 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProxy-Based Approximation of Shapley and Banzhaf Interactions
May 21, 2026Shapley and Banzhaf interactions capture the complex dynamics inherent in modern machine learning applications. However, current estimators for these higher-order interactions trade off between speed and accuracy. To overcome this limitation, we introduce ProxySHAP. ProxySHAP reconciles the high sample efficiency of tree-based proxy models with a principled path to consistency via residual correction. On a theoretical level, we derive a polynomial-time generalization of interventional TreeSHAP to compute exact interaction indices for tree ensembles, successfully bypassing exponential tree-depth dependencies in prior methods. Furthermore, we formally analyze the residual adjustment strategy, characterizing the specific conditions under which Maximum Sample Reuse (MSR) corrects proxy bias without its variance scaling exponentially with interaction size. Extensive benchmarking demonstrates that ProxySHAP sets a new state-of-the-art standard for approximation quality, including in large-scale applications with thousands of features. By achieving the lowest error in both small- and large-budget regimes, ProxySHAP significantly outperforms the prior best estimators ProxySPEX and KernelSHAP-IQ, while also delivering superior performance on downstream explainability tasks.
Attributions All the Way Down? The Metagame of Interpretability
May 07, 2026We introduce the metagame, a conceptual framework for quantifying second-order interaction effects of model explanations. For any first-order attribution $φ(f)$ explaining a model $f$, we measure the directional influence of feature $j$ on the attribution of feature $i$, denoted as meta-attribution $\varphi_{j \to i}(f)$, by treating the attribution method itself as a cooperative game and computing its Shapley value. Theoretically, we prove that attributions hierarchically decompose into meta-attributions, and establish these as directional extensions of existing interaction indices. Empirically, we demonstrate that the metagame delivers insights across diverse interpretability applications: (i) quantifying token interactions in instruction-tuned language models, (ii) explaining cross-modal similarity in vision-language encoders, and (iii) interpreting text-to-image concepts in multimodal diffusion transformers.
Functional Decomposition and Shapley Interactions for Interpreting Survival Models
Feb 18, 2026Hazard and survival functions are natural, interpretable targets in time-to-event prediction, but their inherent non-additivity fundamentally limits standard additive explanation methods. We introduce Survival Functional Decomposition (SurvFD), a principled approach for analyzing feature interactions in machine learning survival models. By decomposing higher-order effects into time-dependent and time-independent components, SurvFD offers a previously unrecognized perspective on survival explanations, explicitly characterizing when and why additive explanations fail. Building on this theoretical decomposition, we propose SurvSHAP-IQ, which extends Shapley interactions to time-indexed functions, providing a practical estimator for higher-order, time-dependent interactions. Together, SurvFD and SurvSHAP-IQ establish an interaction- and time-aware interpretability approach for survival modeling, with broad applicability across time-to-event prediction tasks.
Explaining Similarity in Vision-Language Encoders with Weighted Banzhaf Interactions
Aug 07, 2025


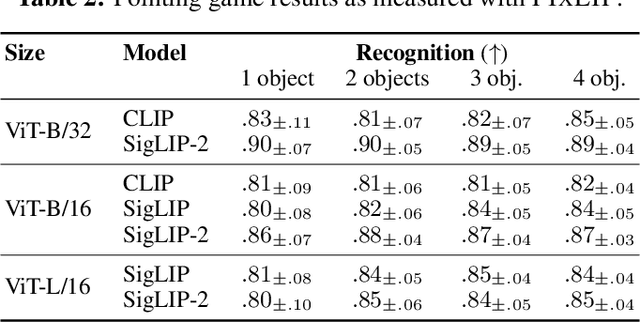
Language-image pre-training (LIP) enables the development of vision-language models capable of zero-shot classification, localization, multimodal retrieval, and semantic understanding. Various explanation methods have been proposed to visualize the importance of input image-text pairs on the model's similarity outputs. However, popular saliency maps are limited by capturing only first-order attributions, overlooking the complex cross-modal interactions intrinsic to such encoders. We introduce faithful interaction explanations of LIP models (FIxLIP) as a unified approach to decomposing the similarity in vision-language encoders. FIxLIP is rooted in game theory, where we analyze how using the weighted Banzhaf interaction index offers greater flexibility and improves computational efficiency over the Shapley interaction quantification framework. From a practical perspective, we propose how to naturally extend explanation evaluation metrics, like the pointing game and area between the insertion/deletion curves, to second-order interaction explanations. Experiments on MS COCO and ImageNet-1k benchmarks validate that second-order methods like FIxLIP outperform first-order attribution methods. Beyond delivering high-quality explanations, we demonstrate the utility of FIxLIP in comparing different models like CLIP vs. SigLIP-2 and ViT-B/32 vs. ViT-L/16.
Birds look like cars: Adversarial analysis of intrinsically interpretable deep learning
Mar 11, 2025A common belief is that intrinsically interpretable deep learning models ensure a correct, intuitive understanding of their behavior and offer greater robustness against accidental errors or intentional manipulation. However, these beliefs have not been comprehensively verified, and growing evidence casts doubt on them. In this paper, we highlight the risks related to overreliance and susceptibility to adversarial manipulation of these so-called "intrinsically (aka inherently) interpretable" models by design. We introduce two strategies for adversarial analysis with prototype manipulation and backdoor attacks against prototype-based networks, and discuss how concept bottleneck models defend against these attacks. Fooling the model's reasoning by exploiting its use of latent prototypes manifests the inherent uninterpretability of deep neural networks, leading to a false sense of security reinforced by a visual confirmation bias. The reported limitations of prototype-based networks put their trustworthiness and applicability into question, motivating further work on the robustness and alignment of (deep) interpretable models.
Interpreting CLIP with Hierarchical Sparse Autoencoders
Feb 27, 2025



Sparse autoencoders (SAEs) are useful for detecting and steering interpretable features in neural networks, with particular potential for understanding complex multimodal representations. Given their ability to uncover interpretable features, SAEs are particularly valuable for analyzing large-scale vision-language models (e.g., CLIP and SigLIP), which are fundamental building blocks in modern systems yet remain challenging to interpret and control. However, current SAE methods are limited by optimizing both reconstruction quality and sparsity simultaneously, as they rely on either activation suppression or rigid sparsity constraints. To this end, we introduce Matryoshka SAE (MSAE), a new architecture that learns hierarchical representations at multiple granularities simultaneously, enabling a direct optimization of both metrics without compromise. MSAE establishes a new state-of-the-art Pareto frontier between reconstruction quality and sparsity for CLIP, achieving 0.99 cosine similarity and less than 0.1 fraction of variance unexplained while maintaining ~80% sparsity. Finally, we demonstrate the utility of MSAE as a tool for interpreting and controlling CLIP by extracting over 120 semantic concepts from its representation to perform concept-based similarity search and bias analysis in downstream tasks like CelebA.
shapiq: Shapley Interactions for Machine Learning
Oct 02, 2024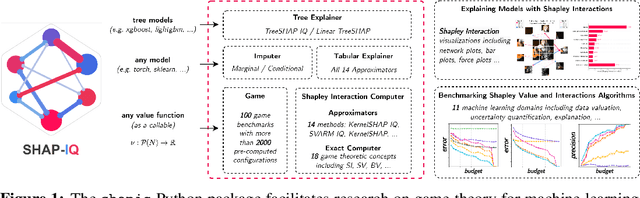
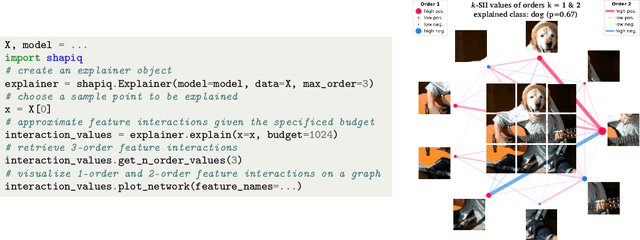
Originally rooted in game theory, the Shapley Value (SV) has recently become an important tool in machine learning research. Perhaps most notably, it is used for feature attribution and data valuation in explainable artificial intelligence. Shapley Interactions (SIs) naturally extend the SV and address its limitations by assigning joint contributions to groups of entities, which enhance understanding of black box machine learning models. Due to the exponential complexity of computing SVs and SIs, various methods have been proposed that exploit structural assumptions or yield probabilistic estimates given limited resources. In this work, we introduce shapiq, an open-source Python package that unifies state-of-the-art algorithms to efficiently compute SVs and any-order SIs in an application-agnostic framework. Moreover, it includes a benchmarking suite containing 11 machine learning applications of SIs with pre-computed games and ground-truth values to systematically assess computational performance across domains. For practitioners, shapiq is able to explain and visualize any-order feature interactions in predictions of models, including vision transformers, language models, as well as XGBoost and LightGBM with TreeSHAP-IQ. With shapiq, we extend shap beyond feature attributions and consolidate the application of SVs and SIs in machine learning that facilitates future research. The source code and documentation are available at https://github.com/mmschlk/shapiq.
Aggregated Attributions for Explanatory Analysis of 3D Segmentation Models
Jul 24, 2024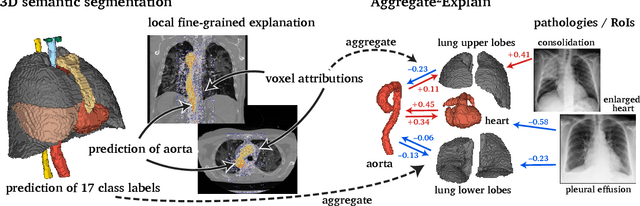
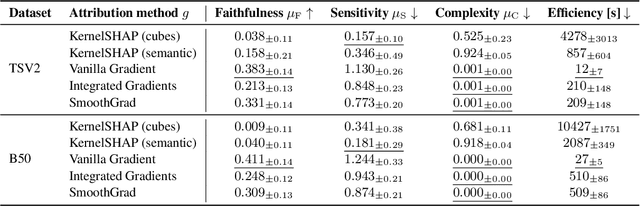
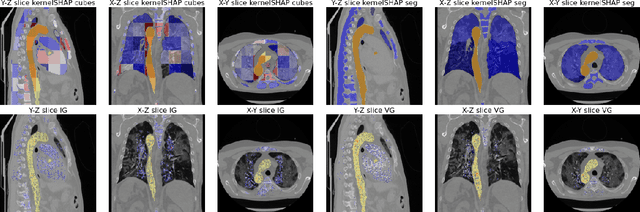
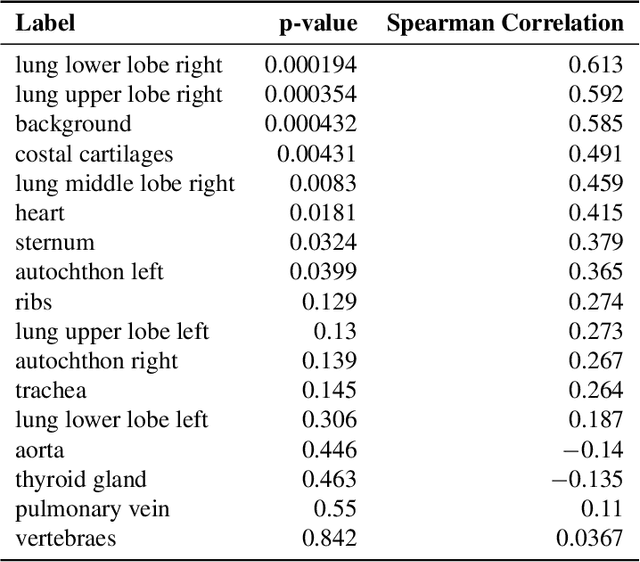
Analysis of 3D segmentation models, especially in the context of medical imaging, is often limited to segmentation performance metrics that overlook the crucial aspect of explainability and bias. Currently, effectively explaining these models with saliency maps is challenging due to the high dimensions of input images multiplied by the ever-growing number of segmented class labels. To this end, we introduce Agg^2Exp, a methodology for aggregating fine-grained voxel attributions of the segmentation model's predictions. Unlike classical explanation methods that primarily focus on the local feature attribution, Agg^2Exp enables a more comprehensive global view on the importance of predicted segments in 3D images. Our benchmarking experiments show that gradient-based voxel attributions are more faithful to the model's predictions than perturbation-based explanations. As a concrete use-case, we apply Agg^2Exp to discover knowledge acquired by the Swin UNEt TRansformer model trained on the TotalSegmentator v2 dataset for segmenting anatomical structures in computed tomography medical images. Agg^2Exp facilitates the explanatory analysis of large segmentation models beyond their predictive performance.
Efficient and Accurate Explanation Estimation with Distribution Compression
Jun 26, 2024Exact computation of various machine learning explanations requires numerous model evaluations and in extreme cases becomes impractical. The computational cost of approximation increases with an ever-increasing size of data and model parameters. Many heuristics have been proposed to approximate post-hoc explanations efficiently. This paper shows that the standard i.i.d. sampling used in a broad spectrum of algorithms for explanation estimation leads to an approximation error worthy of improvement. To this end, we introduce Compress Then Explain (CTE), a new paradigm for more efficient and accurate explanation estimation. CTE uses distribution compression through kernel thinning to obtain a data sample that best approximates the marginal distribution. We show that CTE improves the estimation of removal-based local and global explanations with negligible computational overhead. It often achieves an on-par explanation approximation error using 2-3x less samples, i.e. requiring 2-3x less model evaluations. CTE is a simple, yet powerful, plug-in for any explanation method that now relies on i.i.d. sampling.
On the Robustness of Global Feature Effect Explanations
Jun 13, 2024We study the robustness of global post-hoc explanations for predictive models trained on tabular data. Effects of predictor features in black-box supervised learning are an essential diagnostic tool for model debugging and scientific discovery in applied sciences. However, how vulnerable they are to data and model perturbations remains an open research question. We introduce several theoretical bounds for evaluating the robustness of partial dependence plots and accumulated local effects. Our experimental results with synthetic and real-world datasets quantify the gap between the best and worst-case scenarios of (mis)interpreting machine learning predictions globally.