 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Fluent Optimization-Based Adversarial Prompts via Sequential Entropy Changes
May 19, 2026Optimization-based adversarial suffixes can jailbreak aligned large language models (LLMs) while remaining fluent, weakening static and windowed perplexity-based detectors. We cast adversarial suffix detection as an online change-point detection problem over the token-level next-token entropy stream. Using the LLM system prompt to estimate a robust baseline, we standardize user-token entropies and apply a one-sided CUSUM statistic. The resulting detector, CPD Online (CPD), is model-agnostic, training-free, runs online, and localizes the adversarial suffix onset. On a benchmark of 1,012 optimization-based suffix attacks (GCG, AutoDAN, AdvPrompter, BEAST, AutoDAN-HGA) and 1,012 perplexity-controlled benign prompts, CPD improves F1 over the strongest windowed-perplexity baseline on all six open-weight chat models (LLaMA-2-7B/13B, Vicuna-7B/13B, Qwen2.5-7B/14B). On LLaMA-2-7B at the canonical CUSUM setting ($k=0$), CPD reaches AUROC $0.88$ and F1 $0.82$. Beyond prompt-level detection, CPD concentrates 79.6% of its triggers inside the adversarial suffix, versus 17-46% for windowed perplexity. Finally, when used as a lightweight gate for LLaMA Guard, CPD reduces guard calls by 17-22% on a high-volume, benign-dominated deployment while preserving guard-level detection quality
Beyond Training for Cultural Awareness: The Role of Dataset Linguistic Structure in Large Language Models
Feb 01, 2026The global deployment of large language models (LLMs) has raised concerns about cultural misalignment, yet the linguistic properties of fine-tuning datasets used for cultural adaptation remain poorly understood. We adopt a dataset-centric view of cultural alignment and ask which linguistic properties of fine-tuning data are associated with cultural performance, whether these properties are predictive prior to training, and how these effects vary across models. We compute lightweight linguistic, semantic, and structural metrics for Arabic, Chinese, and Japanese datasets and apply principal component analysis separately within each language. This design ensures that the resulting components capture variation among datasets written in the same language rather than differences between languages. The resulting components correspond to broadly interpretable axes related to semantic coherence, surface-level lexical and syntactic diversity, and lexical or structural richness, though their composition varies across languages. We fine-tune three major LLM families (LLaMA, Mistral, DeepSeek) and evaluate them on benchmarks of cultural knowledge, values, and norms. While PCA components correlate with downstream performance, these associations are strongly model-dependent. Through controlled subset interventions, we show that lexical-oriented components (PC3) are the most robust, yielding more consistent performance across models and benchmarks, whereas emphasizing semantic or diversity extremes (PC1-PC2) is often neutral or harmful.
Noisy but Valid: Robust Statistical Evaluation of LLMs with Imperfect Judges
Jan 28, 2026Reliable certification of Large Language Models (LLMs)-verifying that failure rates are below a safety threshold-is critical yet challenging. While "LLM-as-a-Judge" offers scalability, judge imperfections, noise, and bias can invalidate statistical guarantees. We introduce a "Noisy but Valid" hypothesis testing framework to address this. By leveraging a small human-labelled calibration set to estimate the judge's True Positive and False Positive Rates (TPR/FPR), we derive a variance-corrected critical threshold applied to a large judge-labelled dataset. Crucially, our framework theoretically guarantees finite-sample Type-I error control (validity) despite calibration uncertainty. This distinguishes our work from Prediction-Powered Inference (PPI), positioning our method as a diagnostic tool that explicitly models judge behavior rather than a black-box estimator. Our contributions include: (1) Theoretical Guarantees: We derive the exact conditions under which noisy testing yields higher statistical power than direct evaluation; (2) Empirical Validation: Experiments on Jigsaw Comment, Hate Speech and SafeRLHF confirm our theory; (3) The Oracle Gap: We reveal a significant performance gap between practical methods and the theoretical "Oracle" (perfectly known judge parameters), quantifying the cost of estimation. Specifically, we provide the first systematic treatment of the imperfect-judge setting, yielding interpretable diagnostics of judge reliability and clarifying how evaluation power depends on judge quality, dataset size, and certification levels. Together, these results sharpen understanding of statistical evaluation with LLM judges, and highlight trade-offs among competing inferential tools.
Seeing and Reasoning with Confidence: Supercharging Multimodal LLMs with an Uncertainty-Aware Agentic Framework
Mar 11, 2025Multimodal large language models (MLLMs) show promise in tasks like visual question answering (VQA) but still face challenges in multimodal reasoning. Recent works adapt agentic frameworks or chain-of-thought (CoT) reasoning to improve performance. However, CoT-based multimodal reasoning often demands costly data annotation and fine-tuning, while agentic approaches relying on external tools risk introducing unreliable output from these tools. In this paper, we propose Seeing and Reasoning with Confidence (SRICE), a training-free multimodal reasoning framework that integrates external vision models with uncertainty quantification (UQ) into an MLLM to address these challenges. Specifically, SRICE guides the inference process by allowing MLLM to autonomously select regions of interest through multi-stage interactions with the help of external tools. We propose to use a conformal prediction-based approach to calibrate the output of external tools and select the optimal tool by estimating the uncertainty of an MLLM's output. Our experiment shows that the average improvement of SRICE over the base MLLM is 4.6% on five datasets and the performance on some datasets even outperforms fine-tuning-based methods, revealing the significance of ensuring reliable tool use in an MLLM agent.
Optimization Guarantees of Unfolded ISTA and ADMM Networks With Smooth Soft-Thresholding
Sep 12, 2023



Solving linear inverse problems plays a crucial role in numerous applications. Algorithm unfolding based, model-aware data-driven approaches have gained significant attention for effectively addressing these problems. Learned iterative soft-thresholding algorithm (LISTA) and alternating direction method of multipliers compressive sensing network (ADMM-CSNet) are two widely used such approaches, based on ISTA and ADMM algorithms, respectively. In this work, we study optimization guarantees, i.e., achieving near-zero training loss with the increase in the number of learning epochs, for finite-layer unfolded networks such as LISTA and ADMM-CSNet with smooth soft-thresholding in an over-parameterized (OP) regime. We achieve this by leveraging a modified version of the Polyak-Lojasiewicz, denoted PL$^*$, condition. Satisfying the PL$^*$ condition within a specific region of the loss landscape ensures the existence of a global minimum and exponential convergence from initialization using gradient descent based methods. Hence, we provide conditions, in terms of the network width and the number of training samples, on these unfolded networks for the PL$^*$ condition to hold. We achieve this by deriving the Hessian spectral norm of these networks. Additionally, we show that the threshold on the number of training samples increases with the increase in the network width. Furthermore, we compare the threshold on training samples of unfolded networks with that of a standard fully-connected feed-forward network (FFNN) with smooth soft-thresholding non-linearity. We prove that unfolded networks have a higher threshold value than FFNN. Consequently, one can expect a better expected error for unfolded networks than FFNN.
Generalization and Estimation Error Bounds for Model-based Neural Networks
Apr 19, 2023



Model-based neural networks provide unparalleled performance for various tasks, such as sparse coding and compressed sensing problems. Due to the strong connection with the sensing model, these networks are interpretable and inherit prior structure of the problem. In practice, model-based neural networks exhibit higher generalization capability compared to ReLU neural networks. However, this phenomenon was not addressed theoretically. Here, we leverage complexity measures including the global and local Rademacher complexities, in order to provide upper bounds on the generalization and estimation errors of model-based networks. We show that the generalization abilities of model-based networks for sparse recovery outperform those of regular ReLU networks, and derive practical design rules that allow to construct model-based networks with guaranteed high generalization. We demonstrate through a series of experiments that our theoretical insights shed light on a few behaviours experienced in practice, including the fact that ISTA and ADMM networks exhibit higher generalization abilities (especially for small number of training samples), compared to ReLU networks.
Learning Algorithm Generalization Error Bounds via Auxiliary Distributions
Oct 02, 2022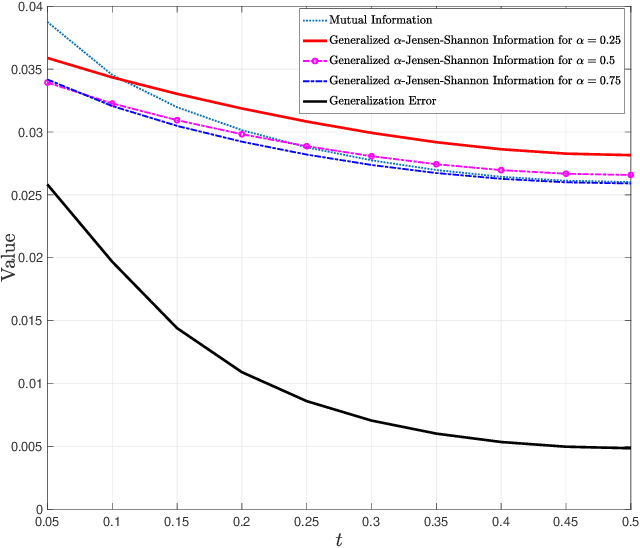
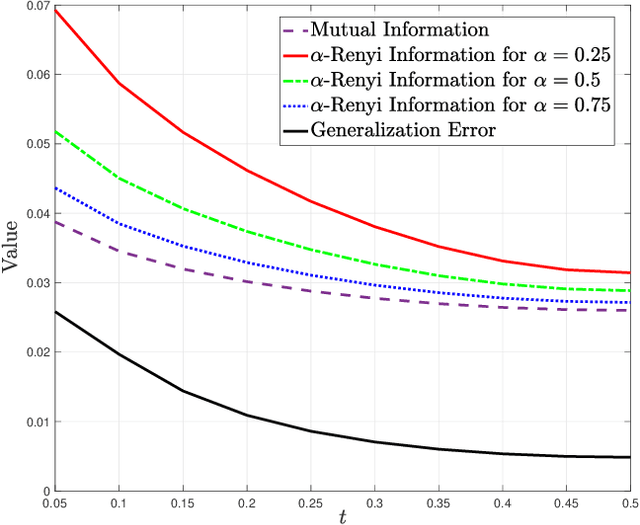
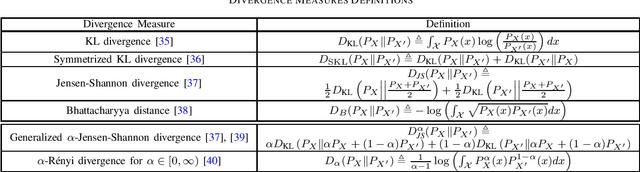
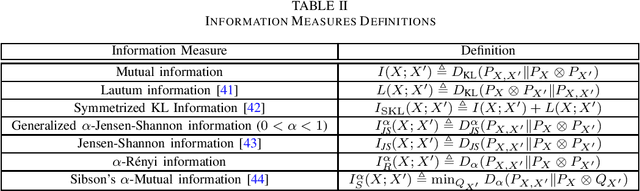
Generalization error boundaries are essential for comprehending how well machine learning models work. In this work, we suggest a creative method, i.e., the Auxiliary Distribution Method, that derives new upper bounds on generalization errors that are appropriate for supervised learning scenarios. We show that our general upper bounds can be specialized under some conditions to new bounds involving the generalized $\alpha$-Jensen-Shannon, $\alpha$-R\'enyi ($0< \alpha < 1$) information between random variable modeling the set of training samples and another random variable modeling the set of hypotheses. Our upper bounds based on generalized $\alpha$-Jensen-Shannon information are also finite. Additionally, we demonstrate how our auxiliary distribution method can be used to derive the upper bounds on generalization error under the distribution mismatch scenario in supervised learning algorithms, where the distributional mismatch is modeled as $\alpha$-Jensen-Shannon or $\alpha$-R\'enyi ($0< \alpha < 1$) between the distribution of test and training data samples. We also outline the circumstances in which our proposed upper bounds might be tighter than other earlier upper bounds.
Theoretical Perspectives on Deep Learning Methods in Inverse Problems
Jun 29, 2022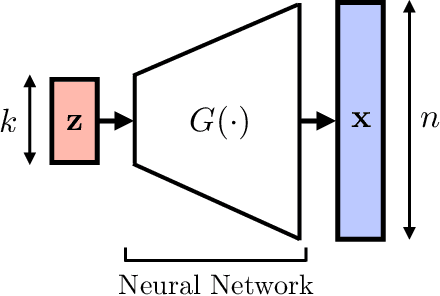
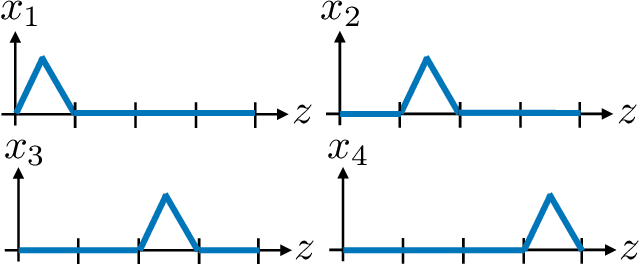
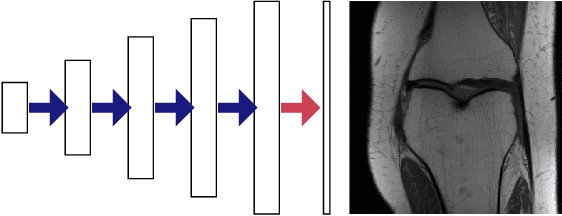
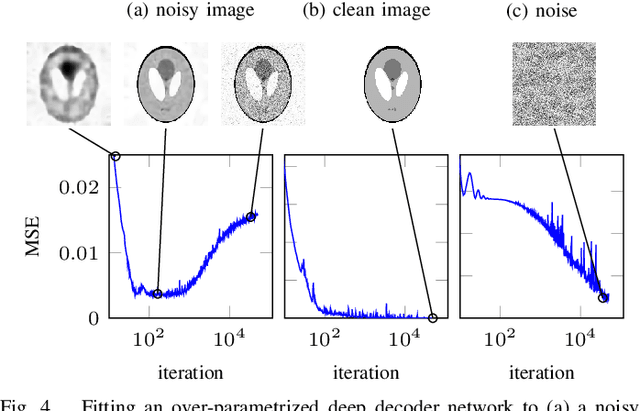
In recent years, there have been significant advances in the use of deep learning methods in inverse problems such as denoising, compressive sensing, inpainting, and super-resolution. While this line of works has predominantly been driven by practical algorithms and experiments, it has also given rise to a variety of intriguing theoretical problems. In this paper, we survey some of the prominent theoretical developments in this line of works, focusing in particular on generative priors, untrained neural network priors, and unfolding algorithms. In addition to summarizing existing results in these topics, we highlight several ongoing challenges and open problems.
An Information-theoretical Approach to Semi-supervised Learning under Covariate-shift
Feb 24, 2022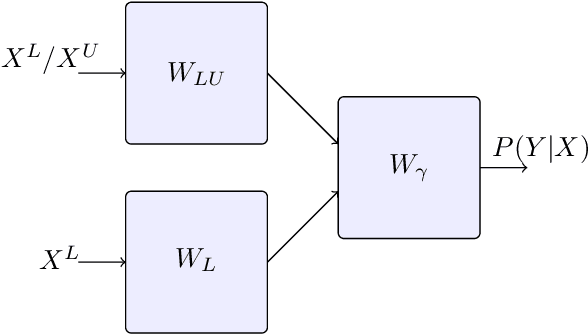

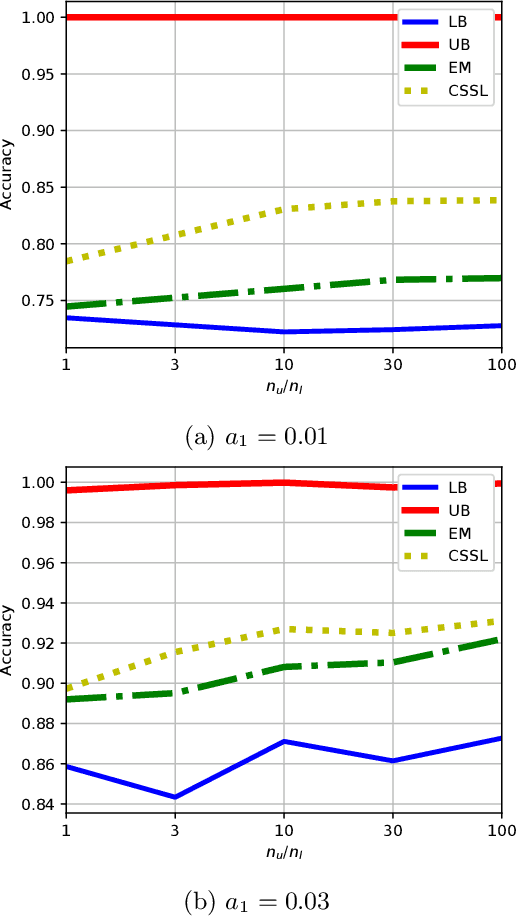
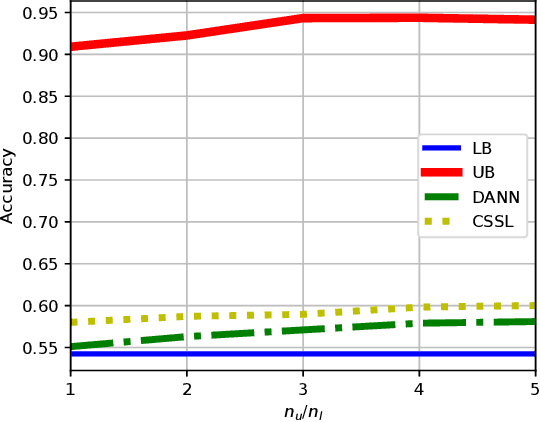
A common assumption in semi-supervised learning is that the labeled, unlabeled, and test data are drawn from the same distribution. However, this assumption is not satisfied in many applications. In many scenarios, the data is collected sequentially (e.g., healthcare) and the distribution of the data may change over time often exhibiting so-called covariate shifts. In this paper, we propose an approach for semi-supervised learning algorithms that is capable of addressing this issue. Our framework also recovers some popular methods, including entropy minimization and pseudo-labeling. We provide new information-theoretical based generalization error upper bounds inspired by our novel framework. Our bounds are applicable to both general semi-supervised learning and the covariate-shift scenario. Finally, we show numerically that our method outperforms previous approaches proposed for semi-supervised learning under the covariate shift.
Robust lEarned Shrinkage-Thresholding (REST): Robust unrolling for sparse recover
Oct 20, 2021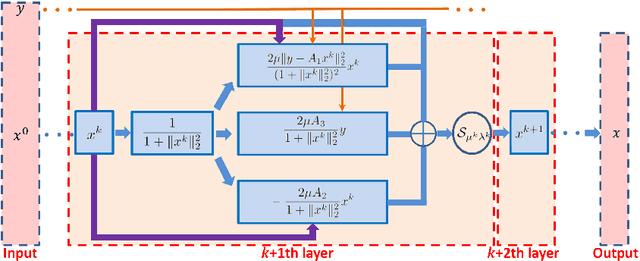



In this paper, we consider deep neural networks for solving inverse problems that are robust to forward model mis-specifications. Specifically, we treat sensing problems with model mismatch where one wishes to recover a sparse high-dimensional vector from low-dimensional observations subject to uncertainty in the measurement operator. We then design a new robust deep neural network architecture by applying algorithm unfolding techniques to a robust version of the underlying recovery problem. Our proposed network - named Robust lEarned Shrinkage-Thresholding (REST) - exhibits an additional normalization processing compared to Learned Iterative Shrinkage-Thresholding Algorithm (LISTA), leading to reliable recovery of the signal under sample-wise varying model mismatch. The proposed REST network is shown to outperform state-of-the-art model-based and data-driven algorithms in both compressive sensing and radar imaging problems wherein model mismatch is taken into consideration.