 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatland: The Adventures of Gradient Descent with Large Step Sizes
Jun 04, 2026The training of neural networks often entails objective functions that are not globally $L$-smooth. For these functions, it is both theoretically and practically difficult to reply to the question: what is the largest possible step size that ensures the convergence of gradient descent (GD)? We address this longstanding open question in deep learning by providing a unifying definition of "large" step sizes that requires only local Lipschitz (or even Hölder) continuity of the gradient. We design first-order adaptive methods that provably yield large step sizes and show that they operate at the edge of stability (EoS) right from the start of the training. In particular, the loss decreases nonmonotonically and the product between the step size and sharpness, i.e., the largest eigenvalue of the Hessian, stays above the EoS threshold of 2 throughout training. Using our method, we are also able to minimize the sharpness all the way down to its global minimum. Contrary to expectation, we find that encountering globally-flat regions too early in the training may both slow down convergence and jeopardize the generalization ability of the network. Exploiting a self-stabilization argument, we allow GD to enter slightly sharper valleys and turn unsuccessful training runs into very successful ones.
Faster Convergence for Transformer Fine-tuning with Line Search Methods
Mar 27, 2024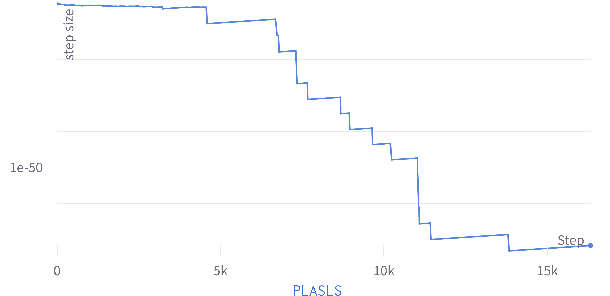
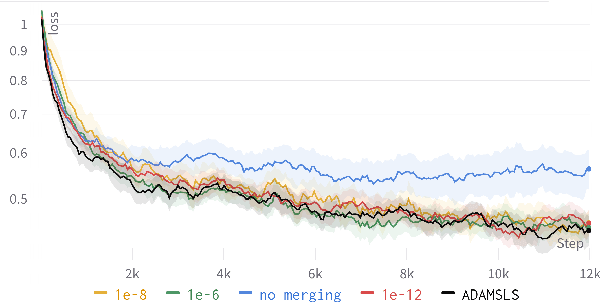
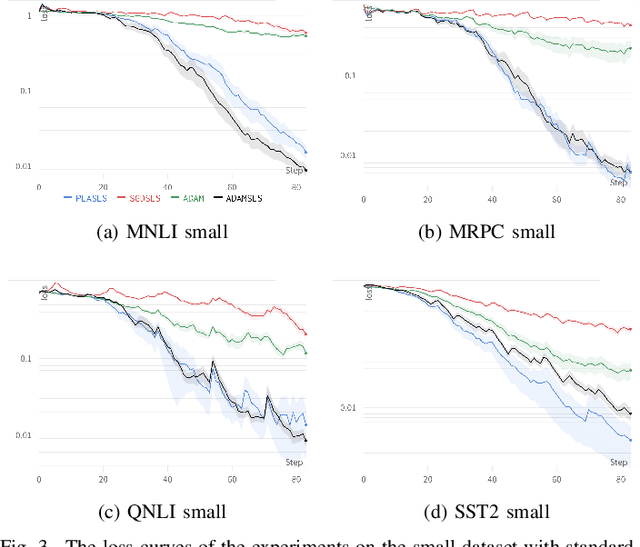
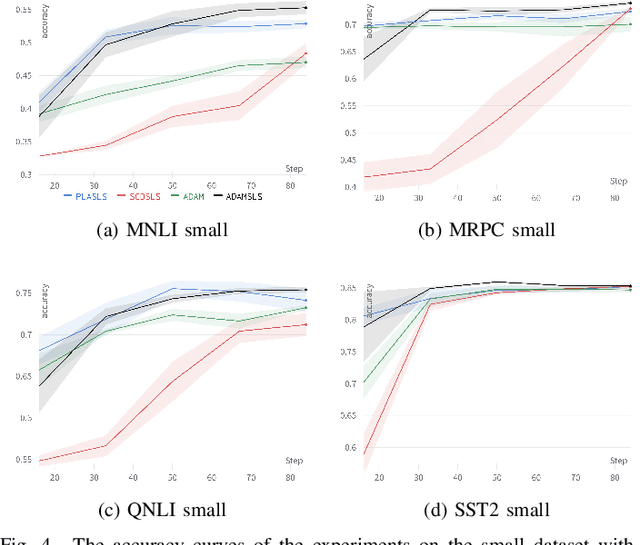
Recent works have shown that line search methods greatly increase performance of traditional stochastic gradient descent methods on a variety of datasets and architectures [1], [2]. In this work we succeed in extending line search methods to the novel and highly popular Transformer architecture and dataset domains in natural language processing. More specifically, we combine the Armijo line search with the Adam optimizer and extend it by subdividing the networks architecture into sensible units and perform the line search separately on these local units. Our optimization method outperforms the traditional Adam optimizer and achieves significant performance improvements for small data sets or small training budgets, while performing equal or better for other tested cases. Our work is publicly available as a python package, which provides a hyperparameter-free pytorch optimizer that is compatible with arbitrary network architectures.
Don't be so Monotone: Relaxing Stochastic Line Search in Over-Parameterized Models
Jun 22, 2023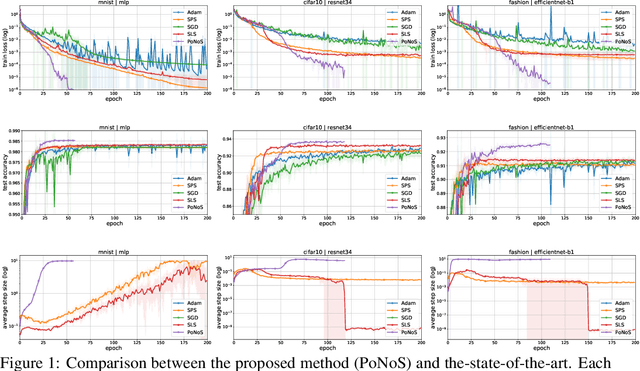
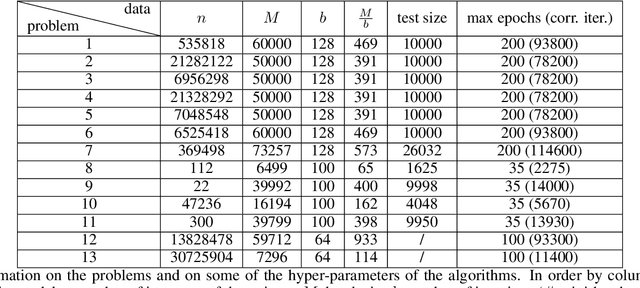
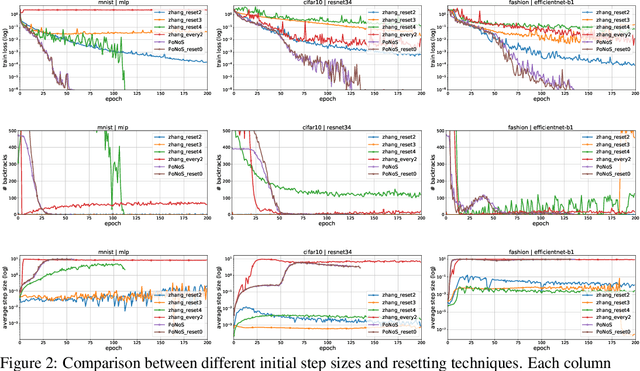

Recent works have shown that line search methods can speed up Stochastic Gradient Descent (SGD) and Adam in modern over-parameterized settings. However, existing line searches may take steps that are smaller than necessary since they require a monotone decrease of the (mini-)batch objective function. We explore nonmonotone line search methods to relax this condition and possibly accept larger step sizes. Despite the lack of a monotonic decrease, we prove the same fast rates of convergence as in the monotone case. Our experiments show that nonmonotone methods improve the speed of convergence and generalization properties of SGD/Adam even beyond the previous monotone line searches. We propose a POlyak NOnmonotone Stochastic (PoNoS) method, obtained by combining a nonmonotone line search with a Polyak initial step size. Furthermore, we develop a new resetting technique that in the majority of the iterations reduces the amount of backtracks to zero while still maintaining a large initial step size. To the best of our knowledge, a first runtime comparison shows that the epoch-wise advantage of line-search-based methods gets reflected in the overall computational time.