 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning with Smooth Policy
Paper and Code
Mar 24, 2020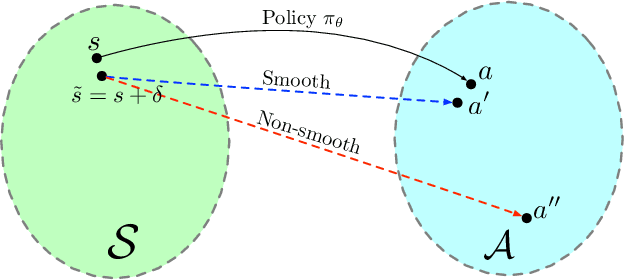

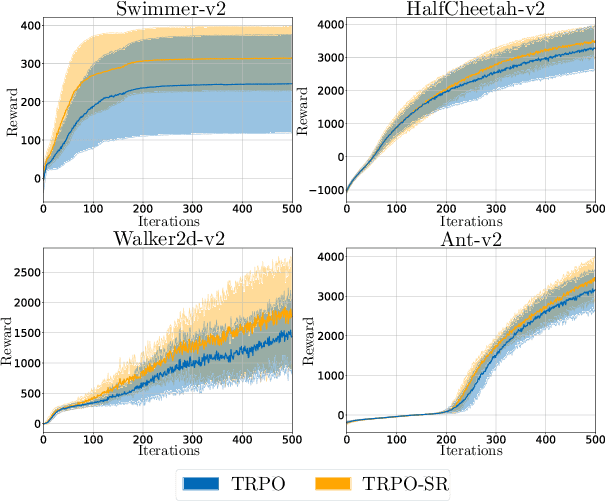
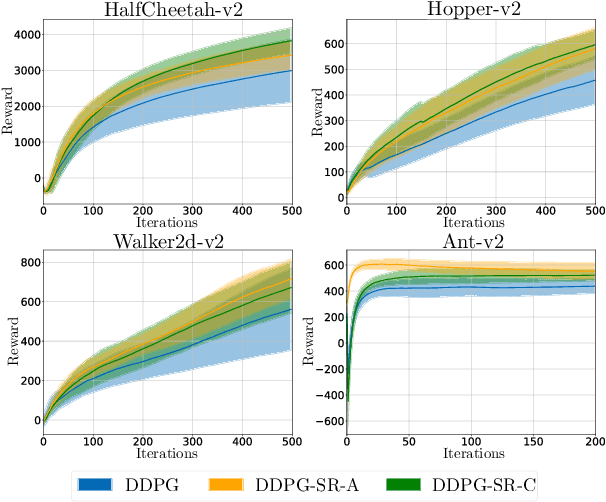
Deep neural networks have been widely adopted in modern reinforcement learning (RL) algorithms with great empirical successes in various domains. However, the large search space of training a neural network requires a significant amount of data, which makes the current RL algorithms not sample efficient. Motivated by the fact that many environments with continuous state space have smooth transitions, we propose to learn a smooth policy that behaves smoothly with respect to states. In contrast to policies parameterized by linear/reproducing kernel functions, where simple regularization techniques suffice to control smoothness, for neural network based reinforcement learning algorithms, there is no readily available solution to learn a smooth policy. In this paper, we develop a new training framework --- $\textbf{S}$mooth $\textbf{R}$egularized $\textbf{R}$einforcement $\textbf{L}$earning ($\textbf{SR}^2\textbf{L}$), where the policy is trained with smoothness-inducing regularization. Such regularization effectively constrains the search space of the learning algorithms and enforces smoothness in the learned policy. We apply the proposed framework to both on-policy (TRPO) and off-policy algorithm (DDPG). Through extensive experiments, we demonstrate that our method achieves improved sample efficiency.