 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAllure of Craquelure: A Variational-Generative Approach to Crack Detection in Paintings
Feb 10, 2026Recent advances in imaging technologies, deep learning and numerical performance have enabled non-invasive detailed analysis of artworks, supporting their documentation and conservation. In particular, automated detection of craquelure in digitized paintings is crucial for assessing degradation and guiding restoration, yet remains challenging due to the possibly complex scenery and the visual similarity between cracks and crack-like artistic features such as brush strokes or hair. We propose a hybrid approach that models crack detection as an inverse problem, decomposing an observed image into a crack-free painting and a crack component. A deep generative model is employed as powerful prior for the underlying artwork, while crack structures are captured using a Mumford--Shah-type variational functional together with a crack prior. Joint optimization yields a pixel-level map of crack localizations in the painting.
PurSAMERE: Reliable Adversarial Purification via Sharpness-Aware Minimization of Expected Reconstruction Error
Feb 06, 2026We propose a novel deterministic purification method to improve adversarial robustness by mapping a potentially adversarial sample toward a nearby sample that lies close to a mode of the data distribution, where classifiers are more reliable. We design the method to be deterministic to ensure reliable test accuracy and to prevent the degradation of effective robustness observed in stochastic purification approaches when the adversary has full knowledge of the system and its randomness. We employ a score model trained by minimizing the expected reconstruction error of noise-corrupted data, thereby learning the structural characteristics of the input data distribution. Given a potentially adversarial input, the method searches within its local neighborhood for a purified sample that minimizes the expected reconstruction error under noise corruption and then feeds this purified sample to the classifier. During purification, sharpness-aware minimization is used to guide the purified samples toward flat regions of the expected reconstruction error landscape, thereby enhancing robustness. We further show that, as the noise level decreases, minimizing the expected reconstruction error biases the purified sample toward local maximizers of the Gaussian-smoothed density; under additional local assumptions on the score model, we prove recovery of a local maximizer in the small-noise limit. Experimental results demonstrate significant gains in adversarial robustness over state-of-the-art methods under strong deterministic white-box attacks.
Convergence of gradient flow for learning convolutional neural networks
Jan 13, 2026Convolutional neural networks are widely used in imaging and image recognition. Learning such networks from training data leads to the minimization of a non-convex function. This makes the analysis of standard optimization methods such as variants of (stochastic) gradient descent challenging. In this article we study the simplified setting of linear convolutional networks. We show that the gradient flow (to be interpreted as an abstraction of gradient descent) applied to the empirical risk defined via certain loss functions including the square loss always converges to a critical point, under a mild condition on the training data.
The Riemannian Geometry associated to Gradient Flows of Linear Convolutional Networks
Jul 08, 2025
We study geometric properties of the gradient flow for learning deep linear convolutional networks. For linear fully connected networks, it has been shown recently that the corresponding gradient flow on parameter space can be written as a Riemannian gradient flow on function space (i.e., on the product of weight matrices) if the initialization satisfies a so-called balancedness condition. We establish that the gradient flow on parameter space for learning linear convolutional networks can be written as a Riemannian gradient flow on function space regardless of the initialization. This result holds for $D$-dimensional convolutions with $D \geq 2$, and for $D =1$ it holds if all so-called strides of the convolutions are greater than one. The corresponding Riemannian metric depends on the initialization.
High-Dimensional Confidence Regions in Sparse MRI
Jul 18, 2024
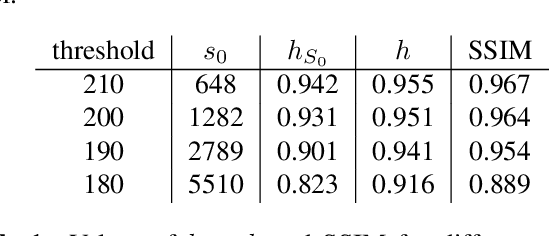
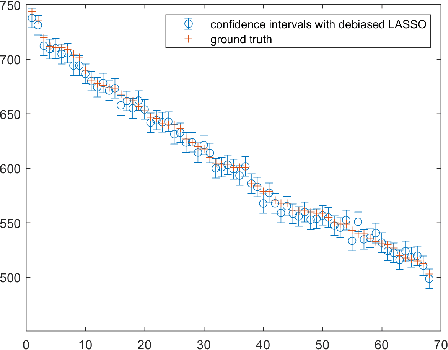
One of the most promising solutions for uncertainty quantification in high-dimensional statistics is the debiased LASSO that relies on unconstrained $\ell_1$-minimization. The initial works focused on real Gaussian designs as a toy model for this problem. However, in medical imaging applications, such as compressive sensing for MRI, the measurement system is represented by a (subsampled) complex Fourier matrix. The purpose of this work is to extend the method to the MRI case in order to construct confidence intervals for each pixel of an MR image. We show that a sufficient amount of data is $n \gtrsim \max\{ s_0\log^2 s_0\log p, s_0 \log^2 p \}$.
Non-Asymptotic Uncertainty Quantification in High-Dimensional Learning
Jul 18, 2024
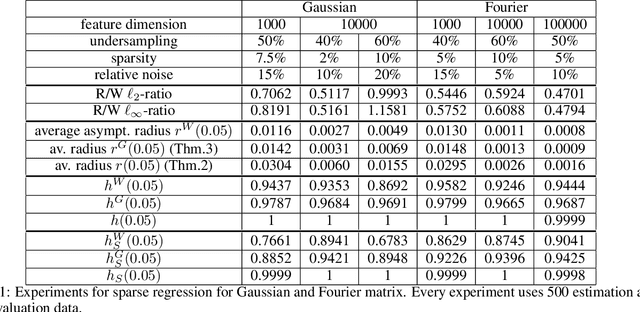

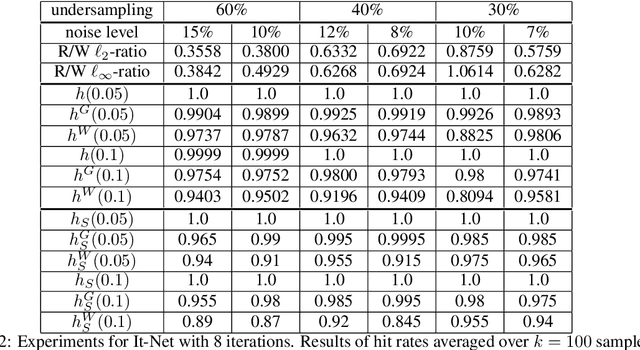
Uncertainty quantification (UQ) is a crucial but challenging task in many high-dimensional regression or learning problems to increase the confidence of a given predictor. We develop a new data-driven approach for UQ in regression that applies both to classical regression approaches such as the LASSO as well as to neural networks. One of the most notable UQ techniques is the debiased LASSO, which modifies the LASSO to allow for the construction of asymptotic confidence intervals by decomposing the estimation error into a Gaussian and an asymptotically vanishing bias component. However, in real-world problems with finite-dimensional data, the bias term is often too significant to be neglected, resulting in overly narrow confidence intervals. Our work rigorously addresses this issue and derives a data-driven adjustment that corrects the confidence intervals for a large class of predictors by estimating the means and variances of the bias terms from training data, exploiting high-dimensional concentration phenomena. This gives rise to non-asymptotic confidence intervals, which can help avoid overestimating uncertainty in critical applications such as MRI diagnosis. Importantly, our analysis extends beyond sparse regression to data-driven predictors like neural networks, enhancing the reliability of model-based deep learning. Our findings bridge the gap between established theory and the practical applicability of such debiased methods.
With or Without Replacement? Improving Confidence in Fourier Imaging
Jul 18, 2024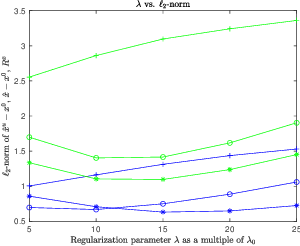
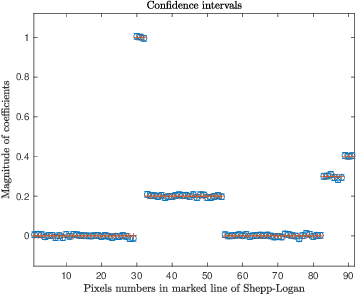
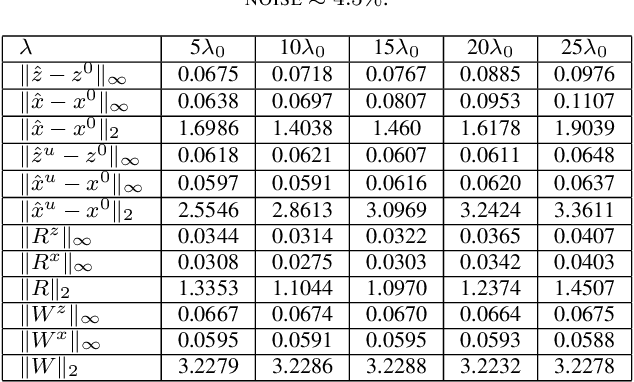
Over the last few years, debiased estimators have been proposed in order to establish rigorous confidence intervals for high-dimensional problems in machine learning and data science. The core argument is that the error of these estimators with respect to the ground truth can be expressed as a Gaussian variable plus a remainder term that vanishes as long as the dimension of the problem is sufficiently high. Thus, uncertainty quantification (UQ) can be performed exploiting the Gaussian model. Empirically, however, the remainder term cannot be neglected in many realistic situations of moderately-sized dimensions, in particular in certain structured measurement scenarios such as Magnetic Resonance Imaging (MRI). This, in turn, can downgrade the advantage of the UQ methods as compared to non-UQ approaches such as the standard LASSO. In this paper, we present a method to improve the debiased estimator by sampling without replacement. Our approach leverages recent results of ours on the structure of the random nature of certain sampling schemes showing how a transition between sampling with and without replacement can lead to a weighted reconstruction scheme with improved performance for the standard LASSO. In this paper, we illustrate how this reweighted sampling idea can also improve the debiased estimator and, consequently, provide a better method for UQ in Fourier imaging.
Uncertainty quantification for learned ISTA
Sep 14, 2023


Model-based deep learning solutions to inverse problems have attracted increasing attention in recent years as they bridge state-of-the-art numerical performance with interpretability. In addition, the incorporated prior domain knowledge can make the training more efficient as the smaller number of parameters allows the training step to be executed with smaller datasets. Algorithm unrolling schemes stand out among these model-based learning techniques. Despite their rapid advancement and their close connection to traditional high-dimensional statistical methods, they lack certainty estimates and a theory for uncertainty quantification is still elusive. This work provides a step towards closing this gap proposing a rigorous way to obtain confidence intervals for the LISTA estimator.
Don't be so Monotone: Relaxing Stochastic Line Search in Over-Parameterized Models
Jun 22, 2023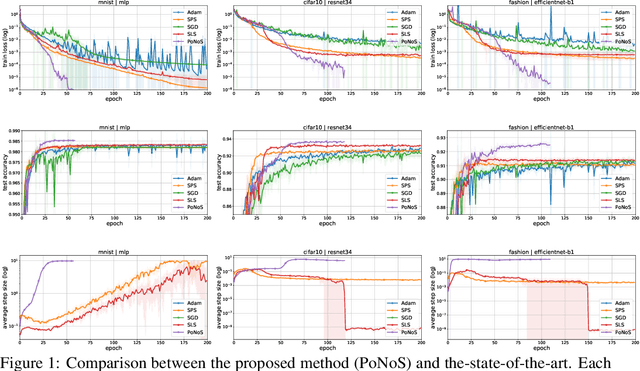
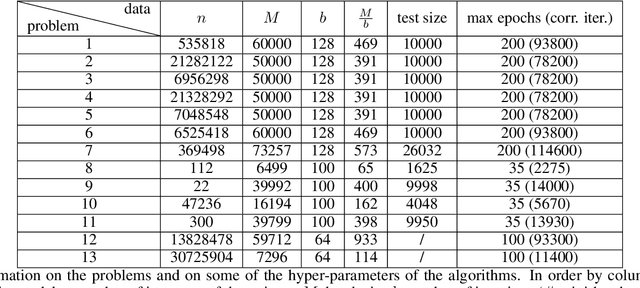
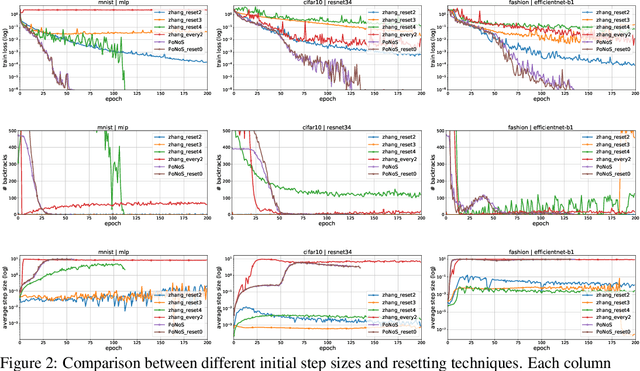

Recent works have shown that line search methods can speed up Stochastic Gradient Descent (SGD) and Adam in modern over-parameterized settings. However, existing line searches may take steps that are smaller than necessary since they require a monotone decrease of the (mini-)batch objective function. We explore nonmonotone line search methods to relax this condition and possibly accept larger step sizes. Despite the lack of a monotonic decrease, we prove the same fast rates of convergence as in the monotone case. Our experiments show that nonmonotone methods improve the speed of convergence and generalization properties of SGD/Adam even beyond the previous monotone line searches. We propose a POlyak NOnmonotone Stochastic (PoNoS) method, obtained by combining a nonmonotone line search with a Polyak initial step size. Furthermore, we develop a new resetting technique that in the majority of the iterations reduces the amount of backtracks to zero while still maintaining a large initial step size. To the best of our knowledge, a first runtime comparison shows that the epoch-wise advantage of line-search-based methods gets reflected in the overall computational time.
Robust Implicit Regularization via Weight Normalization
May 09, 2023



Overparameterized models may have many interpolating solutions; implicit regularization refers to the hidden preference of a particular optimization method towards a certain interpolating solution among the many. A by now established line of work has shown that (stochastic) gradient descent tends to have an implicit bias towards low rank and/or sparse solutions when used to train deep linear networks, explaining to some extent why overparameterized neural network models trained by gradient descent tend to have good generalization performance in practice. However, existing theory for square-loss objectives often requires very small initialization of the trainable weights, which is at odds with the larger scale at which weights are initialized in practice for faster convergence and better generalization performance. In this paper, we aim to close this gap by incorporating and analyzing gradient descent with weight normalization, where the weight vector is reparamterized in terms of polar coordinates, and gradient descent is applied to the polar coordinates. By analyzing key invariants of the gradient flow and using Lojasiewicz's Theorem, we show that weight normalization also has an implicit bias towards sparse solutions in the diagonal linear model, but that in contrast to plain gradient descent, weight normalization enables a robust bias that persists even if the weights are initialized at practically large scale. Experiments suggest that the gains in both convergence speed and robustness of the implicit bias are improved dramatically by using weight normalization in overparameterized diagonal linear network models.