 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning
Oct 30, 2025Reinforcement finetuning (RFT) is a key technique for aligning Large Language Models (LLMs) with human preferences and enhancing reasoning, yet its effectiveness is highly sensitive to which tasks are explored during training. Uniform task sampling is inefficient, wasting computation on tasks that are either trivial or unsolvable, while existing task selection methods often suffer from high rollout costs, poor adaptivity, or incomplete evidence. We introduce \textbf{BOTS}, a unified framework for \textbf{B}ayesian \textbf{O}nline \textbf{T}ask \textbf{S}election in LLM reinforcement finetuning. Grounded in Bayesian inference, BOTS adaptively maintains posterior estimates of task difficulty as the model evolves. It jointly incorporates \emph{explicit evidence} from direct evaluations of selected tasks and \emph{implicit evidence} inferred from these evaluations for unselected tasks, with Thompson sampling ensuring a principled balance between exploration and exploitation. To make implicit evidence practical, we instantiate it with an ultra-light interpolation-based plug-in that estimates difficulties of unevaluated tasks without extra rollouts, adding negligible overhead. Empirically, across diverse domains and LLM scales, BOTS consistently improves data efficiency and performance over baselines and ablations, providing a practical and extensible solution for dynamic task selection in RFT.
LoReUn: Data Itself Implicitly Provides Cues to Improve Machine Unlearning
Jul 30, 2025Recent generative models face significant risks of producing harmful content, which has underscored the importance of machine unlearning (MU) as a critical technique for eliminating the influence of undesired data. However, existing MU methods typically assign the same weight to all data to be forgotten, which makes it difficult to effectively forget certain data that is harder to unlearn than others. In this paper, we empirically demonstrate that the loss of data itself can implicitly reflect its varying difficulty. Building on this insight, we introduce Loss-based Reweighting Unlearning (LoReUn), a simple yet effective plug-and-play strategy that dynamically reweights data during the unlearning process with minimal additional computational overhead. Our approach significantly reduces the gap between existing MU methods and exact unlearning in both image classification and generation tasks, effectively enhancing the prevention of harmful content generation in text-to-image diffusion models.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
State-space models are accurate and efficient neural operators for dynamical systems
Sep 05, 2024Physics-informed machine learning (PIML) has emerged as a promising alternative to classical methods for predicting dynamical systems, offering faster and more generalizable solutions. However, existing models, including recurrent neural networks (RNNs), transformers, and neural operators, face challenges such as long-time integration, long-range dependencies, chaotic dynamics, and extrapolation, to name a few. To this end, this paper introduces state-space models implemented in Mamba for accurate and efficient dynamical system operator learning. Mamba addresses the limitations of existing architectures by dynamically capturing long-range dependencies and enhancing computational efficiency through reparameterization techniques. To extensively test Mamba and compare against another 11 baselines, we introduce several strict extrapolation testbeds that go beyond the standard interpolation benchmarks. We demonstrate Mamba's superior performance in both interpolation and challenging extrapolation tasks. Mamba consistently ranks among the top models while maintaining the lowest computational cost and exceptional extrapolation capabilities. Moreover, we demonstrate the good performance of Mamba for a real-world application in quantitative systems pharmacology for assessing the efficacy of drugs in tumor growth under limited data scenarios. Taken together, our findings highlight Mamba's potential as a powerful tool for advancing scientific machine learning in dynamical systems modeling. (The code will be available at https://github.com/zheyuanhu01/State_Space_Model_Neural_Operator upon acceptance.)
Memory-Efficient Gradient Unrolling for Large-Scale Bi-level Optimization
Jun 20, 2024

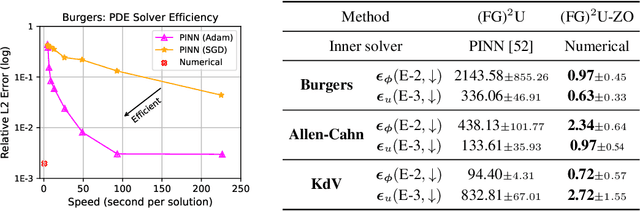

Bi-level optimization (BO) has become a fundamental mathematical framework for addressing hierarchical machine learning problems. As deep learning models continue to grow in size, the demand for scalable bi-level optimization solutions has become increasingly critical. Traditional gradient-based bi-level optimization algorithms, due to their inherent characteristics, are ill-suited to meet the demands of large-scale applications. In this paper, we introduce $\textbf{F}$orward $\textbf{G}$radient $\textbf{U}$nrolling with $\textbf{F}$orward $\textbf{F}$radient, abbreviated as $(\textbf{FG})^2\textbf{U}$, which achieves an unbiased stochastic approximation of the meta gradient for bi-level optimization. $(\text{FG})^2\text{U}$ circumvents the memory and approximation issues associated with classical bi-level optimization approaches, and delivers significantly more accurate gradient estimates than existing large-scale bi-level optimization approaches. Additionally, $(\text{FG})^2\text{U}$ is inherently designed to support parallel computing, enabling it to effectively leverage large-scale distributed computing systems to achieve significant computational efficiency. In practice, $(\text{FG})^2\text{U}$ and other methods can be strategically placed at different stages of the training process to achieve a more cost-effective two-phase paradigm. Further, $(\text{FG})^2\text{U}$ is easy to implement within popular deep learning frameworks, and can be conveniently adapted to address more challenging zeroth-order bi-level optimization scenarios. We provide a thorough convergence analysis and a comprehensive practical discussion for $(\text{FG})^2\text{U}$, complemented by extensive empirical evaluations, showcasing its superior performance in diverse large-scale bi-level optimization tasks.
FinerCut: Finer-grained Interpretable Layer Pruning for Large Language Models
May 28, 2024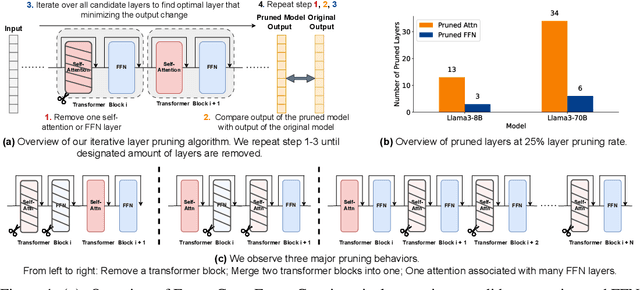
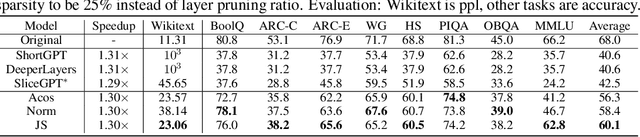
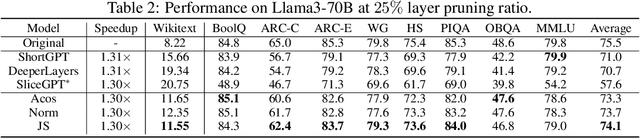
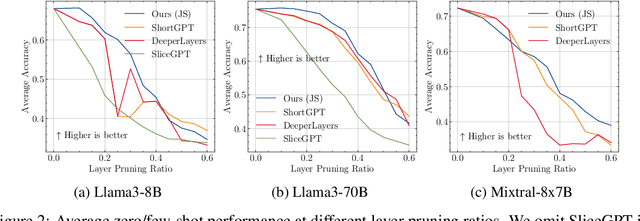
Overparametrized transformer networks are the state-of-the-art architecture for Large Language Models (LLMs). However, such models contain billions of parameters making large compute a necessity, while raising environmental concerns. To address these issues, we propose FinerCut, a new form of fine-grained layer pruning, which in contrast to prior work at the transformer block level, considers all self-attention and feed-forward network (FFN) layers within blocks as individual pruning candidates. FinerCut prunes layers whose removal causes minimal alternation to the model's output -- contributing to a new, lean, interpretable, and task-agnostic pruning method. Tested across 9 benchmarks, our approach retains 90% performance of Llama3-8B with 25% layers removed, and 95% performance of Llama3-70B with 30% layers removed, all without fine-tuning or post-pruning reconstruction. Strikingly, we observe intriguing results with FinerCut: 42% (34 out of 80) of the self-attention layers in Llama3-70B can be removed while preserving 99% of its performance -- without additional fine-tuning after removal. Moreover, FinerCut provides a tool to inspect the types and locations of pruned layers, allowing to observe interesting pruning behaviors. For instance, we observe a preference for pruning self-attention layers, often at deeper consecutive decoder layers. We hope our insights inspire future efficient LLM architecture designs.
The Stronger the Diffusion Model, the Easier the Backdoor: Data Poisoning to Induce Copyright Breaches Without Adjusting Finetuning Pipeline
Jan 07, 2024The commercialization of diffusion models, renowned for their ability to generate high-quality images that are often indistinguishable from real ones, brings forth potential copyright concerns. Although attempts have been made to impede unauthorized access to copyrighted material during training and to subsequently prevent DMs from generating copyrighted images, the effectiveness of these solutions remains unverified. This study explores the vulnerabilities associated with copyright protection in DMs by introducing a backdoor data poisoning attack (SilentBadDiffusion) against text-to-image diffusion models. Our attack method operates without requiring access to or control over the diffusion model's training or fine-tuning processes; it merely involves the insertion of poisoning data into the clean training dataset. This data, comprising poisoning images equipped with prompts, is generated by leveraging the powerful capabilities of multimodal large language models and text-guided image inpainting techniques. Our experimental results and analysis confirm the method's effectiveness. By integrating a minor portion of non-copyright-infringing stealthy poisoning data into the clean dataset-rendering it free from suspicion-we can prompt the finetuned diffusion models to produce copyrighted content when activated by specific trigger prompts. These findings underline potential pitfalls in the prevailing copyright protection strategies and underscore the necessity for increased scrutiny and preventative measures against the misuse of DMs.
Probabilistic Copyright Protection Can Fail for Text-to-Image Generative Models
Nov 29, 2023The booming use of text-to-image generative models has raised concerns about their high risk of producing copyright-infringing content. While probabilistic copyright protection methods provide a probabilistic guarantee against such infringement, in this paper, we introduce Virtually Assured Amplification Attack (VA3), a novel online attack framework that exposes the vulnerabilities of these protection mechanisms. The proposed framework significantly amplifies the probability of generating infringing content on the sustained interactions with generative models and a lower-bounded success probability of each engagement. Our theoretical and experimental results demonstrate the effectiveness of our approach and highlight the potential risk of implementing probabilistic copyright protection in practical applications of text-to-image generative models. Code is available at https://github.com/South7X/VA3.
PICProp: Physics-Informed Confidence Propagation for Uncertainty Quantification
Oct 20, 2023Standard approaches for uncertainty quantification in deep learning and physics-informed learning have persistent limitations. Indicatively, strong assumptions regarding the data likelihood are required, the performance highly depends on the selection of priors, and the posterior can be sampled only approximately, which leads to poor approximations because of the associated computational cost. This paper introduces and studies confidence interval (CI) estimation for deterministic partial differential equations as a novel problem. That is, to propagate confidence, in the form of CIs, from data locations to the entire domain with probabilistic guarantees. We propose a method, termed Physics-Informed Confidence Propagation (PICProp), based on bi-level optimization to compute a valid CI without making heavy assumptions. We provide a theorem regarding the validity of our method, and computational experiments, where the focus is on physics-informed learning.
State-Aware Proximal Pessimistic Algorithms for Offline Reinforcement Learning
Nov 28, 2022Pessimism is of great importance in offline reinforcement learning (RL). One broad category of offline RL algorithms fulfills pessimism by explicit or implicit behavior regularization. However, most of them only consider policy divergence as behavior regularization, ignoring the effect of how the offline state distribution differs with that of the learning policy, which may lead to under-pessimism for some states and over-pessimism for others. Taking account of this problem, we propose a principled algorithmic framework for offline RL, called \emph{State-Aware Proximal Pessimism} (SA-PP). The key idea of SA-PP is leveraging discounted stationary state distribution ratios between the learning policy and the offline dataset to modulate the degree of behavior regularization in a state-wise manner, so that pessimism can be implemented in a more appropriate way. We first provide theoretical justifications on the superiority of SA-PP over previous algorithms, demonstrating that SA-PP produces a lower suboptimality upper bound in a broad range of settings. Furthermore, we propose a new algorithm named \emph{State-Aware Conservative Q-Learning} (SA-CQL), by building SA-PP upon representative CQL algorithm with the help of DualDICE for estimating discounted stationary state distribution ratios. Extensive experiments on standard offline RL benchmark show that SA-CQL outperforms the popular baselines on a large portion of benchmarks and attains the highest average return.