 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Sybil: Explaining Deep Lung Cancer Risk Prediction Through Generative Interventional Attributions
Jan 30, 2026Lung cancer remains the leading cause of cancer mortality, driving the development of automated screening tools to alleviate radiologist workload. Standing at the frontier of this effort is Sybil, a deep learning model capable of predicting future risk solely from computed tomography (CT) with high precision. However, despite extensive clinical validation, current assessments rely purely on observational metrics. This correlation-based approach overlooks the model's actual reasoning mechanism, necessitating a shift to causal verification to ensure robust decision-making before clinical deployment. We propose S(H)NAP, a model-agnostic auditing framework that constructs generative interventional attributions validated by expert radiologists. By leveraging realistic 3D diffusion bridge modeling to systematically modify anatomical features, our approach isolates object-specific causal contributions to the risk score. Providing the first interventional audit of Sybil, we demonstrate that while the model often exhibits behavior akin to an expert radiologist, differentiating malignant pulmonary nodules from benign ones, it suffers from critical failure modes, including dangerous sensitivity to clinically unjustified artifacts and a distinct radial bias.
Model Science: getting serious about verification, explanation and control of AI systems
Aug 27, 2025The growing adoption of foundation models calls for a paradigm shift from Data Science to Model Science. Unlike data-centric approaches, Model Science places the trained model at the core of analysis, aiming to interact, verify, explain, and control its behavior across diverse operational contexts. This paper introduces a conceptual framework for a new discipline called Model Science, along with the proposal for its four key pillars: Verification, which requires strict, context-aware evaluation protocols; Explanation, which is understood as various approaches to explore of internal model operations; Control, which integrates alignment techniques to steer model behavior; and Interface, which develops interactive and visual explanation tools to improve human calibration and decision-making. The proposed framework aims to guide the development of credible, safe, and human-aligned AI systems.
* 8 pages
Explaining Similarity in Vision-Language Encoders with Weighted Banzhaf Interactions
Aug 07, 2025


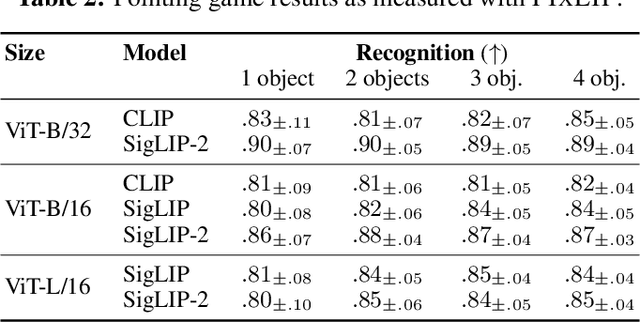
Language-image pre-training (LIP) enables the development of vision-language models capable of zero-shot classification, localization, multimodal retrieval, and semantic understanding. Various explanation methods have been proposed to visualize the importance of input image-text pairs on the model's similarity outputs. However, popular saliency maps are limited by capturing only first-order attributions, overlooking the complex cross-modal interactions intrinsic to such encoders. We introduce faithful interaction explanations of LIP models (FIxLIP) as a unified approach to decomposing the similarity in vision-language encoders. FIxLIP is rooted in game theory, where we analyze how using the weighted Banzhaf interaction index offers greater flexibility and improves computational efficiency over the Shapley interaction quantification framework. From a practical perspective, we propose how to naturally extend explanation evaluation metrics, like the pointing game and area between the insertion/deletion curves, to second-order interaction explanations. Experiments on MS COCO and ImageNet-1k benchmarks validate that second-order methods like FIxLIP outperform first-order attribution methods. Beyond delivering high-quality explanations, we demonstrate the utility of FIxLIP in comparing different models like CLIP vs. SigLIP-2 and ViT-B/32 vs. ViT-L/16.
Birds look like cars: Adversarial analysis of intrinsically interpretable deep learning
Mar 11, 2025A common belief is that intrinsically interpretable deep learning models ensure a correct, intuitive understanding of their behavior and offer greater robustness against accidental errors or intentional manipulation. However, these beliefs have not been comprehensively verified, and growing evidence casts doubt on them. In this paper, we highlight the risks related to overreliance and susceptibility to adversarial manipulation of these so-called "intrinsically (aka inherently) interpretable" models by design. We introduce two strategies for adversarial analysis with prototype manipulation and backdoor attacks against prototype-based networks, and discuss how concept bottleneck models defend against these attacks. Fooling the model's reasoning by exploiting its use of latent prototypes manifests the inherent uninterpretability of deep neural networks, leading to a false sense of security reinforced by a visual confirmation bias. The reported limitations of prototype-based networks put their trustworthiness and applicability into question, motivating further work on the robustness and alignment of (deep) interpretable models.
Interpreting CLIP with Hierarchical Sparse Autoencoders
Feb 27, 2025



Sparse autoencoders (SAEs) are useful for detecting and steering interpretable features in neural networks, with particular potential for understanding complex multimodal representations. Given their ability to uncover interpretable features, SAEs are particularly valuable for analyzing large-scale vision-language models (e.g., CLIP and SigLIP), which are fundamental building blocks in modern systems yet remain challenging to interpret and control. However, current SAE methods are limited by optimizing both reconstruction quality and sparsity simultaneously, as they rely on either activation suppression or rigid sparsity constraints. To this end, we introduce Matryoshka SAE (MSAE), a new architecture that learns hierarchical representations at multiple granularities simultaneously, enabling a direct optimization of both metrics without compromise. MSAE establishes a new state-of-the-art Pareto frontier between reconstruction quality and sparsity for CLIP, achieving 0.99 cosine similarity and less than 0.1 fraction of variance unexplained while maintaining ~80% sparsity. Finally, we demonstrate the utility of MSAE as a tool for interpreting and controlling CLIP by extracting over 120 semantic concepts from its representation to perform concept-based similarity search and bias analysis in downstream tasks like CelebA.
Investigating the Impact of Balancing, Filtering, and Complexity on Predictive Multiplicity: A Data-Centric Perspective
Dec 12, 2024



The Rashomon effect presents a significant challenge in model selection. It occurs when multiple models achieve similar performance on a dataset but produce different predictions, resulting in predictive multiplicity. This is especially problematic in high-stakes environments, where arbitrary model outcomes can have serious consequences. Traditional model selection methods prioritize accuracy and fail to address this issue. Factors such as class imbalance and irrelevant variables further complicate the situation, making it harder for models to provide trustworthy predictions. Data-centric AI approaches can mitigate these problems by prioritizing data optimization, particularly through preprocessing techniques. However, recent studies suggest preprocessing methods may inadvertently inflate predictive multiplicity. This paper investigates how data preprocessing techniques like balancing and filtering methods impact predictive multiplicity and model stability, considering the complexity of the data. We conduct the experiments on 21 real-world datasets, applying various balancing and filtering techniques, and assess the level of predictive multiplicity introduced by these methods by leveraging the Rashomon effect. Additionally, we examine how filtering techniques reduce redundancy and enhance model generalization. The findings provide insights into the relationship between balancing methods, data complexity, and predictive multiplicity, demonstrating how data-centric AI strategies can improve model performance.
Rethinking Visual Counterfactual Explanations Through Region Constraint
Oct 16, 2024



Visual counterfactual explanations (VCEs) have recently gained immense popularity as a tool for clarifying the decision-making process of image classifiers. This trend is largely motivated by what these explanations promise to deliver -- indicate semantically meaningful factors that change the classifier's decision. However, we argue that current state-of-the-art approaches lack a crucial component -- the region constraint -- whose absence prevents from drawing explicit conclusions, and may even lead to faulty reasoning due to phenomenons like confirmation bias. To address the issue of previous methods, which modify images in a very entangled and widely dispersed manner, we propose region-constrained VCEs (RVCEs), which assume that only a predefined image region can be modified to influence the model's prediction. To effectively sample from this subclass of VCEs, we propose Region-Constrained Counterfactual Schr\"odinger Bridges (RCSB), an adaptation of a tractable subclass of Schr\"odinger Bridges to the problem of conditional inpainting, where the conditioning signal originates from the classifier of interest. In addition to setting a new state-of-the-art by a large margin, we extend RCSB to allow for exact counterfactual reasoning, where the predefined region contains only the factor of interest, and incorporating the user to actively interact with the RVCE by predefining the regions manually.
Aggregated Attributions for Explanatory Analysis of 3D Segmentation Models
Jul 24, 2024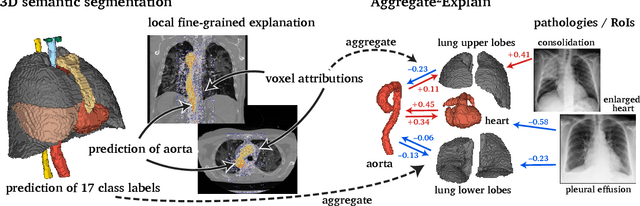
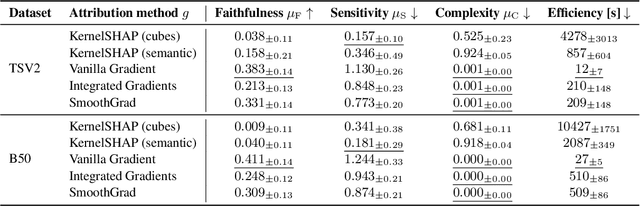
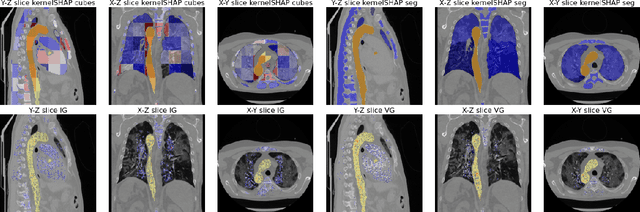
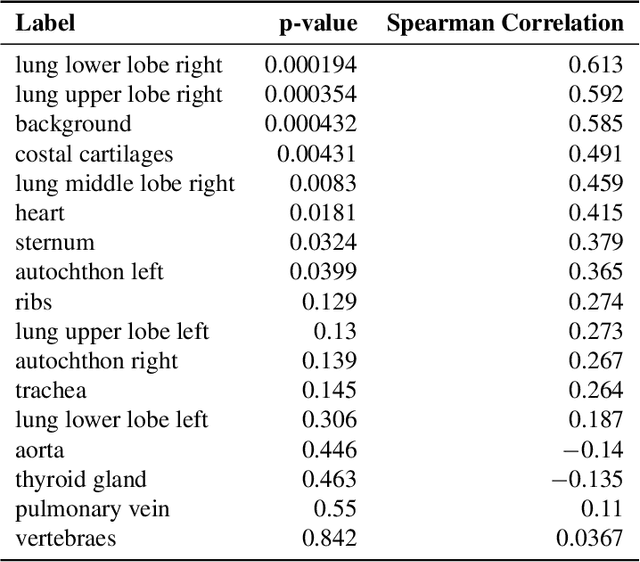
Analysis of 3D segmentation models, especially in the context of medical imaging, is often limited to segmentation performance metrics that overlook the crucial aspect of explainability and bias. Currently, effectively explaining these models with saliency maps is challenging due to the high dimensions of input images multiplied by the ever-growing number of segmented class labels. To this end, we introduce Agg^2Exp, a methodology for aggregating fine-grained voxel attributions of the segmentation model's predictions. Unlike classical explanation methods that primarily focus on the local feature attribution, Agg^2Exp enables a more comprehensive global view on the importance of predicted segments in 3D images. Our benchmarking experiments show that gradient-based voxel attributions are more faithful to the model's predictions than perturbation-based explanations. As a concrete use-case, we apply Agg^2Exp to discover knowledge acquired by the Swin UNEt TRansformer model trained on the TotalSegmentator v2 dataset for segmenting anatomical structures in computed tomography medical images. Agg^2Exp facilitates the explanatory analysis of large segmentation models beyond their predictive performance.
Swin SMT: Global Sequential Modeling in 3D Medical Image Segmentation
Jul 10, 2024Recent advances in Vision Transformers (ViTs) have significantly enhanced medical image segmentation by facilitating the learning of global relationships. However, these methods face a notable challenge in capturing diverse local and global long-range sequential feature representations, particularly evident in whole-body CT (WBCT) scans. To overcome this limitation, we introduce Swin Soft Mixture Transformer (Swin SMT), a novel architecture based on Swin UNETR. This model incorporates a Soft Mixture-of-Experts (Soft MoE) to effectively handle complex and diverse long-range dependencies. The use of Soft MoE allows for scaling up model parameters maintaining a balance between computational complexity and segmentation performance in both training and inference modes. We evaluate Swin SMT on the publicly available TotalSegmentator-V2 dataset, which includes 117 major anatomical structures in WBCT images. Comprehensive experimental results demonstrate that Swin SMT outperforms several state-of-the-art methods in 3D anatomical structure segmentation, achieving an average Dice Similarity Coefficient of 85.09%. The code and pre-trained weights of Swin SMT are publicly available at https://github.com/MI2DataLab/SwinSMT.
Efficient and Accurate Explanation Estimation with Distribution Compression
Jun 26, 2024Exact computation of various machine learning explanations requires numerous model evaluations and in extreme cases becomes impractical. The computational cost of approximation increases with an ever-increasing size of data and model parameters. Many heuristics have been proposed to approximate post-hoc explanations efficiently. This paper shows that the standard i.i.d. sampling used in a broad spectrum of algorithms for explanation estimation leads to an approximation error worthy of improvement. To this end, we introduce Compress Then Explain (CTE), a new paradigm for more efficient and accurate explanation estimation. CTE uses distribution compression through kernel thinning to obtain a data sample that best approximates the marginal distribution. We show that CTE improves the estimation of removal-based local and global explanations with negligible computational overhead. It often achieves an on-par explanation approximation error using 2-3x less samples, i.e. requiring 2-3x less model evaluations. CTE is a simple, yet powerful, plug-in for any explanation method that now relies on i.i.d. sampling.