 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Ask a Strong LLM Judge when Your Reward Model is Uncertain
Oct 23, 2025Reward model (RM) plays a pivotal role in reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs). However, classical RMs trained on human preferences are vulnerable to reward hacking and generalize poorly to out-of-distribution (OOD) inputs. By contrast, strong LLM judges equipped with reasoning capabilities demonstrate superior generalization, even without additional training, but incur significantly higher inference costs, limiting their applicability in online RLHF. In this work, we propose an uncertainty-based routing framework that efficiently complements a fast RM with a strong but costly LLM judge. Our approach formulates advantage estimation in policy gradient (PG) methods as pairwise preference classification, enabling principled uncertainty quantification to guide routing. Uncertain pairs are forwarded to the LLM judge, while confident ones are evaluated by the RM. Experiments on RM benchmarks demonstrate that our uncertainty-based routing strategy significantly outperforms random judge calling at the same cost, and downstream alignment results showcase its effectiveness in improving online RLHF.
RRO: LLM Agent Optimization Through Rising Reward Trajectories
May 27, 2025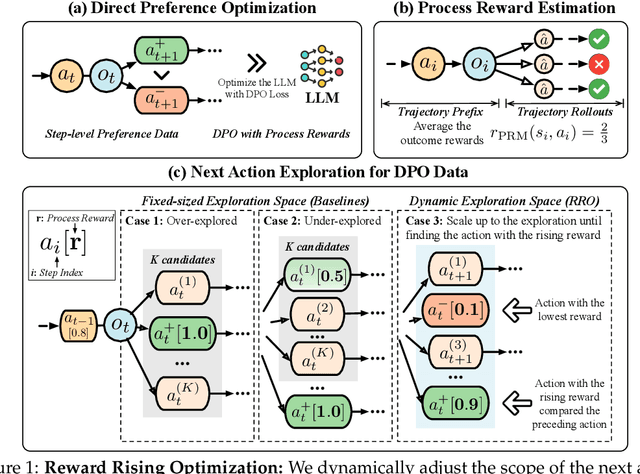
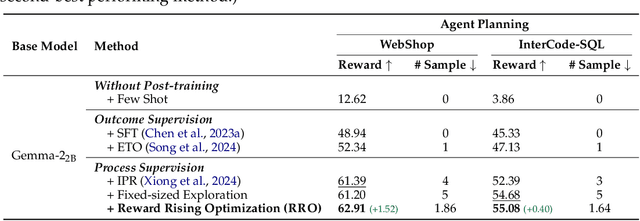
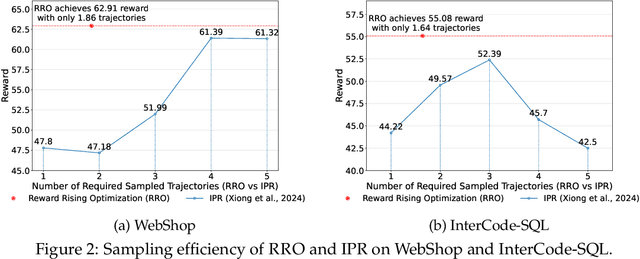

Large language models (LLMs) have exhibited extraordinary performance in a variety of tasks while it remains challenging for them to solve complex multi-step tasks as agents. In practice, agents sensitive to the outcome of certain key steps which makes them likely to fail the task because of a subtle mistake in the planning trajectory. Recent approaches resort to calibrating the reasoning process through reinforcement learning. They reward or penalize every reasoning step with process supervision, as known as Process Reward Models (PRMs). However, PRMs are difficult and costly to scale up with a large number of next action candidates since they require extensive computations to acquire the training data through the per-step trajectory exploration. To mitigate this issue, we focus on the relative reward trend across successive reasoning steps and propose maintaining an increasing reward in the collected trajectories for process supervision, which we term Reward Rising Optimization (RRO). Specifically, we incrementally augment the process supervision until identifying a step exhibiting positive reward differentials, i.e. rising rewards, relative to its preceding iteration. This method dynamically expands the search space for the next action candidates, efficiently capturing high-quality data. We provide mathematical groundings and empirical results on the WebShop and InterCode-SQL benchmarks, showing that our proposed RRO achieves superior performance while requiring much less exploration cost.
Think-RM: Enabling Long-Horizon Reasoning in Generative Reward Models
May 22, 2025Reinforcement learning from human feedback (RLHF) has become a powerful post-training paradigm for aligning large language models with human preferences. A core challenge in RLHF is constructing accurate reward signals, where the conventional Bradley-Terry reward models (BT RMs) often suffer from sensitivity to data size and coverage, as well as vulnerability to reward hacking. Generative reward models (GenRMs) offer a more robust alternative by generating chain-of-thought (CoT) rationales followed by a final reward. However, existing GenRMs rely on shallow, vertically scaled reasoning, limiting their capacity to handle nuanced or complex (e.g., reasoning-intensive) tasks. Moreover, their pairwise preference outputs are incompatible with standard RLHF algorithms that require pointwise reward signals. In this work, we introduce Think-RM, a training framework that enables long-horizon reasoning in GenRMs by modeling an internal thinking process. Rather than producing structured, externally provided rationales, Think-RM generates flexible, self-guided reasoning traces that support advanced capabilities such as self-reflection, hypothetical reasoning, and divergent reasoning. To elicit these reasoning abilities, we first warm-up the models by supervised fine-tuning (SFT) over long CoT data. We then further improve the model's long-horizon abilities by rule-based reinforcement learning (RL). In addition, we propose a novel pairwise RLHF pipeline that directly optimizes policies using pairwise preference rewards, eliminating the need for pointwise reward conversion and enabling more effective use of Think-RM outputs. Experiments show that Think-RM achieves state-of-the-art results on RM-Bench, outperforming both BT RM and vertically scaled GenRM by 8%. When combined with our pairwise RLHF pipeline, it demonstrates superior end-policy performance compared to traditional approaches.
IHEval: Evaluating Language Models on Following the Instruction Hierarchy
Feb 12, 2025The instruction hierarchy, which establishes a priority order from system messages to user messages, conversation history, and tool outputs, is essential for ensuring consistent and safe behavior in language models (LMs). Despite its importance, this topic receives limited attention, and there is a lack of comprehensive benchmarks for evaluating models' ability to follow the instruction hierarchy. We bridge this gap by introducing IHEval, a novel benchmark comprising 3,538 examples across nine tasks, covering cases where instructions in different priorities either align or conflict. Our evaluation of popular LMs highlights their struggle to recognize instruction priorities. All evaluated models experience a sharp performance decline when facing conflicting instructions, compared to their original instruction-following performance. Moreover, the most competitive open-source model only achieves 48% accuracy in resolving such conflicts. Our results underscore the need for targeted optimization in the future development of LMs.
Hephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
Feb 10, 2025



Due to the scarcity of agent-oriented pre-training data, LLM-based autonomous agents typically rely on complex prompting or extensive fine-tuning, which often fails to introduce new capabilities while preserving strong generalizability. We introduce Hephaestus-Forge, the first large-scale pre-training corpus designed to enhance the fundamental capabilities of LLM agents in API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. Hephaestus-Forge comprises 103B agent-specific data encompassing 76,537 APIs, including both tool documentation to introduce knowledge of API functions and function calling trajectories to strengthen intrinsic reasoning. To explore effective training protocols, we investigate scaling laws to identify the optimal recipe in data mixing ratios. By continual pre-training on Hephaestus-Forge, Hephaestus outperforms small- to medium-scale open-source LLMs and rivals commercial LLMs on three agent benchmarks, demonstrating the effectiveness of our pre-training corpus in enhancing fundamental agentic capabilities and generalization of LLMs to new tasks or environments.
Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs
Aug 07, 2024



Reasoning encompasses two typical types: deductive reasoning and inductive reasoning. Despite extensive research into the reasoning capabilities of Large Language Models (LLMs), most studies have failed to rigorously differentiate between inductive and deductive reasoning, leading to a blending of the two. This raises an essential question: In LLM reasoning, which poses a greater challenge - deductive or inductive reasoning? While the deductive reasoning capabilities of LLMs, (i.e. their capacity to follow instructions in reasoning tasks), have received considerable attention, their abilities in true inductive reasoning remain largely unexplored. To investigate into the true inductive reasoning capabilities of LLMs, we propose a novel framework, SolverLearner. This framework enables LLMs to learn the underlying function (i.e., $y = f_w(x)$), that maps input data points $(x)$ to their corresponding output values $(y)$, using only in-context examples. By focusing on inductive reasoning and separating it from LLM-based deductive reasoning, we can isolate and investigate inductive reasoning of LLMs in its pure form via SolverLearner. Our observations reveal that LLMs demonstrate remarkable inductive reasoning capabilities through SolverLearner, achieving near-perfect performance with ACC of 1 in most cases. Surprisingly, despite their strong inductive reasoning abilities, LLMs tend to relatively lack deductive reasoning capabilities, particularly in tasks involving ``counterfactual'' reasoning.
Relational Database Augmented Large Language Model
Jul 21, 2024



Large language models (LLMs) excel in many natural language processing (NLP) tasks. However, since LLMs can only incorporate new knowledge through training or supervised fine-tuning processes, they are unsuitable for applications that demand precise, up-to-date, and private information not available in the training corpora. This precise, up-to-date, and private information is typically stored in relational databases. Thus, a promising solution is to augment LLMs with the inclusion of relational databases as external memory. This can ensure the timeliness, correctness, and consistency of data, and assist LLMs in performing complex arithmetic operations beyond their inherent capabilities. However, bridging the gap between LLMs and relational databases is challenging. It requires the awareness of databases and data values stored in databases to select correct databases and issue correct SQL queries. Besides, it is necessary for the external memory to be independent of the LLM to meet the needs of real-world applications. We introduce a novel LLM-agnostic memory architecture comprising a database selection memory, a data value memory, and relational databases. And we design an elegant pipeline to retrieve information from it. Besides, we carefully design the prompts to instruct the LLM to maximize the framework's potential. To evaluate our method, we compose a new dataset with various types of questions. Experimental results show that our framework enables LLMs to effectively answer database-related questions, which is beyond their direct ability.
Robust Reinforcement Learning from Corrupted Human Feedback
Jun 21, 2024Reinforcement learning from human feedback (RLHF) provides a principled framework for aligning AI systems with human preference data. For various reasons, e.g., personal bias, context ambiguity, lack of training, etc, human annotators may give incorrect or inconsistent preference labels. To tackle this challenge, we propose a robust RLHF approach -- $R^3M$, which models the potentially corrupted preference label as sparse outliers. Accordingly, we formulate the robust reward learning as an $\ell_1$-regularized maximum likelihood estimation problem. Computationally, we develop an efficient alternating optimization algorithm, which only incurs negligible computational overhead compared with the standard RLHF approach. Theoretically, we prove that under proper regularity conditions, $R^3M$ can consistently learn the underlying reward and identify outliers, provided that the number of outlier labels scales sublinearly with the preference sample size. Furthermore, we remark that $R^3M$ is versatile and can be extended to various preference optimization methods, including direct preference optimization (DPO). Our experiments on robotic control and natural language generation with large language models (LLMs) show that $R^3M$ improves robustness of the reward against several types of perturbations to the preference data.
Adaptive Preference Scaling for Reinforcement Learning with Human Feedback
Jun 04, 2024Reinforcement learning from human feedback (RLHF) is a prevalent approach to align AI systems with human values by learning rewards from human preference data. Due to various reasons, however, such data typically takes the form of rankings over pairs of trajectory segments, which fails to capture the varying strengths of preferences across different pairs. In this paper, we propose a novel adaptive preference loss, underpinned by distributionally robust optimization (DRO), designed to address this uncertainty in preference strength. By incorporating an adaptive scaling parameter into the loss for each pair, our method increases the flexibility of the reward function. Specifically, it assigns small scaling parameters to pairs with ambiguous preferences, leading to more comparable rewards, and large scaling parameters to those with clear preferences for more distinct rewards. Computationally, our proposed loss function is strictly convex and univariate with respect to each scaling parameter, enabling its efficient optimization through a simple second-order algorithm. Our method is versatile and can be readily adapted to various preference optimization frameworks, including direct preference optimization (DPO). Our experiments with robotic control and natural language generation with large language models (LLMs) show that our method not only improves policy performance but also aligns reward function selection more closely with policy optimization, simplifying the hyperparameter tuning process.