 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRANITE: A Generalized Regional Framework for Identifying Agreement in Feature-Based Explanations
Jan 30, 2026Feature-based explanation methods aim to quantify how features influence the model's behavior, either locally or globally, but different methods often disagree, producing conflicting explanations. This disagreement arises primarily from two sources: how feature interactions are handled and how feature dependencies are incorporated. We propose GRANITE, a generalized regional explanation framework that partitions the feature space into regions where interaction and distribution influences are minimized. This approach aligns different explanation methods, yielding more consistent and interpretable explanations. GRANITE unifies existing regional approaches, extends them to feature groups, and introduces a recursive partitioning algorithm to estimate such regions. We demonstrate its effectiveness on real-world datasets, providing a practical tool for consistent and interpretable feature explanations.
Explaining Similarity in Vision-Language Encoders with Weighted Banzhaf Interactions
Aug 07, 2025Language-image pre-training (LIP) enables the development of vision-language models capable of zero-shot classification, localization, multimodal retrieval, and semantic understanding. Various explanation methods have been proposed to visualize the importance of input image-text pairs on the model's similarity outputs. However, popular saliency maps are limited by capturing only first-order attributions, overlooking the complex cross-modal interactions intrinsic to such encoders. We introduce faithful interaction explanations of LIP models (FIxLIP) as a unified approach to decomposing the similarity in vision-language encoders. FIxLIP is rooted in game theory, where we analyze how using the weighted Banzhaf interaction index offers greater flexibility and improves computational efficiency over the Shapley interaction quantification framework. From a practical perspective, we propose how to naturally extend explanation evaluation metrics, like the pointing game and area between the insertion/deletion curves, to second-order interaction explanations. Experiments on MS COCO and ImageNet-1k benchmarks validate that second-order methods like FIxLIP outperform first-order attribution methods. Beyond delivering high-quality explanations, we demonstrate the utility of FIxLIP in comparing different models like CLIP vs. SigLIP-2 and ViT-B/32 vs. ViT-L/16.
Adaptive Prompting: Ad-hoc Prompt Composition for Social Bias Detection
Feb 10, 2025Recent advances on instruction fine-tuning have led to the development of various prompting techniques for large language models, such as explicit reasoning steps. However, the success of techniques depends on various parameters, such as the task, language model, and context provided. Finding an effective prompt is, therefore, often a trial-and-error process. Most existing approaches to automatic prompting aim to optimize individual techniques instead of compositions of techniques and their dependence on the input. To fill this gap, we propose an adaptive prompting approach that predicts the optimal prompt composition ad-hoc for a given input. We apply our approach to social bias detection, a highly context-dependent task that requires semantic understanding. We evaluate it with three large language models on three datasets, comparing compositions to individual techniques and other baselines. The results underline the importance of finding an effective prompt composition. Our approach robustly ensures high detection performance, and is best in several settings. Moreover, first experiments on other tasks support its generalizability.
HyperSHAP: Shapley Values and Interactions for Hyperparameter Importance
Feb 03, 2025Hyperparameter optimization (HPO) is a crucial step in achieving strong predictive performance. However, the impact of individual hyperparameters on model generalization is highly context-dependent, prohibiting a one-size-fits-all solution and requiring opaque automated machine learning (AutoML) systems to find optimal configurations. The black-box nature of most AutoML systems undermines user trust and discourages adoption. To address this, we propose a game-theoretic explainability framework for HPO that is based on Shapley values and interactions. Our approach provides an additive decomposition of a performance measure across hyperparameters, enabling local and global explanations of hyperparameter importance and interactions. The framework, named HyperSHAP, offers insights into ablations, the tunability of learning algorithms, and optimizer behavior across different hyperparameter spaces. We evaluate HyperSHAP on various HPO benchmarks by analyzing the interaction structure of the HPO problem. Our results show that while higher-order interactions exist, most performance improvements can be explained by focusing on lower-order representations.
Exact Computation of Any-Order Shapley Interactions for Graph Neural Networks
Jan 28, 2025Albeit the ubiquitous use of Graph Neural Networks (GNNs) in machine learning (ML) prediction tasks involving graph-structured data, their interpretability remains challenging. In explainable artificial intelligence (XAI), the Shapley Value (SV) is the predominant method to quantify contributions of individual features to a ML model's output. Addressing the limitations of SVs in complex prediction models, Shapley Interactions (SIs) extend the SV to groups of features. In this work, we explain single graph predictions of GNNs with SIs that quantify node contributions and interactions among multiple nodes. By exploiting the GNN architecture, we show that the structure of interactions in node embeddings are preserved for graph prediction. As a result, the exponential complexity of SIs depends only on the receptive fields, i.e. the message-passing ranges determined by the connectivity of the graph and the number of convolutional layers. Based on our theoretical results, we introduce GraphSHAP-IQ, an efficient approach to compute any-order SIs exactly. GraphSHAP-IQ is applicable to popular message passing techniques in conjunction with a linear global pooling and output layer. We showcase that GraphSHAP-IQ substantially reduces the exponential complexity of computing exact SIs on multiple benchmark datasets. Beyond exact computation, we evaluate GraphSHAP-IQ's approximation of SIs on popular GNN architectures and compare with existing baselines. Lastly, we visualize SIs of real-world water distribution networks and molecule structures using a SI-Graph.
Unifying Feature-Based Explanations with Functional ANOVA and Cooperative Game Theory
Dec 22, 2024Feature-based explanations, using perturbations or gradients, are a prevalent tool to understand decisions of black box machine learning models. Yet, differences between these methods still remain mostly unknown, which limits their applicability for practitioners. In this work, we introduce a unified framework for local and global feature-based explanations using two well-established concepts: functional ANOVA (fANOVA) from statistics, and the notion of value and interaction from cooperative game theory. We introduce three fANOVA decompositions that determine the influence of feature distributions, and use game-theoretic measures, such as the Shapley value and interactions, to specify the influence of higher-order interactions. Our framework combines these two dimensions to uncover similarities and differences between a wide range of explanation techniques for features and groups of features. We then empirically showcase the usefulness of our framework on synthetic and real-world datasets.
shapiq: Shapley Interactions for Machine Learning
Oct 02, 2024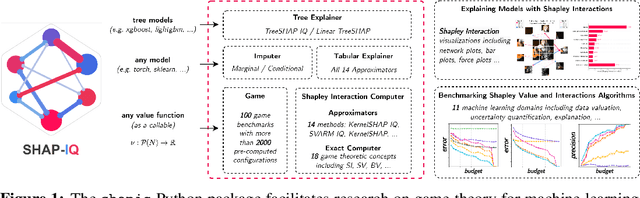
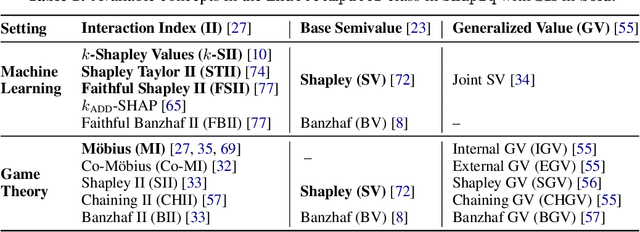
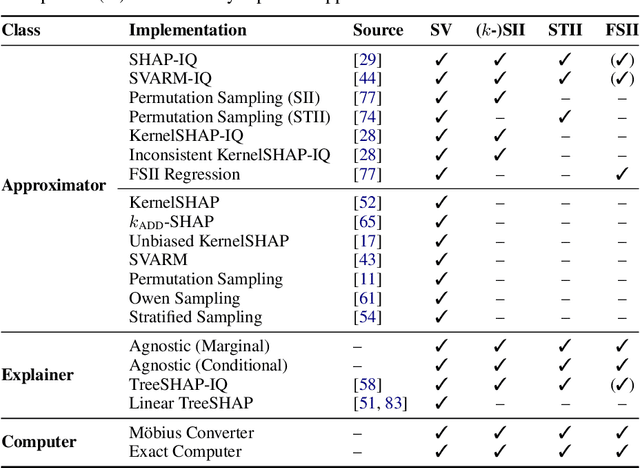
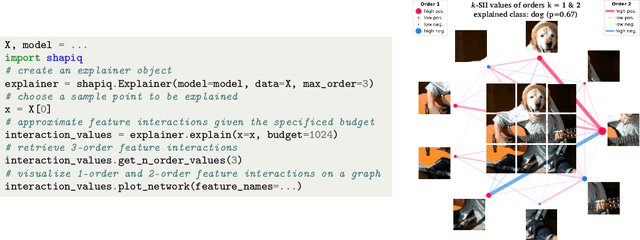
Originally rooted in game theory, the Shapley Value (SV) has recently become an important tool in machine learning research. Perhaps most notably, it is used for feature attribution and data valuation in explainable artificial intelligence. Shapley Interactions (SIs) naturally extend the SV and address its limitations by assigning joint contributions to groups of entities, which enhance understanding of black box machine learning models. Due to the exponential complexity of computing SVs and SIs, various methods have been proposed that exploit structural assumptions or yield probabilistic estimates given limited resources. In this work, we introduce shapiq, an open-source Python package that unifies state-of-the-art algorithms to efficiently compute SVs and any-order SIs in an application-agnostic framework. Moreover, it includes a benchmarking suite containing 11 machine learning applications of SIs with pre-computed games and ground-truth values to systematically assess computational performance across domains. For practitioners, shapiq is able to explain and visualize any-order feature interactions in predictions of models, including vision transformers, language models, as well as XGBoost and LightGBM with TreeSHAP-IQ. With shapiq, we extend shap beyond feature attributions and consolidate the application of SVs and SIs in machine learning that facilitates future research. The source code and documentation are available at https://github.com/mmschlk/shapiq.
KernelSHAP-IQ: Weighted Least-Square Optimization for Shapley Interactions
May 17, 2024The Shapley value (SV) is a prevalent approach of allocating credit to machine learning (ML) entities to understand black box ML models. Enriching such interpretations with higher-order interactions is inevitable for complex systems, where the Shapley Interaction Index (SII) is a direct axiomatic extension of the SV. While it is well-known that the SV yields an optimal approximation of any game via a weighted least square (WLS) objective, an extension of this result to SII has been a long-standing open problem, which even led to the proposal of an alternative index. In this work, we characterize higher-order SII as a solution to a WLS problem, which constructs an optimal approximation via SII and $k$-Shapley values ($k$-SII). We prove this representation for the SV and pairwise SII and give empirically validated conjectures for higher orders. As a result, we propose KernelSHAP-IQ, a direct extension of KernelSHAP for SII, and demonstrate state-of-the-art performance for feature interactions.
Beyond TreeSHAP: Efficient Computation of Any-Order Shapley Interactions for Tree Ensembles
Jan 22, 2024While shallow decision trees may be interpretable, larger ensemble models like gradient-boosted trees, which often set the state of the art in machine learning problems involving tabular data, still remain black box models. As a remedy, the Shapley value (SV) is a well-known concept in explainable artificial intelligence (XAI) research for quantifying additive feature attributions of predictions. The model-specific TreeSHAP methodology solves the exponential complexity for retrieving exact SVs from tree-based models. Expanding beyond individual feature attribution, Shapley interactions reveal the impact of intricate feature interactions of any order. In this work, we present TreeSHAP-IQ, an efficient method to compute any-order additive Shapley interactions for predictions of tree-based models. TreeSHAP-IQ is supported by a mathematical framework that exploits polynomial arithmetic to compute the interaction scores in a single recursive traversal of the tree, akin to Linear TreeSHAP. We apply TreeSHAP-IQ on state-of-the-art tree ensembles and explore interactions on well-established benchmark datasets.
iPDP: On Partial Dependence Plots in Dynamic Modeling Scenarios
Jun 13, 2023Post-hoc explanation techniques such as the well-established partial dependence plot (PDP), which investigates feature dependencies, are used in explainable artificial intelligence (XAI) to understand black-box machine learning models. While many real-world applications require dynamic models that constantly adapt over time and react to changes in the underlying distribution, XAI, so far, has primarily considered static learning environments, where models are trained in a batch mode and remain unchanged. We thus propose a novel model-agnostic XAI framework called incremental PDP (iPDP) that extends on the PDP to extract time-dependent feature effects in non-stationary learning environments. We formally analyze iPDP and show that it approximates a time-dependent variant of the PDP that properly reacts to real and virtual concept drift. The time-sensitivity of iPDP is controlled by a single smoothing parameter, which directly corresponds to the variance and the approximation error of iPDP in a static learning environment. We illustrate the efficacy of iPDP by showcasing an example application for drift detection and conducting multiple experiments on real-world and synthetic data sets and streams.