 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Proof
Feb 05, 2026To assess the ability of current AI systems to correctly answer research-level mathematics questions, we share a set of ten math questions which have arisen naturally in the research process of the authors. The questions had not been shared publicly until now; the answers are known to the authors of the questions but will remain encrypted for a short time.
Phi-4 Technical Report
Dec 12, 2024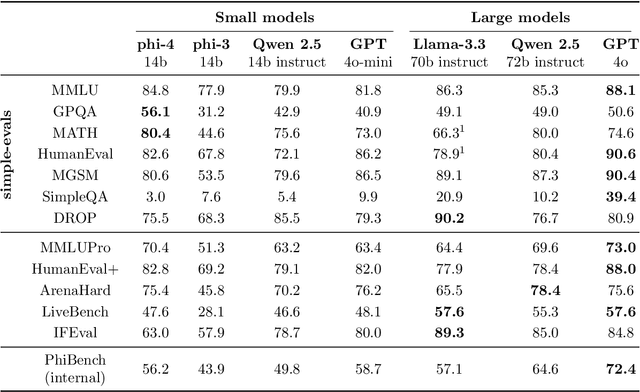
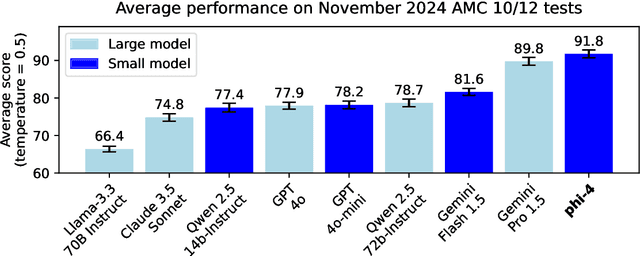

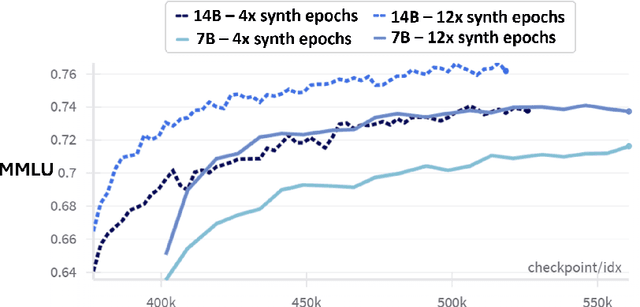
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
Provable Acceleration of Nesterov's Accelerated Gradient for Rectangular Matrix Factorization and Linear Neural Networks
Oct 12, 2024



We study the convergence rate of first-order methods for rectangular matrix factorization, which is a canonical nonconvex optimization problem. Specifically, given a rank-$r$ matrix $\mathbf{A}\in\mathbb{R}^{m\times n}$, we prove that gradient descent (GD) can find a pair of $\epsilon$-optimal solutions $\mathbf{X}_T\in\mathbb{R}^{m\times d}$ and $\mathbf{Y}_T\in\mathbb{R}^{n\times d}$, where $d\geq r$, satisfying $\lVert\mathbf{X}_T\mathbf{Y}_T^\top-\mathbf{A}\rVert_\mathrm{F}\leq\epsilon\lVert\mathbf{A}\rVert_\mathrm{F}$ in $T=O(\kappa^2\log\frac{1}{\epsilon})$ iterations with high probability, where $\kappa$ denotes the condition number of $\mathbf{A}$. Furthermore, we prove that Nesterov's accelerated gradient (NAG) attains an iteration complexity of $O(\kappa\log\frac{1}{\epsilon})$, which is the best-known bound of first-order methods for rectangular matrix factorization. Different from small balanced random initialization in the existing literature, we adopt an unbalanced initialization, where $\mathbf{X}_0$ is large and $\mathbf{Y}_0$ is $0$. Moreover, our initialization and analysis can be further extended to linear neural networks, where we prove that NAG can also attain an accelerated linear convergence rate. In particular, we only require the width of the network to be greater than or equal to the rank of the output label matrix. In contrast, previous results achieving the same rate require excessive widths that additionally depend on the condition number and the rank of the input data matrix.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
TinyGSM: achieving >80% on GSM8k with small language models
Dec 14, 2023



Small-scale models offer various computational advantages, and yet to which extent size is critical for problem-solving abilities remains an open question. Specifically for solving grade school math, the smallest model size so far required to break the 80\% barrier on the GSM8K benchmark remains to be 34B. Our work studies how high-quality datasets may be the key for small language models to acquire mathematical reasoning. We introduce \texttt{TinyGSM}, a synthetic dataset of 12.3M grade school math problems paired with Python solutions, generated fully by GPT-3.5. After finetuning on \texttt{TinyGSM}, we find that a duo of a 1.3B generation model and a 1.3B verifier model can achieve 81.5\% accuracy, outperforming existing models that are orders of magnitude larger. This also rivals the performance of the GPT-3.5 ``teacher'' model (77.4\%), from which our model's training data is generated. Our approach is simple and has two key components: 1) the high-quality dataset \texttt{TinyGSM}, 2) the use of a verifier, which selects the final outputs from multiple candidate generations.
Cluster-aware Semi-supervised Learning: Relational Knowledge Distillation Provably Learns Clustering
Jul 20, 2023


Despite the empirical success and practical significance of (relational) knowledge distillation that matches (the relations of) features between teacher and student models, the corresponding theoretical interpretations remain limited for various knowledge distillation paradigms. In this work, we take an initial step toward a theoretical understanding of relational knowledge distillation (RKD), with a focus on semi-supervised classification problems. We start by casting RKD as spectral clustering on a population-induced graph unveiled by a teacher model. Via a notion of clustering error that quantifies the discrepancy between the predicted and ground truth clusterings, we illustrate that RKD over the population provably leads to low clustering error. Moreover, we provide a sample complexity bound for RKD with limited unlabeled samples. For semi-supervised learning, we further demonstrate the label efficiency of RKD through a general framework of cluster-aware semi-supervised learning that assumes low clustering errors. Finally, by unifying data augmentation consistency regularization into this cluster-aware framework, we show that despite the common effect of learning accurate clusterings, RKD facilitates a "global" perspective through spectral clustering, whereas consistency regularization focuses on a "local" perspective via expansion.
Convergence of Alternating Gradient Descent for Matrix Factorization
May 11, 2023


We consider alternating gradient descent (AGD) with fixed step size $\eta > 0$, applied to the asymmetric matrix factorization objective. We show that, for a rank-$r$ matrix $\mathbf{A} \in \mathbb{R}^{m \times n}$, $T = \left( \left(\frac{\sigma_1(\mathbf{A})}{\sigma_r(\mathbf{A})}\right)^2 \log(1/\epsilon)\right)$ iterations of alternating gradient descent suffice to reach an $\epsilon$-optimal factorization $\| \mathbf{A} - \mathbf{X}_T^{\vphantom{\intercal}} \mathbf{Y}_T^{\intercal} \|_{\rm F}^2 \leq \epsilon \| \mathbf{A} \|_{\rm F}^2$ with high probability starting from an atypical random initialization. The factors have rank $d>r$ so that $\mathbf{X}_T\in\mathbb{R}^{m \times d}$ and $\mathbf{Y}_T \in\mathbb{R}^{n \times d}$. Experiments suggest that our proposed initialization is not merely of theoretical benefit, but rather significantly improves convergence of gradient descent in practice. Our proof is conceptually simple: a uniform PL-inequality and uniform Lipschitz smoothness constant are guaranteed for a sufficient number of iterations, starting from our random initialization. Our proof method should be useful for extending and simplifying convergence analyses for a broader class of nonconvex low-rank factorization problems.
Robust Implicit Regularization via Weight Normalization
May 09, 2023



Overparameterized models may have many interpolating solutions; implicit regularization refers to the hidden preference of a particular optimization method towards a certain interpolating solution among the many. A by now established line of work has shown that (stochastic) gradient descent tends to have an implicit bias towards low rank and/or sparse solutions when used to train deep linear networks, explaining to some extent why overparameterized neural network models trained by gradient descent tend to have good generalization performance in practice. However, existing theory for square-loss objectives often requires very small initialization of the trainable weights, which is at odds with the larger scale at which weights are initialized in practice for faster convergence and better generalization performance. In this paper, we aim to close this gap by incorporating and analyzing gradient descent with weight normalization, where the weight vector is reparamterized in terms of polar coordinates, and gradient descent is applied to the polar coordinates. By analyzing key invariants of the gradient flow and using Lojasiewicz's Theorem, we show that weight normalization also has an implicit bias towards sparse solutions in the diagonal linear model, but that in contrast to plain gradient descent, weight normalization enables a robust bias that persists even if the weights are initialized at practically large scale. Experiments suggest that the gains in both convergence speed and robustness of the implicit bias are improved dramatically by using weight normalization in overparameterized diagonal linear network models.
AdaWAC: Adaptively Weighted Augmentation Consistency Regularization for Volumetric Medical Image Segmentation
Oct 04, 2022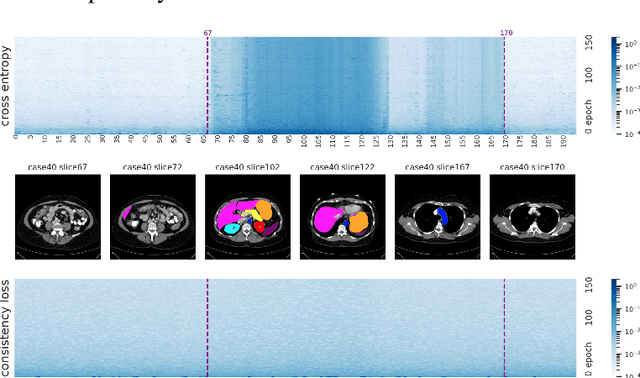
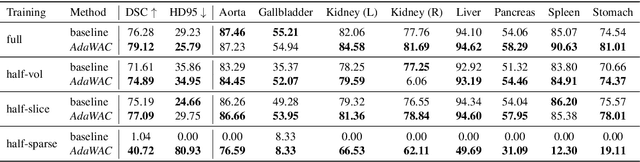
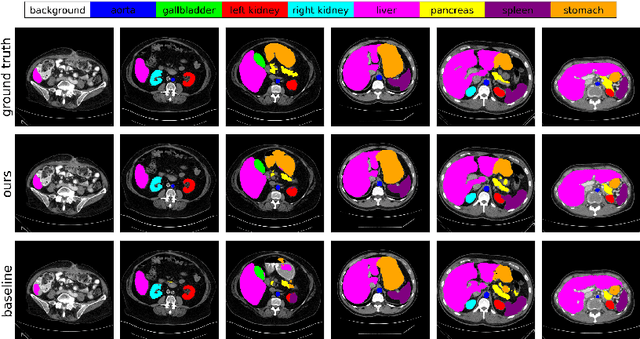
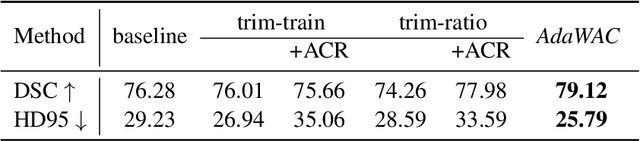
Sample reweighting is an effective strategy for learning from training data coming from a mixture of subpopulations. In volumetric medical image segmentation, the data inputs are similarly distributed, but the associated data labels fall into two subpopulations -- "label-sparse" and "label-dense" -- depending on whether the data image occurs near the beginning/end of the volumetric scan or the middle. Existing reweighting algorithms have focused on hard- and soft- thresholding of the label-sparse data, which results in loss of information and reduced sample efficiency by discarding valuable data input. For this setting, we propose AdaWAC as an adaptive weighting algorithm that introduces a set of trainable weights which, at the saddle point of the underlying objective, assigns label-dense samples to supervised cross-entropy loss and label-sparse samples to unsupervised consistency regularization. We provide a convergence guarantee for AdaWAC by recasting the optimization as online mirror descent on a saddle point problem. Moreover, we empirically demonstrate that AdaWAC not only enhances segmentation performance and sample efficiency but also improves robustness to the subpopulation shift in labels.
On the fast convergence of minibatch heavy ball momentum
Jun 15, 2022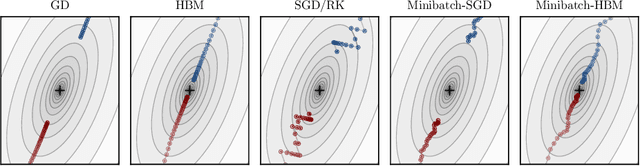
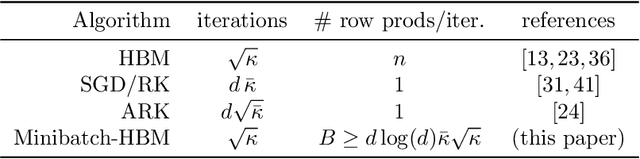
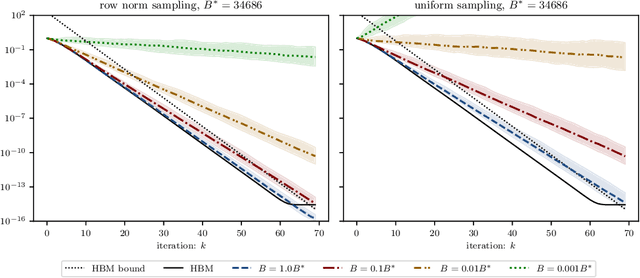
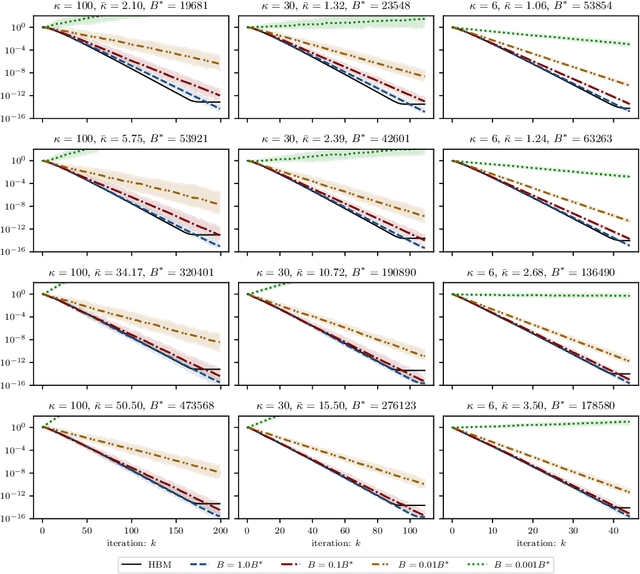
Simple stochastic momentum methods are widely used in machine learning optimization, but their good practical performance is at odds with an absence of theoretical guarantees of acceleration in the literature. In this work, we aim to close the gap between theory and practice by showing that stochastic heavy ball momentum, which can be interpreted as a randomized Kaczmarz algorithm with momentum, retains the fast linear rate of (deterministic) heavy ball momentum on quadratic optimization problems, at least when minibatching with a sufficiently large batch size is used. The analysis relies on carefully decomposing the momentum transition matrix, and using new spectral norm concentration bounds for products of independent random matrices. We provide numerical experiments to demonstrate that our bounds are reasonably sharp.