 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatched Stochastic Linear Bandits with 1-Bit Communication Constraints
May 29, 2026We study stochastic linear bandits under a natural combination of batching and communication constraints: the time horizon is partitioned into batches of equal size $B$, and during each batch the learner sends $B$ requested arm pulls to an agent, who then observes the corresponding $B$ rewards and responds with a single bit of feedback to the learner. For each batch, the learner specifies the 1-bit quantization rule the agent uses, which may depend on all previously received bits but not on any past rewards directly. This setting addresses a significant yet unexplored ``middle ground'' between previous models having per-round quantization only or total bit budgets only. We establish a minimax lower bound showing that $Ω(B\min\{d,\log\lvert \mathcal{A} \rvert\})$ regret is unavoidable due to the 1-bit communication bottleneck, even in the absence of noise. Combined with standard statistical limits, this yields a general lower bound of $\widetildeΩ(B\min\{d,\log\lvert \mathcal{A} \rvert\} + \sqrt{dT \min\{d,\log\lvert \mathcal{A} \rvert\}})$. We develop two phased-elimination algorithms based on $G$-optimal designs and 1-bit mean estimation. The first achieves $\widetilde{O}(dB + d\sqrt{T})$ regret, matching the lower bound up to logarithmic factors when $\lvert \mathcal{A} \rvert = \exp(Ω(d))$, and the second incorporates a safe-arm identification and warm-start procedure to obtain $\widetilde{O}(B\log\lvert \mathcal{A} \rvert + d^{3/2}\sqrt{B} + \sqrt{dT\log\lvert \mathcal{A} \rvert})$ regret, which is near-optimal in broad scaling regimes of $(\lvert \mathcal{A} \rvert, B, d, T)$. Together, our results demonstrate that a single bit of feedback per batch suffices to nearly match the minimax regret of unconstrained linear bandits in broad scaling regimes, even for batch sizes as large as $Θ(\sqrt{T})$.
Near-Optimal Regret in Adversarial Kernel Bandits
May 26, 2026We study the adversarial kernel bandit problem, in which the loss at each round is induced by an arbitrary bounded element of a reproducing kernel Hilbert space (RKHS). We propose an exponential-weights algorithm built on a regularized importance-weighted loss estimator, together with an explicit correction term that cancels the bias introduced by the regularization. Our main result bounds the regret by $\widetilde{O}\big(\sqrt{T\, d_*(λ)\,\log|{X}|}\big)$, where $d_*(λ)$ is a widely-adopted notion of effective dimension that captures the complexity of the kernel. Up to logarithmic factors, this matches the known rate achieved in the related stochastic kernel bandit problem. A notable application is the Matérn$(ν,d)$ kernel with smoothness parameter $ν$ on $\mathbb{R}^d$, for which our bound specializes to $\widetilde{O}\big(T^{(ν+d)/(2ν+d)}\big)$, improving over the best-known prior rate of Chatterji et al. [2019] while simultaneously removing the rank-one adversary assumption required by their analysis. Moreover, this rate is the same as the known optimal rate for stochastic kernel bandits, and also matches a lower bound from concurrent work up to a $\log T$ factor.
Entropy Equivalence Testing
May 22, 2026We introduce the problem of \emph{entropy equivalence testing} for probability distributions, a relaxation of the well-studied closeness testing problem, where the distribution testing algorithm is now only required to distinguish, given samples from two unknown distributions $p,q$ and a parameter $\varepsilon \in(0,1/2]$, between $p=q$ and $|H(p)-H(q)| \geq \varepsilon$ (where $H$ denotes the Shannon entropy). We provide a time- and sample-efficient algorithm for this task, showing that the optimal sample complexity for this task can be significantly lower than that of closeness testing. As an application, we leverage this result to provide the first non-trivial testing algorithm for (standard) closeness of low-degree \emph{Bayesian networks}, which significantly improves on either the sample or time complexity of a baseline based on full learning.
Order-Optimal Sequential 1-Bit Mean Estimation in General Tail Regimes
Apr 09, 2026In this paper, we study the problem of mean estimation under strict 1-bit communication constraints. We propose a novel adaptive mean estimator based solely on randomized threshold queries, where each 1-bit outcome indicates whether a given sample exceeds a sequentially chosen threshold. Our estimator is $(ε, δ)$-PAC for any distribution with a bounded mean $μ\in [-λ, λ]$ and a bounded $k$-th central moment $\mathbb{E}[|X-μ|^k] \le σ^k$ for any fixed $k > 1$. Crucially, our sample complexity is order-optimal in all such tail regimes, i.e., for every such $k$ value. For $k \neq 2$, our estimator's sample complexity matches the unquantized minimax lower bounds plus an unavoidable $O(\log(λ/σ))$ localization cost. For the finite-variance case ($k=2$), our estimator's sample complexity has an extra multiplicative $O(\log(σ/ε))$ penalty, and we establish a novel information-theoretic lower bound showing that this penalty is a fundamental limit of 1-bit quantization. We also establish a significant adaptivity gap: for both threshold queries and more general interval queries, the sample complexity of any non-adaptive estimator must scale linearly with the search space parameter $λ/σ$, rendering it vastly less sample efficient than our adaptive approach. Finally, we present algorithmic variants that (i) handle an unknown sampling budget, (ii) adapt to an unknown scale parameter~$σ$ given (possibly loose) bounds, and (iii) require only two stages of adaptivity at the expense of more complicated general 1-bit queries.
Batched Kernelized Bandits: Refinements and Extensions
Mar 13, 2026In this paper, we consider the problem of black-box optimization with noisy feedback revealed in batches, where the unknown function to optimize has a bounded norm in some Reproducing Kernel Hilbert Space (RKHS). We refer to this as the Batched Kernelized Bandits problem, and refine and extend existing results on regret bounds. For algorithmic upper bounds, (Li and Scarlett, 2022) shows that $B=O(\log\log T)$ batches suffice to attain near-optimal regret, where $T$ is the time horizon and $B$ is the number of batches. We further refine this by (i) finding the optimal number of batches including constant factors (to within $1+o(1)$), and (ii) removing a factor of $B$ in the regret bound. For algorithm-independent lower bounds, noticing that existing results only apply when the batch sizes are fixed in advance, we present novel lower bounds when the batch sizes are chosen adaptively, and show that adaptive batches have essentially same minimax regret scaling as fixed batches. Furthermore, we consider a robust setting where the goal is to choose points for which the function value remains high even after an adversarial perturbation. We present the robust-BPE algorithm, and show that a suitably-defined cumulative regret notion incurs the same bound as the non-robust setting, and derive a simple regret bound significantly below that of previous work.
Envy-Free Allocation of Indivisible Goods via Noisy Queries
Feb 06, 2026We introduce a problem of fairly allocating indivisible goods (items) in which the agents' valuations cannot be observed directly, but instead can only be accessed via noisy queries. In the two-agent setting with Gaussian noise and bounded valuations, we derive upper and lower bounds on the required number of queries for finding an envy-free allocation in terms of the number of items, $m$, and the negative-envy of the optimal allocation, $Δ$. In particular, when $Δ$ is not too small (namely, $Δ\gg m^{1/4}$), we establish that the optimal number of queries scales as $\frac{\sqrt m }{(Δ/ m)^2} = \frac{m^{2.5}}{Δ^2}$ up to logarithmic factors. Our upper bound is based on non-adaptive queries and a simple thresholding-based allocation algorithm that runs in polynomial time, while our lower bound holds even under adaptive queries and arbitrary computation time.
A Distribution Testing Approach to Clustering Distributions
Dec 09, 2025We study the following distribution clustering problem: Given a hidden partition of $k$ distributions into two groups, such that the distributions within each group are the same, and the two distributions associated with the two clusters are $\varepsilon$-far in total variation, the goal is to recover the partition. We establish upper and lower bounds on the sample complexity for two fundamental cases: (1) when one of the cluster's distributions is known, and (2) when both are unknown. Our upper and lower bounds characterize the sample complexity's dependence on the domain size $n$, number of distributions $k$, size $r$ of one of the clusters, and distance $\varepsilon$. In particular, we achieve tightness with respect to $(n,k,r,\varepsilon)$ (up to an $O(\log k)$ factor) for all regimes.
Sequential 1-bit Mean Estimation with Near-Optimal Sample Complexity
Sep 26, 2025In this paper, we study the problem of distributed mean estimation with 1-bit communication constraints. We propose a mean estimator that is based on (randomized and sequentially-chosen) interval queries, whose 1-bit outcome indicates whether the given sample lies in the specified interval. Our estimator is $(\epsilon, \delta)$-PAC for all distributions with bounded mean ($-\lambda \le \mathbb{E}(X) \le \lambda $) and variance ($\mathrm{Var}(X) \le \sigma^2$) for some known parameters $\lambda$ and $\sigma$. We derive a sample complexity bound $\widetilde{O}\big( \frac{\sigma^2}{\epsilon^2}\log\frac{1}{\delta} + \log\frac{\lambda}{\sigma}\big)$, which matches the minimax lower bound for the unquantized setting up to logarithmic factors and the additional $\log\frac{\lambda}{\sigma}$ term that we show to be unavoidable. We also establish an adaptivity gap for interval-query based estimators: the best non-adaptive mean estimator is considerably worse than our adaptive mean estimator for large $\frac{\lambda}{\sigma}$. Finally, we give tightened sample complexity bounds for distributions with stronger tail decay, and present additional variants that (i) handle an unknown sampling budget (ii) adapt to the unknown true variance given (possibly loose) upper and lower bounds on the variance, and (iii) use only two stages of adaptivity at the expense of more complicated (non-interval) queries.
Improved Regret Bounds for Linear Bandits with Heavy-Tailed Rewards
Jun 05, 2025


We study stochastic linear bandits with heavy-tailed rewards, where the rewards have a finite $(1+\epsilon)$-absolute central moment bounded by $\upsilon$ for some $\epsilon \in (0,1]$. We improve both upper and lower bounds on the minimax regret compared to prior work. When $\upsilon = \mathcal{O}(1)$, the best prior known regret upper bound is $\tilde{\mathcal{O}}(d T^{\frac{1}{1+\epsilon}})$. While a lower with the same scaling has been given, it relies on a construction using $\upsilon = \mathcal{O}(d)$, and adapting the construction to the bounded-moment regime with $\upsilon = \mathcal{O}(1)$ yields only a $\Omega(d^{\frac{\epsilon}{1+\epsilon}} T^{\frac{1}{1+\epsilon}})$ lower bound. This matches the known rate for multi-armed bandits and is generally loose for linear bandits, in particular being $\sqrt{d}$ below the optimal rate in the finite-variance case ($\epsilon = 1$). We propose a new elimination-based algorithm guided by experimental design, which achieves regret $\tilde{\mathcal{O}}(d^{\frac{1+3\epsilon}{2(1+\epsilon)}} T^{\frac{1}{1+\epsilon}})$, thus improving the dependence on $d$ for all $\epsilon \in (0,1)$ and recovering a known optimal result for $\epsilon = 1$. We also establish a lower bound of $\Omega(d^{\frac{2\epsilon}{1+\epsilon}} T^{\frac{1}{1+\epsilon}})$, which strictly improves upon the multi-armed bandit rate and highlights the hardness of heavy-tailed linear bandit problems. For finite action sets, we derive similarly improved upper and lower bounds for regret. Finally, we provide action set dependent regret upper bounds showing that for some geometries, such as $l_p$-norm balls for $p \le 1 + \epsilon$, we can further reduce the dependence on $d$, and we can handle infinite-dimensional settings via the kernel trick, in particular establishing new regret bounds for the Mat\'ern kernel that are the first to be sublinear for all $\epsilon \in (0, 1]$.
Statistical Mean Estimation with Coded Relayed Observations
May 14, 2025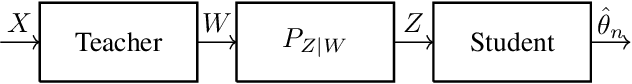
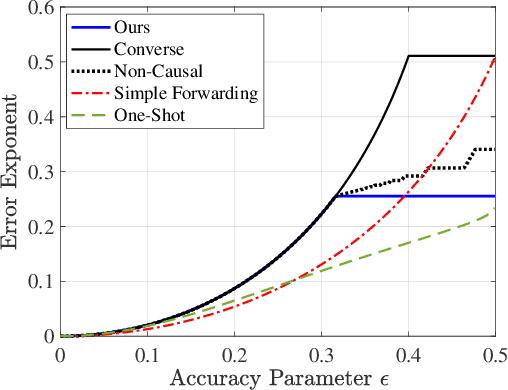
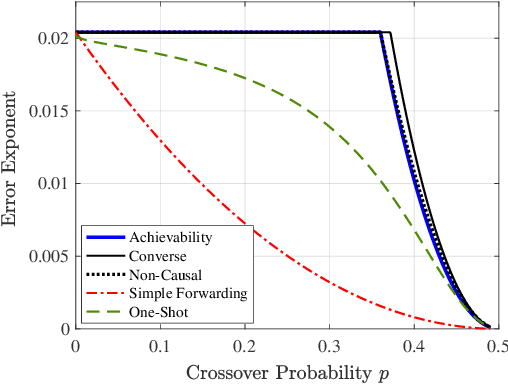
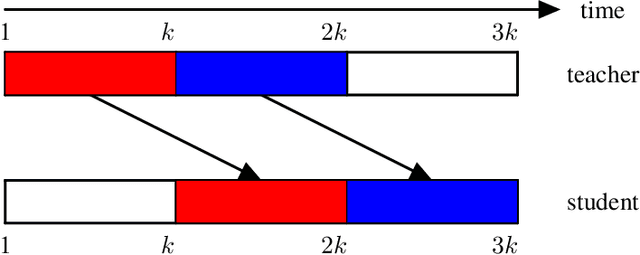
We consider a problem of statistical mean estimation in which the samples are not observed directly, but are instead observed by a relay (``teacher'') that transmits information through a memoryless channel to the decoder (``student''), who then produces the final estimate. We consider the minimax estimation error in the large deviations regime, and establish achievable error exponents that are tight in broad regimes of the estimation accuracy and channel quality. In contrast, two natural baseline methods are shown to yield strictly suboptimal error exponents. We initially focus on Bernoulli sources and binary symmetric channels, and then generalize to sub-Gaussian and heavy-tailed settings along with arbitrary discrete memoryless channels.