 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Balancing for Fair Supervised Learning
Nov 07, 2023



Supervised learning models have been used in various domains such as lending, college admission, face recognition, natural language processing, etc. However, they may inherit pre-existing biases from training data and exhibit discrimination against protected social groups. Various fairness notions have been proposed to address unfairness issues. In this work, we focus on Equalized Loss (EL), a fairness notion that requires the expected loss to be (approximately) equalized across different groups. Imposing EL on the learning process leads to a non-convex optimization problem even if the loss function is convex, and the existing fair learning algorithms cannot properly be adopted to find the fair predictor under the EL constraint. This paper introduces an algorithm that can leverage off-the-shelf convex programming tools (e.g., CVXPY) to efficiently find the global optimum of this non-convex optimization. In particular, we propose the ELminimizer algorithm, which finds the optimal fair predictor under EL by reducing the non-convex optimization to a sequence of convex optimization problems. We theoretically prove that our algorithm finds the global optimal solution under certain conditions. Then, we support our theoretical results through several empirical studies.
Revisiting DeepFool: generalization and improvement
Mar 22, 2023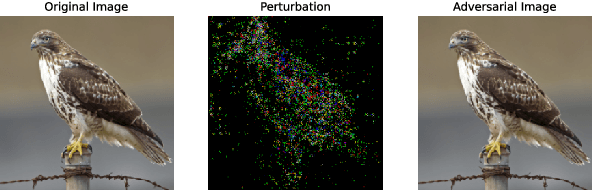

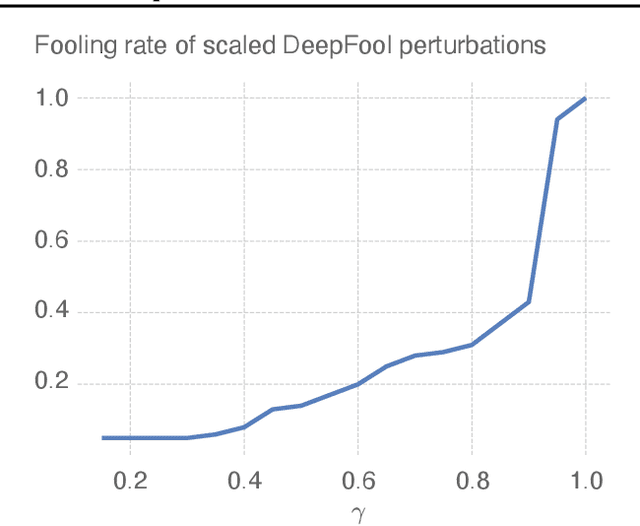

Deep neural networks have been known to be vulnerable to adversarial examples, which are inputs that are modified slightly to fool the network into making incorrect predictions. This has led to a significant amount of research on evaluating the robustness of these networks against such perturbations. One particularly important robustness metric is the robustness to minimal l2 adversarial perturbations. However, existing methods for evaluating this robustness metric are either computationally expensive or not very accurate. In this paper, we introduce a new family of adversarial attacks that strike a balance between effectiveness and computational efficiency. Our proposed attacks are generalizations of the well-known DeepFool (DF) attack, while they remain simple to understand and implement. We demonstrate that our attacks outperform existing methods in terms of both effectiveness and computational efficiency. Our proposed attacks are also suitable for evaluating the robustness of large models and can be used to perform adversarial training (AT) to achieve state-of-the-art robustness to minimal l2 adversarial perturbations.
Learning machines for health and beyond
Mar 02, 2023

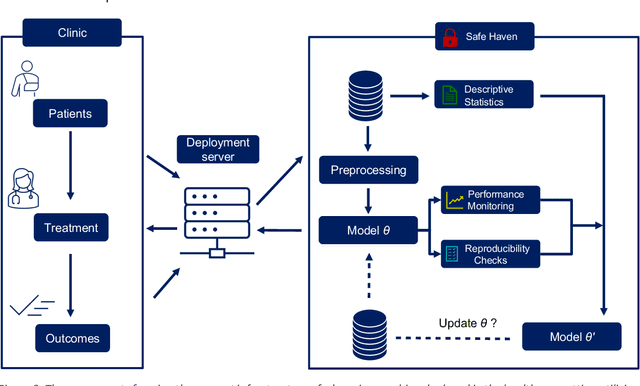
Machine learning techniques are effective for building predictive models because they are good at identifying patterns in large datasets. Development of a model for complex real life problems often stops at the point of publication, proof of concept or when made accessible through some mode of deployment. However, a model in the medical domain risks becoming obsolete as soon as patient demographic changes. The maintenance and monitoring of predictive models post-publication is crucial to guarantee their safe and effective long term use. As machine learning techniques are effectively trained to look for patterns in available datasets, the performance of a model for complex real life problems will not peak and remain fixed at the point of publication or even point of deployment. Rather, data changes over time, and they also changed when models are transported to new places to be used by new demography.
Symbolic Metamodels for Interpreting Black-boxes Using Primitive Functions
Feb 09, 2023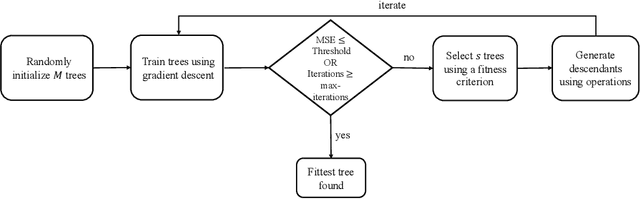



One approach for interpreting black-box machine learning models is to find a global approximation of the model using simple interpretable functions, which is called a metamodel (a model of the model). Approximating the black-box with a metamodel can be used to 1) estimate instance-wise feature importance; 2) understand the functional form of the model; 3) analyze feature interactions. In this work, we propose a new method for finding interpretable metamodels. Our approach utilizes Kolmogorov superposition theorem, which expresses multivariate functions as a composition of univariate functions (our primitive parameterized functions). This composition can be represented in the form of a tree. Inspired by symbolic regression, we use a modified form of genetic programming to search over different tree configurations. Gradient descent (GD) is used to optimize the parameters of a given configuration. Our method is a novel memetic algorithm that uses GD not only for training numerical constants but also for the training of building blocks. Using several experiments, we show that our method outperforms recent metamodeling approaches suggested for interpreting black-boxes.
An Information-theoretical Approach to Semi-supervised Learning under Covariate-shift
Feb 24, 2022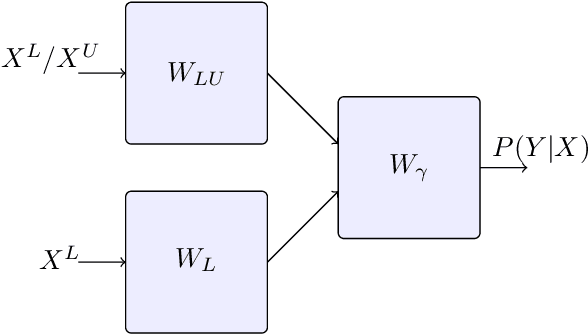

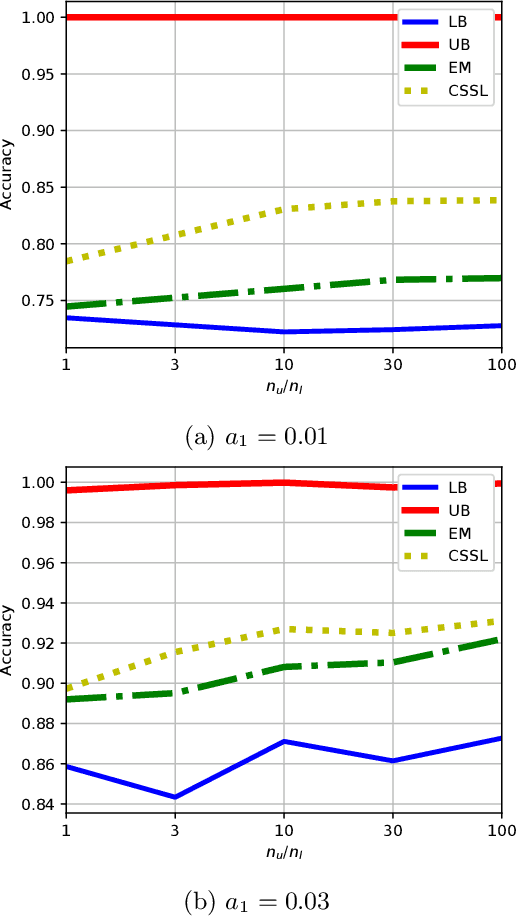
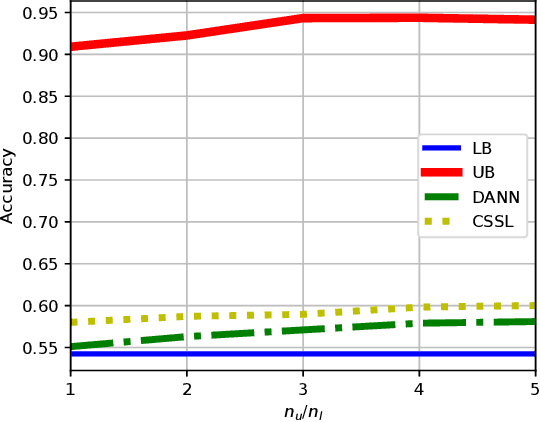
A common assumption in semi-supervised learning is that the labeled, unlabeled, and test data are drawn from the same distribution. However, this assumption is not satisfied in many applications. In many scenarios, the data is collected sequentially (e.g., healthcare) and the distribution of the data may change over time often exhibiting so-called covariate shifts. In this paper, we propose an approach for semi-supervised learning algorithms that is capable of addressing this issue. Our framework also recovers some popular methods, including entropy minimization and pseudo-labeling. We provide new information-theoretical based generalization error upper bounds inspired by our novel framework. Our bounds are applicable to both general semi-supervised learning and the covariate-shift scenario. Finally, we show numerically that our method outperforms previous approaches proposed for semi-supervised learning under the covariate shift.
Fair Sequential Selection Using Supervised Learning Models
Oct 26, 2021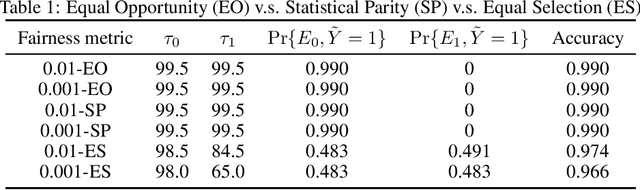
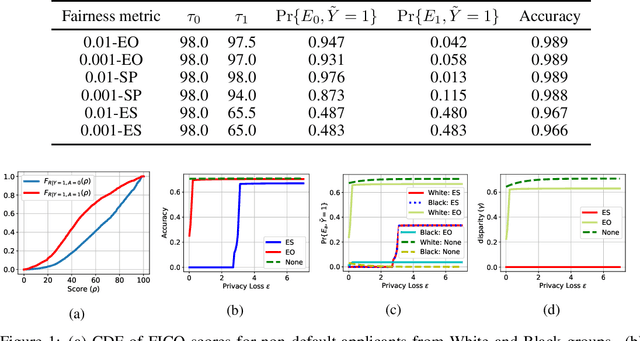
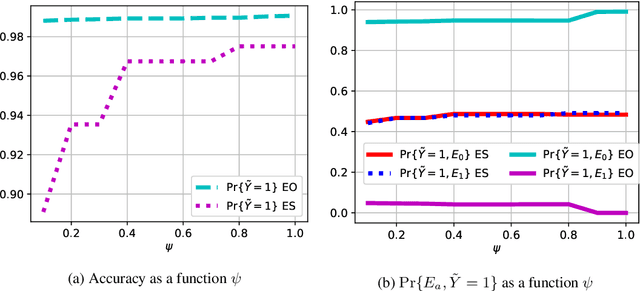
We consider a selection problem where sequentially arrived applicants apply for a limited number of positions/jobs. At each time step, a decision maker accepts or rejects the given applicant using a pre-trained supervised learning model until all the vacant positions are filled. In this paper, we discuss whether the fairness notions (e.g., equal opportunity, statistical parity, etc.) that are commonly used in classification problems are suitable for the sequential selection problems. In particular, we show that even with a pre-trained model that satisfies the common fairness notions, the selection outcomes may still be biased against certain demographic groups. This observation implies that the fairness notions used in classification problems are not suitable for a selection problem where the applicants compete for a limited number of positions. We introduce a new fairness notion, ``Equal Selection (ES),'' suitable for sequential selection problems and propose a post-processing approach to satisfy the ES fairness notion. We also consider a setting where the applicants have privacy concerns, and the decision maker only has access to the noisy version of sensitive attributes. In this setting, we can show that the perfect ES fairness can still be attained under certain conditions.
Conservative Policy Construction Using Variational Autoencoders for Logged Data with Missing Values
Sep 08, 2021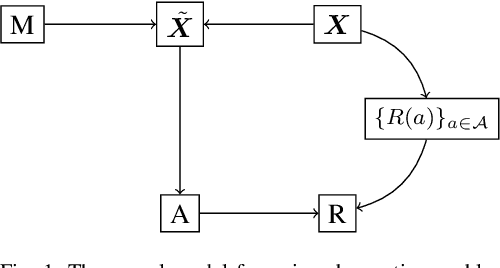
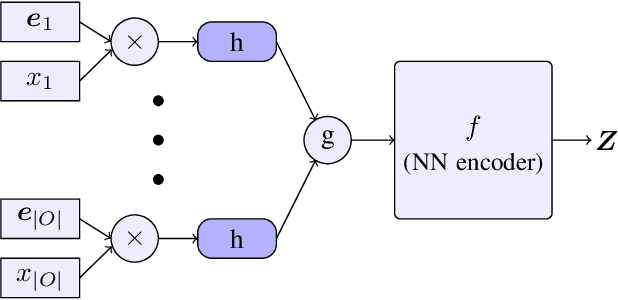
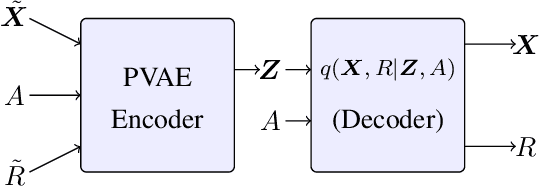
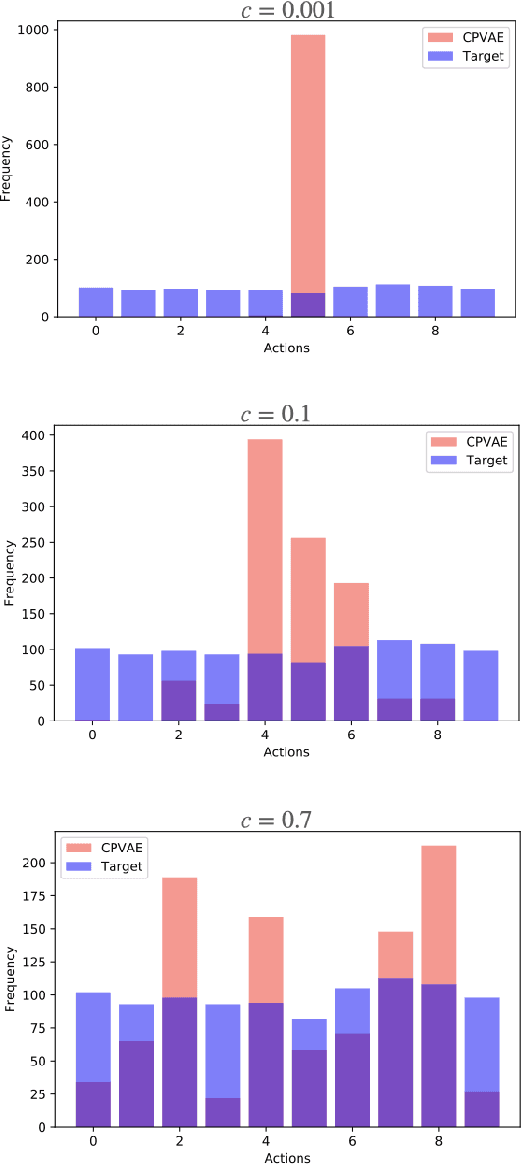
In high-stakes applications of data-driven decision making like healthcare, it is of paramount importance to learn a policy that maximizes the reward while avoiding potentially dangerous actions when there is uncertainty. There are two main challenges usually associated with this problem. Firstly, learning through online exploration is not possible due to the critical nature of such applications. Therefore, we need to resort to observational datasets with no counterfactuals. Secondly, such datasets are usually imperfect, additionally cursed with missing values in the attributes of features. In this paper, we consider the problem of constructing personalized policies using logged data when there are missing values in the attributes of features in both training and test data. The goal is to recommend an action (treatment) when $\Xt$, a degraded version of $\Xb$ with missing values, is observed. We consider three strategies for dealing with missingness. In particular, we introduce the \textit{conservative strategy} where the policy is designed to safely handle the uncertainty due to missingness. In order to implement this strategy we need to estimate posterior distribution $p(\Xb|\Xt)$, we use variational autoencoder to achieve this. In particular, our method is based on partial variational autoencoders (PVAE) which are designed to capture the underlying structure of features with missing values.
Improving Fairness and Privacy in Selection Problems
Dec 07, 2020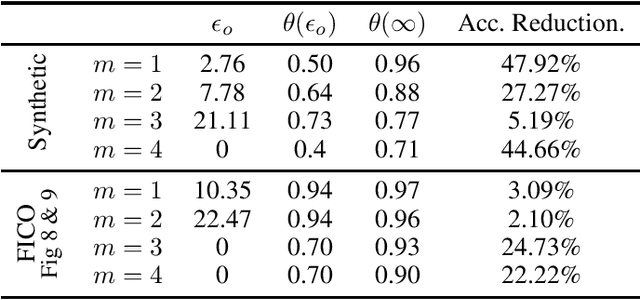
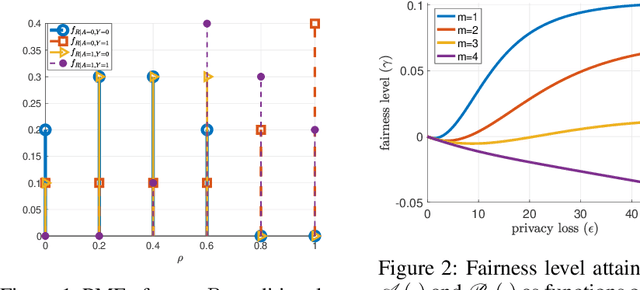

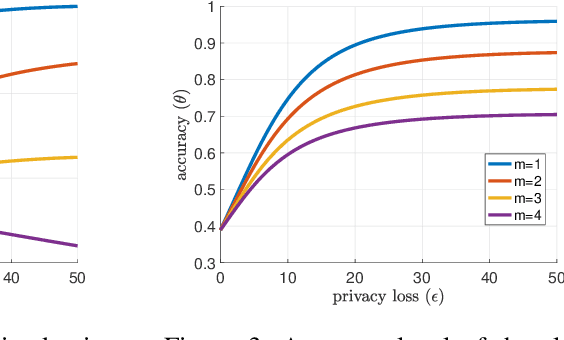
Supervised learning models have been increasingly used for making decisions about individuals in applications such as hiring, lending, and college admission. These models may inherit pre-existing biases from training datasets and discriminate against protected attributes (e.g., race or gender). In addition to unfairness, privacy concerns also arise when the use of models reveals sensitive personal information. Among various privacy notions, differential privacy has become popular in recent years. In this work, we study the possibility of using a differentially private exponential mechanism as a post-processing step to improve both fairness and privacy of supervised learning models. Unlike many existing works, we consider a scenario where a supervised model is used to select a limited number of applicants as the number of available positions is limited. This assumption is well-suited for various scenarios, such as job application and college admission. We use ``equal opportunity'' as the fairness notion and show that the exponential mechanisms can make the decision-making process perfectly fair. Moreover, the experiments on real-world datasets show that the exponential mechanism can improve both privacy and fairness, with a slight decrease in accuracy compared to the model without post-processing.