrix. We propose a linear transformation of the weight matrix, whereby the singular values derived from the SVD of the transformed matrix directly correspond to the differences in the first and second moments of the output distributions across two groups. Consequently, we can convert the fairness constraints into constraints on the singular values. We analytically solve the problem of finding the optimal weights under these constraints. Experimental validation on various datasets demonstrates that our method achieves a similar or superior fairness-accuracy trade-off compared to the baselines without using the sensitive attribute at the inference time.
An Efficient Training Algorithm for Models with Block-wise Sparsity
Mar 27, 2025Large-scale machine learning (ML) models are increasingly being used in critical domains like education, lending, recruitment, healthcare, criminal justice, etc. However, the training, deployment, and utilization of these models demand substantial computational resources. To decrease computation and memory costs, machine learning models with sparse weight matrices are widely used in the literature. Among sparse models, those with special sparse structures (e.g., models with block-wise sparse weight matrices) fit better with the hardware accelerators and can decrease the memory and computation costs during the inference. Unfortunately, while there are several efficient training methods, none of them are designed to train a block-wise sparse model efficiently. As a result, the current methods for training block-wise sparse models start with full and dense models leading to inefficient training. In this work, we focus on training models with \textit{block-wise sparse matrices} and propose an efficient training algorithm to decrease both computation and memory costs during training and inference. In addition, we will show that our proposed method enables us to efficiently find the right block size for the sparsity pattern during the training process. Our extensive empirical and theoretical analyses show that our algorithms can decrease the computation and memory costs significantly without a performance drop compared to baselines.
Lookahead Counterfactual Fairness
Dec 02, 2024As machine learning (ML) algorithms are used in applications that involve humans, concerns have arisen that these algorithms may be biased against certain social groups. \textit{Counterfactual fairness} (CF) is a fairness notion proposed in Kusner et al. (2017) that measures the unfairness of ML predictions; it requires that the prediction perceived by an individual in the real world has the same marginal distribution as it would be in a counterfactual world, in which the individual belongs to a different group. Although CF ensures fair ML predictions, it fails to consider the downstream effects of ML predictions on individuals. Since humans are strategic and often adapt their behaviors in response to the ML system, predictions that satisfy CF may not lead to a fair future outcome for the individuals. In this paper, we introduce \textit{lookahead counterfactual fairness} (LCF), a fairness notion accounting for the downstream effects of ML models which requires the individual \textit{future status} to be counterfactually fair. We theoretically identify conditions under which LCF can be satisfied and propose an algorithm based on the theorems. We also extend the concept to path-dependent fairness. Experiments on both synthetic and real data validate the proposed method.
ECG Signal Denoising Using Multi-scale Patch Embedding and Transformers
Jul 12, 2024


Cardiovascular disease is a major life-threatening condition that is commonly monitored using electrocardiogram (ECG) signals. However, these signals are often contaminated by various types of noise at different intensities, significantly interfering with downstream tasks. Therefore, denoising ECG signals and increasing the signal-to-noise ratio is crucial for cardiovascular monitoring. In this paper, we propose a deep learning method that combines a one-dimensional convolutional layer with transformer architecture for denoising ECG signals. The convolutional layer processes the ECG signal by various kernel/patch sizes and generates an embedding called multi-scale patch embedding. The embedding then is used as the input of a transformer network and enhances the capability of the transformer for denoising the ECG signal.
Privacy-Aware Randomized Quantization via Linear Programming
Jun 01, 2024



Differential privacy mechanisms such as the Gaussian or Laplace mechanism have been widely used in data analytics for preserving individual privacy. However, they are mostly designed for continuous outputs and are unsuitable for scenarios where discrete values are necessary. Although various quantization mechanisms were proposed recently to generate discrete outputs under differential privacy, the outcomes are either biased or have an inferior accuracy-privacy trade-off. In this paper, we propose a family of quantization mechanisms that is unbiased and differentially private. It has a high degree of freedom and we show that some existing mechanisms can be considered as special cases of ours. To find the optimal mechanism, we formulate a linear optimization that can be solved efficiently using linear programming tools. Experiments show that our proposed mechanism can attain a better privacy-accuracy trade-off compared to baselines.
Learning under Imitative Strategic Behavior with Unforeseeable Outcomes
May 03, 2024



Machine learning systems have been widely used to make decisions about individuals who may best respond and behave strategically to receive favorable outcomes, e.g., they may genuinely improve the true labels or manipulate observable features directly to game the system without changing labels. Although both behaviors have been studied (often as two separate problems) in the literature, most works assume individuals can (i) perfectly foresee the outcomes of their behaviors when they best respond; (ii) change their features arbitrarily as long as it is affordable, and the costs they need to pay are deterministic functions of feature changes. In this paper, we consider a different setting and focus on imitative strategic behaviors with unforeseeable outcomes, i.e., individuals manipulate/improve by imitating the features of those with positive labels, but the induced feature changes are unforeseeable. We first propose a Stackelberg game to model the interplay between individuals and the decision-maker, under which we examine how the decision-maker's ability to anticipate individual behavior affects its objective function and the individual's best response. We show that the objective difference between the two can be decomposed into three interpretable terms, with each representing the decision-maker's preference for a certain behavior. By exploring the roles of each term, we further illustrate how a decision-maker with adjusted preferences can simultaneously disincentivize manipulation, incentivize improvement, and promote fairness.
Counterfactually Fair Representation
Nov 09, 2023



The use of machine learning models in high-stake applications (e.g., healthcare, lending, college admission) has raised growing concerns due to potential biases against protected social groups. Various fairness notions and methods have been proposed to mitigate such biases. In this work, we focus on Counterfactual Fairness (CF), a fairness notion that is dependent on an underlying causal graph and first proposed by Kusner \textit{et al.}~\cite{kusner2017counterfactual}; it requires that the outcome an individual perceives is the same in the real world as it would be in a "counterfactual" world, in which the individual belongs to another social group. Learning fair models satisfying CF can be challenging. It was shown in \cite{kusner2017counterfactual} that a sufficient condition for satisfying CF is to \textbf{not} use features that are descendants of sensitive attributes in the causal graph. This implies a simple method that learns CF models only using non-descendants of sensitive attributes while eliminating all descendants. Although several subsequent works proposed methods that use all features for training CF models, there is no theoretical guarantee that they can satisfy CF. In contrast, this work proposes a new algorithm that trains models using all the available features. We theoretically and empirically show that models trained with this method can satisfy CF\footnote{The code repository for this work can be found in \url{https://github.com/osu-srml/CF_Representation_Learning}}.