 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba Goes HoME: Hierarchical Soft Mixture-of-Experts for 3D Medical Image Segmentation
Jul 08, 2025



In recent years, artificial intelligence has significantly advanced medical image segmentation. However, challenges remain, including efficient 3D medical image processing across diverse modalities and handling data variability. In this work, we introduce Hierarchical Soft Mixture-of-Experts (HoME), a two-level token-routing layer for efficient long-context modeling, specifically designed for 3D medical image segmentation. Built on the Mamba state-space model (SSM) backbone, HoME enhances sequential modeling through sparse, adaptive expert routing. The first stage employs a Soft Mixture-of-Experts (SMoE) layer to partition input sequences into local groups, routing tokens to specialized per-group experts for localized feature extraction. The second stage aggregates these outputs via a global SMoE layer, enabling cross-group information fusion and global context refinement. This hierarchical design, combining local expert routing with global expert refinement improves generalizability and segmentation performance, surpassing state-of-the-art results across datasets from the three most commonly used 3D medical imaging modalities and data quality.
Aggregated Attributions for Explanatory Analysis of 3D Segmentation Models
Jul 24, 2024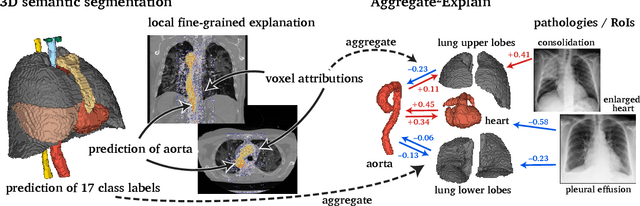
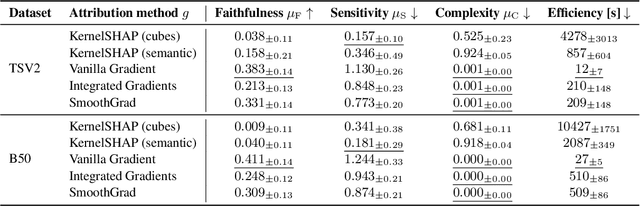
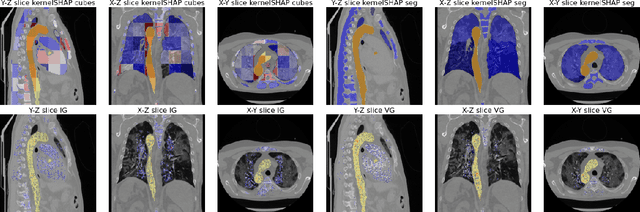
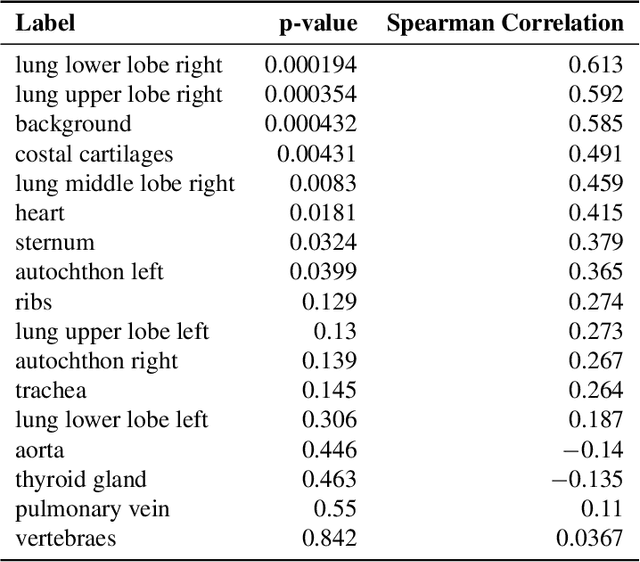
Analysis of 3D segmentation models, especially in the context of medical imaging, is often limited to segmentation performance metrics that overlook the crucial aspect of explainability and bias. Currently, effectively explaining these models with saliency maps is challenging due to the high dimensions of input images multiplied by the ever-growing number of segmented class labels. To this end, we introduce Agg^2Exp, a methodology for aggregating fine-grained voxel attributions of the segmentation model's predictions. Unlike classical explanation methods that primarily focus on the local feature attribution, Agg^2Exp enables a more comprehensive global view on the importance of predicted segments in 3D images. Our benchmarking experiments show that gradient-based voxel attributions are more faithful to the model's predictions than perturbation-based explanations. As a concrete use-case, we apply Agg^2Exp to discover knowledge acquired by the Swin UNEt TRansformer model trained on the TotalSegmentator v2 dataset for segmenting anatomical structures in computed tomography medical images. Agg^2Exp facilitates the explanatory analysis of large segmentation models beyond their predictive performance.
Swin SMT: Global Sequential Modeling in 3D Medical Image Segmentation
Jul 10, 2024Recent advances in Vision Transformers (ViTs) have significantly enhanced medical image segmentation by facilitating the learning of global relationships. However, these methods face a notable challenge in capturing diverse local and global long-range sequential feature representations, particularly evident in whole-body CT (WBCT) scans. To overcome this limitation, we introduce Swin Soft Mixture Transformer (Swin SMT), a novel architecture based on Swin UNETR. This model incorporates a Soft Mixture-of-Experts (Soft MoE) to effectively handle complex and diverse long-range dependencies. The use of Soft MoE allows for scaling up model parameters maintaining a balance between computational complexity and segmentation performance in both training and inference modes. We evaluate Swin SMT on the publicly available TotalSegmentator-V2 dataset, which includes 117 major anatomical structures in WBCT images. Comprehensive experimental results demonstrate that Swin SMT outperforms several state-of-the-art methods in 3D anatomical structure segmentation, achieving an average Dice Similarity Coefficient of 85.09%. The code and pre-trained weights of Swin SMT are publicly available at https://github.com/MI2DataLab/SwinSMT.
Be Careful When Evaluating Explanations Regarding Ground Truth
Nov 08, 2023



Evaluating explanations of image classifiers regarding ground truth, e.g. segmentation masks defined by human perception, primarily evaluates the quality of the models under consideration rather than the explanation methods themselves. Driven by this observation, we propose a framework for $\textit{jointly}$ evaluating the robustness of safety-critical systems that $\textit{combine}$ a deep neural network with an explanation method. These are increasingly used in real-world applications like medical image analysis or robotics. We introduce a fine-tuning procedure to (mis)align model$\unicode{x2013}$explanation pipelines with ground truth and use it to quantify the potential discrepancy between worst and best-case scenarios of human alignment. Experiments across various model architectures and post-hoc local interpretation methods provide insights into the robustness of vision transformers and the overall vulnerability of such AI systems to potential adversarial attacks.