 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pen to Pixel: Translating Hand-Drawn Plots into Graphical APIs via a Novel Benchmark and Efficient Adapter
Mar 27, 2026As plots play a critical role in modern data visualization and analysis, Plot2API is launched to help non-experts and beginners create their desired plots by directly recommending graphical APIs from reference plot images by neural networks. However, previous works on Plot2API have primarily focused on the recommendation for standard plot images, while overlooking the hand-drawn plot images that are more accessible to non-experts and beginners. To make matters worse, both Plot2API models trained on standard plot images and powerful multi-modal large language models struggle to effectively recommend APIs for hand-drawn plot images due to the domain gap and lack of expertise. To facilitate non-experts and beginners, we introduce a hand-drawn plot dataset named HDpy-13 to improve the performance of graphical API recommendations for hand-drawn plot images. Additionally, to alleviate the considerable strain of parameter growth and computational resource costs arising from multi-domain and multi-language challenges in Plot2API, we propose Plot-Adapter that allows for the training and storage of separate adapters rather than requiring an entire model for each language and domain. In particular, Plot-Adapter incorporates a lightweight CNN block to improve the ability to capture local features and implements projection matrix sharing to reduce the number of fine-tuning parameters further. Experimental results demonstrate both the effectiveness of HDpy-13 and the efficiency of Plot-Adapter.
Approximation of Log-Partition Function in Policy Mirror Descent Induces Implicit Regularization for LLM Post-Training
Feb 05, 2026Policy mirror descent (PMD) provides a principled framework for reinforcement learning (RL) by iteratively solving KL-regularized policy improvement subproblems. While this approach has been adopted in training advanced LLMs such as Kimi K1.5/K2, the ideal closed-form PMD updates require reliable partition function estimation, a significant challenge when working with limited rollouts in the vast action spaces of LLMs. We investigate a practical algorithm, termed PMD-mean, that approximates the log-partition term with the mean reward under the sampling policy and performs regression in log-policy space. Specifically, we characterize the population solution of PMD-mean and demonstrate that it implicitly optimizes mirror descent subproblems with an adaptive mixed KL--$χ^2$ regularizer. This additional $χ^2$ regularization constrains large probability changes, producing more conservative updates when expected rewards are low and enhancing robustness against finite-sample estimation errors. Experiments on math reasoning tasks show that PMD-mean achieves superior performance with improved stability and time efficiency. These findings deepen our understanding of PMD-mean and illuminate pathways toward principled improvements in RL algorithms for LLMs. Code is available at https://github.com/horizon-rl/OpenKimi.
Ask a Strong LLM Judge when Your Reward Model is Uncertain
Oct 23, 2025Reward model (RM) plays a pivotal role in reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs). However, classical RMs trained on human preferences are vulnerable to reward hacking and generalize poorly to out-of-distribution (OOD) inputs. By contrast, strong LLM judges equipped with reasoning capabilities demonstrate superior generalization, even without additional training, but incur significantly higher inference costs, limiting their applicability in online RLHF. In this work, we propose an uncertainty-based routing framework that efficiently complements a fast RM with a strong but costly LLM judge. Our approach formulates advantage estimation in policy gradient (PG) methods as pairwise preference classification, enabling principled uncertainty quantification to guide routing. Uncertain pairs are forwarded to the LLM judge, while confident ones are evaluated by the RM. Experiments on RM benchmarks demonstrate that our uncertainty-based routing strategy significantly outperforms random judge calling at the same cost, and downstream alignment results showcase its effectiveness in improving online RLHF.
Think-RM: Enabling Long-Horizon Reasoning in Generative Reward Models
May 22, 2025Reinforcement learning from human feedback (RLHF) has become a powerful post-training paradigm for aligning large language models with human preferences. A core challenge in RLHF is constructing accurate reward signals, where the conventional Bradley-Terry reward models (BT RMs) often suffer from sensitivity to data size and coverage, as well as vulnerability to reward hacking. Generative reward models (GenRMs) offer a more robust alternative by generating chain-of-thought (CoT) rationales followed by a final reward. However, existing GenRMs rely on shallow, vertically scaled reasoning, limiting their capacity to handle nuanced or complex (e.g., reasoning-intensive) tasks. Moreover, their pairwise preference outputs are incompatible with standard RLHF algorithms that require pointwise reward signals. In this work, we introduce Think-RM, a training framework that enables long-horizon reasoning in GenRMs by modeling an internal thinking process. Rather than producing structured, externally provided rationales, Think-RM generates flexible, self-guided reasoning traces that support advanced capabilities such as self-reflection, hypothetical reasoning, and divergent reasoning. To elicit these reasoning abilities, we first warm-up the models by supervised fine-tuning (SFT) over long CoT data. We then further improve the model's long-horizon abilities by rule-based reinforcement learning (RL). In addition, we propose a novel pairwise RLHF pipeline that directly optimizes policies using pairwise preference rewards, eliminating the need for pointwise reward conversion and enabling more effective use of Think-RM outputs. Experiments show that Think-RM achieves state-of-the-art results on RM-Bench, outperforming both BT RM and vertically scaled GenRM by 8%. When combined with our pairwise RLHF pipeline, it demonstrates superior end-policy performance compared to traditional approaches.
COSMOS: A Hybrid Adaptive Optimizer for Memory-Efficient Training of LLMs
Feb 26, 2025Large Language Models (LLMs) have demonstrated remarkable success across various domains, yet their optimization remains a significant challenge due to the complex and high-dimensional loss landscapes they inhabit. While adaptive optimizers such as AdamW are widely used, they suffer from critical limitations, including an inability to capture interdependencies between coordinates and high memory consumption. Subsequent research, exemplified by SOAP, attempts to better capture coordinate interdependence but incurs greater memory overhead, limiting scalability for massive LLMs. An alternative approach aims to reduce memory consumption through low-dimensional projection, but this leads to substantial approximation errors, resulting in less effective optimization (e.g., in terms of per-token efficiency). In this paper, we propose COSMOS, a novel hybrid optimizer that leverages the varying importance of eigensubspaces in the gradient matrix to achieve memory efficiency without compromising optimization performance. The design of COSMOS is motivated by our empirical insights and practical considerations. Specifically, COSMOS applies SOAP to the leading eigensubspace, which captures the primary optimization dynamics, and MUON to the remaining eigensubspace, which is less critical but computationally expensive to handle with SOAP. This hybrid strategy significantly reduces memory consumption while maintaining robust optimization performance, making it particularly suitable for massive LLMs. Numerical experiments on various datasets and transformer architectures are provided to demonstrate the effectiveness of COSMOS. Our code is available at https://github.com/lliu606/COSMOS.
Provable Acceleration of Nesterov's Accelerated Gradient for Rectangular Matrix Factorization and Linear Neural Networks
Oct 12, 2024



We study the convergence rate of first-order methods for rectangular matrix factorization, which is a canonical nonconvex optimization problem. Specifically, given a rank-$r$ matrix $\mathbf{A}\in\mathbb{R}^{m\times n}$, we prove that gradient descent (GD) can find a pair of $\epsilon$-optimal solutions $\mathbf{X}_T\in\mathbb{R}^{m\times d}$ and $\mathbf{Y}_T\in\mathbb{R}^{n\times d}$, where $d\geq r$, satisfying $\lVert\mathbf{X}_T\mathbf{Y}_T^\top-\mathbf{A}\rVert_\mathrm{F}\leq\epsilon\lVert\mathbf{A}\rVert_\mathrm{F}$ in $T=O(\kappa^2\log\frac{1}{\epsilon})$ iterations with high probability, where $\kappa$ denotes the condition number of $\mathbf{A}$. Furthermore, we prove that Nesterov's accelerated gradient (NAG) attains an iteration complexity of $O(\kappa\log\frac{1}{\epsilon})$, which is the best-known bound of first-order methods for rectangular matrix factorization. Different from small balanced random initialization in the existing literature, we adopt an unbalanced initialization, where $\mathbf{X}_0$ is large and $\mathbf{Y}_0$ is $0$. Moreover, our initialization and analysis can be further extended to linear neural networks, where we prove that NAG can also attain an accelerated linear convergence rate. In particular, we only require the width of the network to be greater than or equal to the rank of the output label matrix. In contrast, previous results achieving the same rate require excessive widths that additionally depend on the condition number and the rank of the input data matrix.
Good regularity creates large learning rate implicit biases: edge of stability, balancing, and catapult
Oct 26, 2023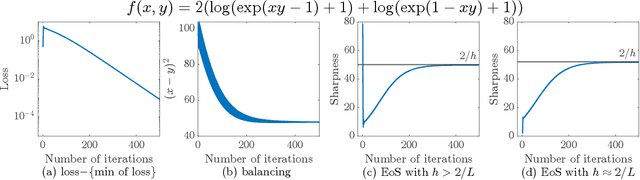

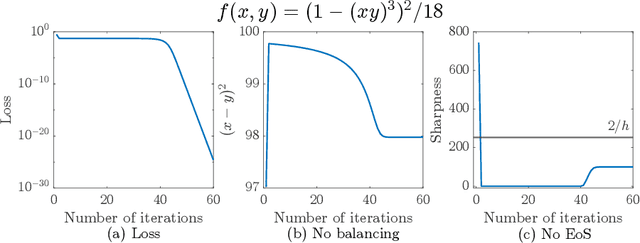
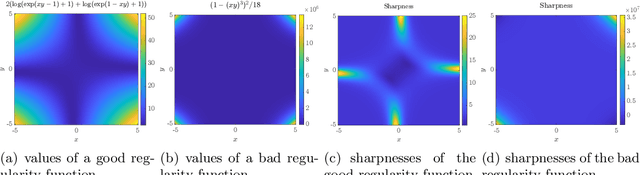
Large learning rates, when applied to gradient descent for nonconvex optimization, yield various implicit biases including the edge of stability (Cohen et al., 2021), balancing (Wang et al., 2022), and catapult (Lewkowycz et al., 2020). These phenomena cannot be well explained by classical optimization theory. Though significant theoretical progress has been made in understanding these implicit biases, it remains unclear for which objective functions would they occur. This paper provides an initial step in answering this question, namely that these implicit biases are in fact various tips of the same iceberg. They occur when the objective function of optimization has some good regularity, which, in combination with a provable preference of large learning rate gradient descent for moving toward flatter regions, results in these nontrivial dynamical phenomena. To establish this result, we develop a new global convergence theory under large learning rates, for a family of nonconvex functions without globally Lipschitz continuous gradient, which was typically assumed in existing convergence analysis. A byproduct is the first non-asymptotic convergence rate bound for large-learning-rate gradient descent optimization of nonconvex functions. We also validate our theory with experiments on neural networks, where different losses, activation functions, and batch normalization all can significantly affect regularity and lead to very different training dynamics.
Score Matching-based Pseudolikelihood Estimation of Neural Marked Spatio-Temporal Point Process with Uncertainty Quantification
Oct 25, 2023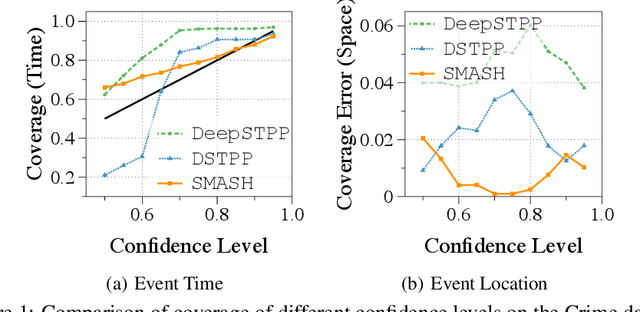
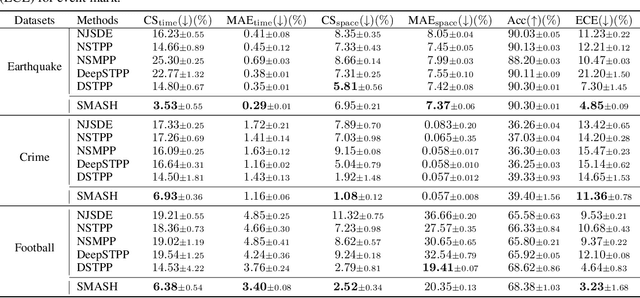
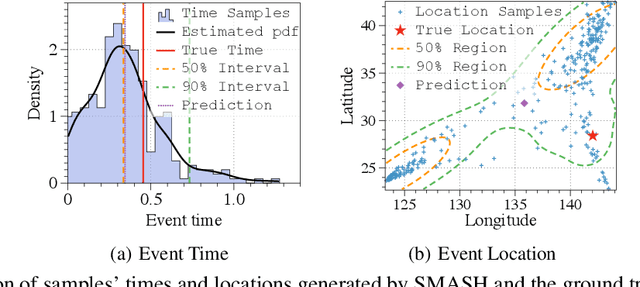
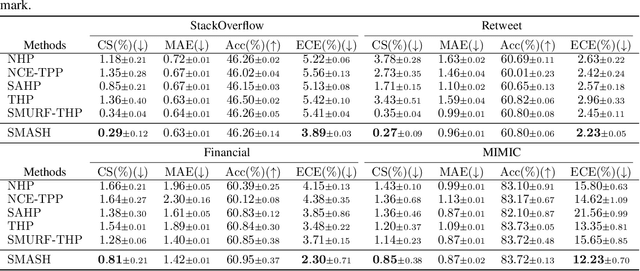
Spatio-temporal point processes (STPPs) are potent mathematical tools for modeling and predicting events with both temporal and spatial features. Despite their versatility, most existing methods for learning STPPs either assume a restricted form of the spatio-temporal distribution, or suffer from inaccurate approximations of the intractable integral in the likelihood training objective. These issues typically arise from the normalization term of the probability density function. Moreover, current techniques fail to provide uncertainty quantification for model predictions, such as confidence intervals for the predicted event's arrival time and confidence regions for the event's location, which is crucial given the considerable randomness of the data. To tackle these challenges, we introduce SMASH: a Score MAtching-based pSeudolikeliHood estimator for learning marked STPPs with uncertainty quantification. Specifically, our framework adopts a normalization-free objective by estimating the pseudolikelihood of marked STPPs through score-matching and offers uncertainty quantification for the predicted event time, location and mark by computing confidence regions over the generated samples. The superior performance of our proposed framework is demonstrated through extensive experiments in both event prediction and uncertainty quantification.
Sample Complexity of Neural Policy Mirror Descent for Policy Optimization on Low-Dimensional Manifolds
Sep 25, 2023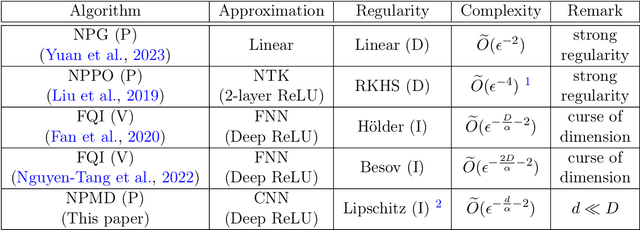
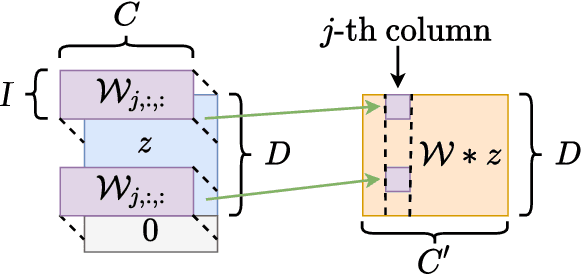
Policy-based algorithms equipped with deep neural networks have achieved great success in solving high-dimensional policy optimization problems in reinforcement learning. However, current analyses cannot explain why they are resistant to the curse of dimensionality. In this work, we study the sample complexity of the neural policy mirror descent (NPMD) algorithm with convolutional neural networks (CNN) as function approximators. Motivated by the empirical observation that many high-dimensional environments have state spaces possessing low-dimensional structures, such as those taking images as states, we consider the state space to be a $d$-dimensional manifold embedded in the $D$-dimensional Euclidean space with intrinsic dimension $d\ll D$. We show that in each iteration of NPMD, both the value function and the policy can be well approximated by CNNs. The approximation errors are controlled by the size of the networks, and the smoothness of the previous networks can be inherited. As a result, by properly choosing the network size and hyperparameters, NPMD can find an $\epsilon$-optimal policy with $\widetilde{O}(\epsilon^{-\frac{d}{\alpha}-2})$ samples in expectation, where $\alpha\in(0,1]$ indicates the smoothness of environment. Compared to previous work, our result exhibits that NPMD can leverage the low-dimensional structure of state space to escape from the curse of dimensionality, providing an explanation for the efficacy of deep policy-based algorithms.