 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Has The Final Say? Conformity Dynamics in ChatGPT's Selections
Oct 30, 2025



Large language models (LLMs) such as ChatGPT are increasingly integrated into high-stakes decision-making, yet little is known about their susceptibility to social influence. We conducted three preregistered conformity experiments with GPT-4o in a hiring context. In a baseline study, GPT consistently favored the same candidate (Profile C), reported moderate expertise (M = 3.01) and high certainty (M = 3.89), and rarely changed its choice. In Study 1 (GPT + 8), GPT faced unanimous opposition from eight simulated partners and almost always conformed (99.9%), reporting lower certainty and significantly elevated self-reported informational and normative conformity (p < .001). In Study 2 (GPT + 1), GPT interacted with a single partner and still conformed in 40.2% of disagreement trials, reporting less certainty and more normative conformity. Across studies, results demonstrate that GPT does not act as an independent observer but adapts to perceived social consensus. These findings highlight risks of treating LLMs as neutral decision aids and underline the need to elicit AI judgments prior to exposing them to human opinions.
Uncertainty-Aware Remaining Lifespan Prediction from Images
Jun 16, 2025



Predicting mortality-related outcomes from images offers the prospect of accessible, noninvasive, and scalable health screening. We present a method that leverages pretrained vision transformer foundation models to estimate remaining lifespan from facial and whole-body images, alongside robust uncertainty quantification. We show that predictive uncertainty varies systematically with the true remaining lifespan, and that this uncertainty can be effectively modeled by learning a Gaussian distribution for each sample. Our approach achieves state-of-the-art mean absolute error (MAE) of 7.48 years on an established Dataset, and further improves to 4.79 and 5.07 years MAE on two new, higher-quality datasets curated and published in this work. Importantly, our models provide well-calibrated uncertainty estimates, as demonstrated by a bucketed expected calibration error of 0.62 years. While not intended for clinical deployment, these results highlight the potential of extracting medically relevant signals from images. We make all code and datasets available to facilitate further research.
JEPA for RL: Investigating Joint-Embedding Predictive Architectures for Reinforcement Learning
Apr 23, 2025


Joint-Embedding Predictive Architectures (JEPA) have recently become popular as promising architectures for self-supervised learning. Vision transformers have been trained using JEPA to produce embeddings from images and videos, which have been shown to be highly suitable for downstream tasks like classification and segmentation. In this paper, we show how to adapt the JEPA architecture to reinforcement learning from images. We discuss model collapse, show how to prevent it, and provide exemplary data on the classical Cart Pole task.
No learning rates needed: Introducing SALSA -- Stable Armijo Line Search Adaptation
Jul 30, 2024In recent studies, line search methods have been demonstrated to significantly enhance the performance of conventional stochastic gradient descent techniques across various datasets and architectures, while making an otherwise critical choice of learning rate schedule superfluous. In this paper, we identify problems of current state-of-the-art of line search methods, propose enhancements, and rigorously assess their effectiveness. Furthermore, we evaluate these methods on orders of magnitude larger datasets and more complex data domains than previously done. More specifically, we enhance the Armijo line search method by speeding up its computation and incorporating a momentum term into the Armijo criterion, making it better suited for stochastic mini-batching. Our optimization approach outperforms both the previous Armijo implementation and a tuned learning rate schedule for the Adam and SGD optimizers. Our evaluation covers a diverse range of architectures, such as Transformers, CNNs, and MLPs, as well as data domains, including NLP and image data. Our work is publicly available as a Python package, which provides a simple Pytorch optimizer.
Faster Convergence for Transformer Fine-tuning with Line Search Methods
Mar 27, 2024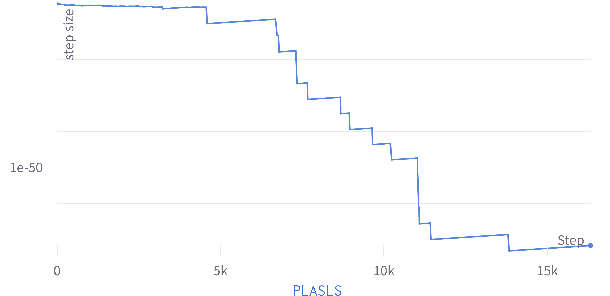
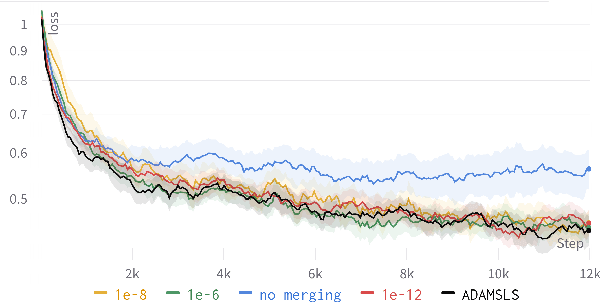
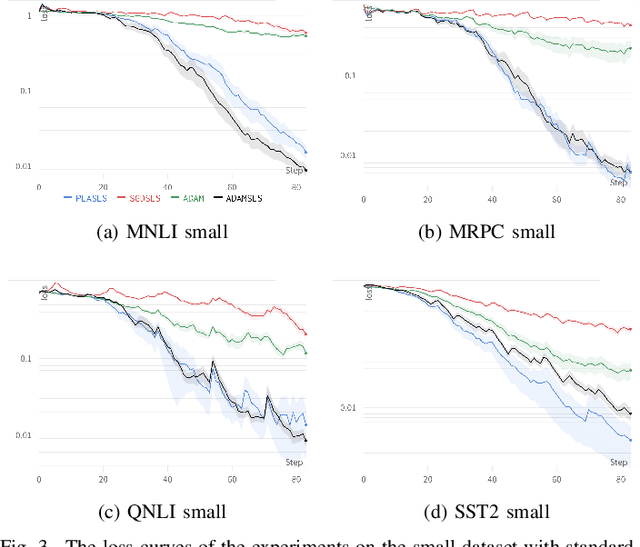
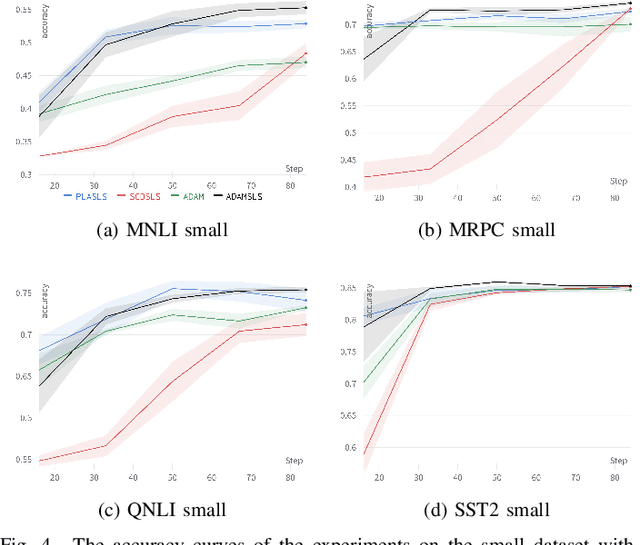
Recent works have shown that line search methods greatly increase performance of traditional stochastic gradient descent methods on a variety of datasets and architectures [1], [2]. In this work we succeed in extending line search methods to the novel and highly popular Transformer architecture and dataset domains in natural language processing. More specifically, we combine the Armijo line search with the Adam optimizer and extend it by subdividing the networks architecture into sensible units and perform the line search separately on these local units. Our optimization method outperforms the traditional Adam optimizer and achieves significant performance improvements for small data sets or small training budgets, while performing equal or better for other tested cases. Our work is publicly available as a python package, which provides a hyperparameter-free pytorch optimizer that is compatible with arbitrary network architectures.
Improving Line Search Methods for Large Scale Neural Network Training
Mar 27, 2024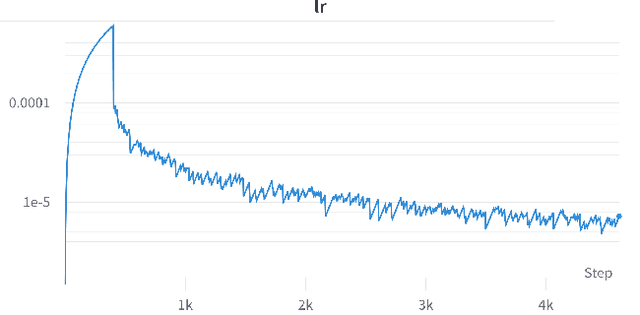
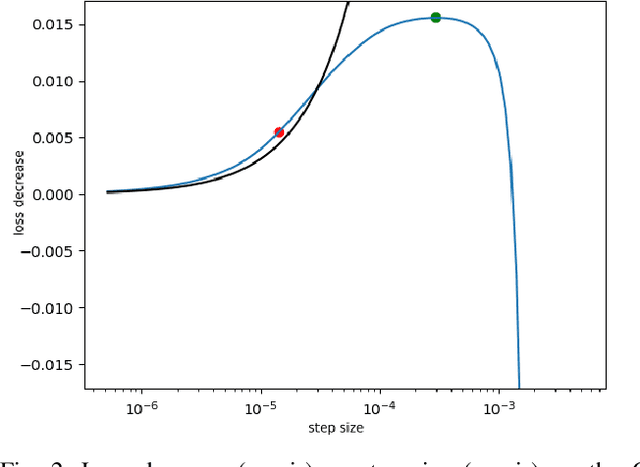
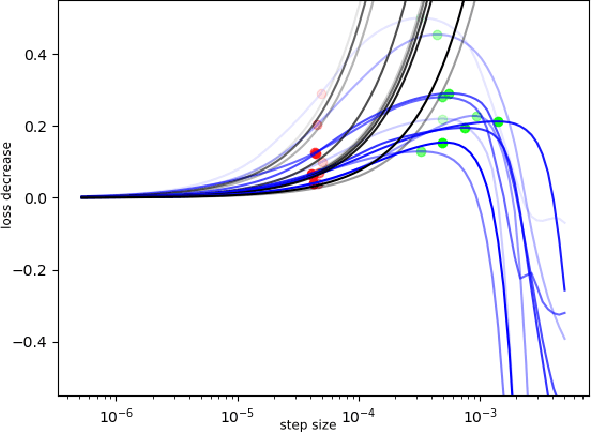
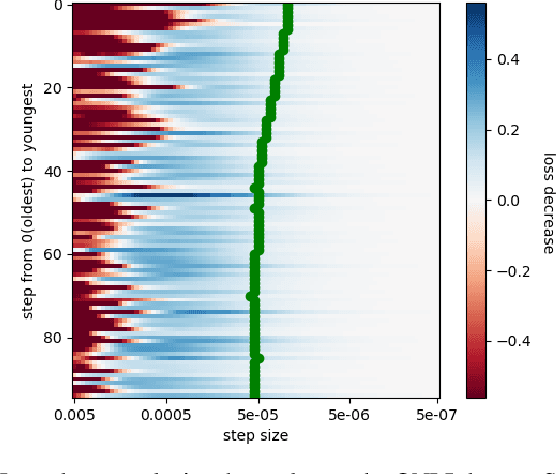
In recent studies, line search methods have shown significant improvements in the performance of traditional stochastic gradient descent techniques, eliminating the need for a specific learning rate schedule. In this paper, we identify existing issues in state-of-the-art line search methods, propose enhancements, and rigorously evaluate their effectiveness. We test these methods on larger datasets and more complex data domains than before. Specifically, we improve the Armijo line search by integrating the momentum term from ADAM in its search direction, enabling efficient large-scale training, a task that was previously prone to failure using Armijo line search methods. Our optimization approach outperforms both the previous Armijo implementation and tuned learning rate schedules for Adam. Our evaluation focuses on Transformers and CNNs in the domains of NLP and image data. Our work is publicly available as a Python package, which provides a hyperparameter free Pytorch optimizer.
Retrieval Augmented Generation Systems: Automatic Dataset Creation, Evaluation and Boolean Agent Setup
Feb 26, 2024



Retrieval Augmented Generation (RAG) systems have seen huge popularity in augmenting Large-Language Model (LLM) outputs with domain specific and time sensitive data. Very recently a shift is happening from simple RAG setups that query a vector database for additional information with every user input to more sophisticated forms of RAG. However, different concrete approaches compete on mostly anecdotal evidence at the moment. In this paper we present a rigorous dataset creation and evaluation workflow to quantitatively compare different RAG strategies. We use a dataset created this way for the development and evaluation of a boolean agent RAG setup: A system in which a LLM can decide whether to query a vector database or not, thus saving tokens on questions that can be answered with internal knowledge. We publish our code and generated dataset online.