 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaplEIG: Bayesian Experimental Design for Shapley Value Estimation
Jun 01, 2026Shapley values are a principled attribution measure widely used in interpretable machine learning, but their exact computation scales exponentially with the number of players, motivating a wide range of approximation methods based on value function evaluations of sampled coalitions. This raises the question of whether approximation accuracy can be improved by adaptively selecting coalitions for evaluation based on previous evaluations. This is particularly relevant in settings where the value function is costly and the number of evaluations is severely limited, such as retraining-based feature importance, data valuation, and hyperparameter importance. For this purpose, we propose ShaplEIG, a Bayesian experimental design approach that approximates the expensive value function using a Gaussian process surrogate and adaptively selects coalitions based on their expected information gain about the Shapley values. By the linearity of the Shapley values in the value function, we show that the expected information gain is available in closed form. Furthermore, we propose an efficient computation scheme that reduces the complexity from exponential to polynomial in the number of players via elementary symmetric polynomials. In extensive experiments across diverse costly applications, our method consistently improves sample efficiency in the low-budget regime over state-of-the-art baselines.
Proxy-Based Approximation of Shapley and Banzhaf Interactions
May 21, 2026Shapley and Banzhaf interactions capture the complex dynamics inherent in modern machine learning applications. However, current estimators for these higher-order interactions trade off between speed and accuracy. To overcome this limitation, we introduce ProxySHAP. ProxySHAP reconciles the high sample efficiency of tree-based proxy models with a principled path to consistency via residual correction. On a theoretical level, we derive a polynomial-time generalization of interventional TreeSHAP to compute exact interaction indices for tree ensembles, successfully bypassing exponential tree-depth dependencies in prior methods. Furthermore, we formally analyze the residual adjustment strategy, characterizing the specific conditions under which Maximum Sample Reuse (MSR) corrects proxy bias without its variance scaling exponentially with interaction size. Extensive benchmarking demonstrates that ProxySHAP sets a new state-of-the-art standard for approximation quality, including in large-scale applications with thousands of features. By achieving the lowest error in both small- and large-budget regimes, ProxySHAP significantly outperforms the prior best estimators ProxySPEX and KernelSHAP-IQ, while also delivering superior performance on downstream explainability tasks.
Attributions All the Way Down? The Metagame of Interpretability
May 07, 2026We introduce the metagame, a conceptual framework for quantifying second-order interaction effects of model explanations. For any first-order attribution $φ(f)$ explaining a model $f$, we measure the directional influence of feature $j$ on the attribution of feature $i$, denoted as meta-attribution $\varphi_{j \to i}(f)$, by treating the attribution method itself as a cooperative game and computing its Shapley value. Theoretically, we prove that attributions hierarchically decompose into meta-attributions, and establish these as directional extensions of existing interaction indices. Empirically, we demonstrate that the metagame delivers insights across diverse interpretability applications: (i) quantifying token interactions in instruction-tuned language models, (ii) explaining cross-modal similarity in vision-language encoders, and (iii) interpreting text-to-image concepts in multimodal diffusion transformers.
Functional Decomposition and Shapley Interactions for Interpreting Survival Models
Feb 18, 2026Hazard and survival functions are natural, interpretable targets in time-to-event prediction, but their inherent non-additivity fundamentally limits standard additive explanation methods. We introduce Survival Functional Decomposition (SurvFD), a principled approach for analyzing feature interactions in machine learning survival models. By decomposing higher-order effects into time-dependent and time-independent components, SurvFD offers a previously unrecognized perspective on survival explanations, explicitly characterizing when and why additive explanations fail. Building on this theoretical decomposition, we propose SurvSHAP-IQ, which extends Shapley interactions to time-indexed functions, providing a practical estimator for higher-order, time-dependent interactions. Together, SurvFD and SurvSHAP-IQ establish an interaction- and time-aware interpretability approach for survival modeling, with broad applicability across time-to-event prediction tasks.
Exactly Computing do-Shapley Values
Feb 06, 2026Structural Causal Models (SCM) are a powerful framework for describing complicated dynamics across the natural sciences. A particularly elegant way of interpreting SCMs is do-Shapley, a game-theoretic method of quantifying the average effect of $d$ variables across exponentially many interventions. Like Shapley values, computing do-Shapley values generally requires evaluating exponentially many terms. The foundation of our work is a reformulation of do-Shapley values in terms of the irreducible sets of the underlying SCM. Leveraging this insight, we can exactly compute do-Shapley values in time linear in the number of irreducible sets $r$, which itself can range from $d$ to $2^d$ depending on the graph structure of the SCM. Since $r$ is unknown a priori, we complement the exact algorithm with an estimator that, like general Shapley value estimators, can be run with any query budget. As the query budget approaches $r$, our estimators can produce more accurate estimates than prior methods by several orders of magnitude, and, when the budget reaches $r$, return the Shapley values up to machine precision. Beyond computational speed, we also reduce the identification burden: we prove that non-parametric identifiability of do-Shapley values requires only the identification of interventional effects for the $d$ singleton coalitions, rather than all classes.
An Odd Estimator for Shapley Values
Feb 01, 2026The Shapley value is a ubiquitous framework for attribution in machine learning, encompassing feature importance, data valuation, and causal inference. However, its exact computation is generally intractable, necessitating efficient approximation methods. While the most effective and popular estimators leverage the paired sampling heuristic to reduce estimation error, the theoretical mechanism driving this improvement has remained opaque. In this work, we provide an elegant and fundamental justification for paired sampling: we prove that the Shapley value depends exclusively on the odd component of the set function, and that paired sampling orthogonalizes the regression objective to filter out the irrelevant even component. Leveraging this insight, we propose OddSHAP, a novel consistent estimator that performs polynomial regression solely on the odd subspace. By utilizing the Fourier basis to isolate this subspace and employing a proxy model to identify high-impact interactions, OddSHAP overcomes the combinatorial explosion of higher-order approximations. Through an extensive benchmark evaluation, we find that OddSHAP achieves state-of-the-art estimation accuracy.
GRANITE: A Generalized Regional Framework for Identifying Agreement in Feature-Based Explanations
Jan 30, 2026Feature-based explanation methods aim to quantify how features influence the model's behavior, either locally or globally, but different methods often disagree, producing conflicting explanations. This disagreement arises primarily from two sources: how feature interactions are handled and how feature dependencies are incorporated. We propose GRANITE, a generalized regional explanation framework that partitions the feature space into regions where interaction and distribution influences are minimized. This approach aligns different explanation methods, yielding more consistent and interpretable explanations. GRANITE unifies existing regional approaches, extends them to feature groups, and introduces a recursive partitioning algorithm to estimate such regions. We demonstrate its effectiveness on real-world datasets, providing a practical tool for consistent and interpretable feature explanations.
PolySHAP: Extending KernelSHAP with Interaction-Informed Polynomial Regression
Jan 26, 2026Shapley values have emerged as a central game-theoretic tool in explainable AI (XAI). However, computing Shapley values exactly requires $2^d$ game evaluations for a model with $d$ features. Lundberg and Lee's KernelSHAP algorithm has emerged as a leading method for avoiding this exponential cost. KernelSHAP approximates Shapley values by approximating the game as a linear function, which is fit using a small number of game evaluations for random feature subsets. In this work, we extend KernelSHAP by approximating the game via higher degree polynomials, which capture non-linear interactions between features. Our resulting PolySHAP method yields empirically better Shapley value estimates for various benchmark datasets, and we prove that these estimates are consistent. Moreover, we connect our approach to paired sampling (antithetic sampling), a ubiquitous modification to KernelSHAP that improves empirical accuracy. We prove that paired sampling outputs exactly the same Shapley value approximations as second-order PolySHAP, without ever fitting a degree 2 polynomial. To the best of our knowledge, this finding provides the first strong theoretical justification for the excellent practical performance of the paired sampling heuristic.
Explaining Similarity in Vision-Language Encoders with Weighted Banzhaf Interactions
Aug 07, 2025


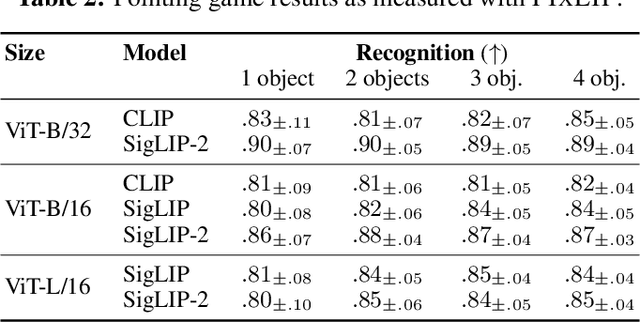
Language-image pre-training (LIP) enables the development of vision-language models capable of zero-shot classification, localization, multimodal retrieval, and semantic understanding. Various explanation methods have been proposed to visualize the importance of input image-text pairs on the model's similarity outputs. However, popular saliency maps are limited by capturing only first-order attributions, overlooking the complex cross-modal interactions intrinsic to such encoders. We introduce faithful interaction explanations of LIP models (FIxLIP) as a unified approach to decomposing the similarity in vision-language encoders. FIxLIP is rooted in game theory, where we analyze how using the weighted Banzhaf interaction index offers greater flexibility and improves computational efficiency over the Shapley interaction quantification framework. From a practical perspective, we propose how to naturally extend explanation evaluation metrics, like the pointing game and area between the insertion/deletion curves, to second-order interaction explanations. Experiments on MS COCO and ImageNet-1k benchmarks validate that second-order methods like FIxLIP outperform first-order attribution methods. Beyond delivering high-quality explanations, we demonstrate the utility of FIxLIP in comparing different models like CLIP vs. SigLIP-2 and ViT-B/32 vs. ViT-L/16.
Adaptive Prompting: Ad-hoc Prompt Composition for Social Bias Detection
Feb 10, 2025Recent advances on instruction fine-tuning have led to the development of various prompting techniques for large language models, such as explicit reasoning steps. However, the success of techniques depends on various parameters, such as the task, language model, and context provided. Finding an effective prompt is, therefore, often a trial-and-error process. Most existing approaches to automatic prompting aim to optimize individual techniques instead of compositions of techniques and their dependence on the input. To fill this gap, we propose an adaptive prompting approach that predicts the optimal prompt composition ad-hoc for a given input. We apply our approach to social bias detection, a highly context-dependent task that requires semantic understanding. We evaluate it with three large language models on three datasets, comparing compositions to individual techniques and other baselines. The results underline the importance of finding an effective prompt composition. Our approach robustly ensures high detection performance, and is best in several settings. Moreover, first experiments on other tasks support its generalizability.