 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee More, Change Less: Anatomy-Aware Diffusion for Contrast Enhancement
Dec 08, 2025Image enhancement improves visual quality and helps reveal details that are hard to see in the original image. In medical imaging, it can support clinical decision-making, but current models often over-edit. This can distort organs, create false findings, and miss small tumors because these models do not understand anatomy or contrast dynamics. We propose SMILE, an anatomy-aware diffusion model that learns how organs are shaped and how they take up contrast. It enhances only clinically relevant regions while leaving all other areas unchanged. SMILE introduces three key ideas: (1) structure-aware supervision that follows true organ boundaries and contrast patterns; (2) registration-free learning that works directly with unaligned multi-phase CT scans; (3) unified inference that provides fast and consistent enhancement across all contrast phases. Across six external datasets, SMILE outperforms existing methods in image quality (14.2% higher SSIM, 20.6% higher PSNR, 50% better FID) and in clinical usefulness by producing anatomically accurate and diagnostically meaningful images. SMILE also improves cancer detection from non-contrast CT, raising the F1 score by up to 10 percent.
GEPAR3D: Geometry Prior-Assisted Learning for 3D Tooth Segmentation
Jul 31, 2025Tooth segmentation in Cone-Beam Computed Tomography (CBCT) remains challenging, especially for fine structures like root apices, which is critical for assessing root resorption in orthodontics. We introduce GEPAR3D, a novel approach that unifies instance detection and multi-class segmentation into a single step tailored to improve root segmentation. Our method integrates a Statistical Shape Model of dentition as a geometric prior, capturing anatomical context and morphological consistency without enforcing restrictive adjacency constraints. We leverage a deep watershed method, modeling each tooth as a continuous 3D energy basin encoding voxel distances to boundaries. This instance-aware representation ensures accurate segmentation of narrow, complex root apices. Trained on publicly available CBCT scans from a single center, our method is evaluated on external test sets from two in-house and two public medical centers. GEPAR3D achieves the highest overall segmentation performance, averaging a Dice Similarity Coefficient (DSC) of 95.0% (+2.8% over the second-best method) and increasing recall to 95.2% (+9.5%) across all test sets. Qualitative analyses demonstrated substantial improvements in root segmentation quality, indicating significant potential for more accurate root resorption assessment and enhanced clinical decision-making in orthodontics. We provide the implementation and dataset at https://github.com/tomek1911/GEPAR3D.
Mamba Goes HoME: Hierarchical Soft Mixture-of-Experts for 3D Medical Image Segmentation
Jul 08, 2025In recent years, artificial intelligence has significantly advanced medical image segmentation. However, challenges remain, including efficient 3D medical image processing across diverse modalities and handling data variability. In this work, we introduce Hierarchical Soft Mixture-of-Experts (HoME), a two-level token-routing layer for efficient long-context modeling, specifically designed for 3D medical image segmentation. Built on the Mamba state-space model (SSM) backbone, HoME enhances sequential modeling through sparse, adaptive expert routing. The first stage employs a Soft Mixture-of-Experts (SMoE) layer to partition input sequences into local groups, routing tokens to specialized per-group experts for localized feature extraction. The second stage aggregates these outputs via a global SMoE layer, enabling cross-group information fusion and global context refinement. This hierarchical design, combining local expert routing with global expert refinement improves generalizability and segmentation performance, surpassing state-of-the-art results across datasets from the three most commonly used 3D medical imaging modalities and data quality.
Benchmark of Segmentation Techniques for Pelvic Fracture in CT and X-ray: Summary of the PENGWIN 2024 Challenge
Apr 03, 2025The segmentation of pelvic fracture fragments in CT and X-ray images is crucial for trauma diagnosis, surgical planning, and intraoperative guidance. However, accurately and efficiently delineating the bone fragments remains a significant challenge due to complex anatomy and imaging limitations. The PENGWIN challenge, organized as a MICCAI 2024 satellite event, aimed to advance automated fracture segmentation by benchmarking state-of-the-art algorithms on these complex tasks. A diverse dataset of 150 CT scans was collected from multiple clinical centers, and a large set of simulated X-ray images was generated using the DeepDRR method. Final submissions from 16 teams worldwide were evaluated under a rigorous multi-metric testing scheme. The top-performing CT algorithm achieved an average fragment-wise intersection over union (IoU) of 0.930, demonstrating satisfactory accuracy. However, in the X-ray task, the best algorithm attained an IoU of 0.774, highlighting the greater challenges posed by overlapping anatomical structures. Beyond the quantitative evaluation, the challenge revealed methodological diversity in algorithm design. Variations in instance representation, such as primary-secondary classification versus boundary-core separation, led to differing segmentation strategies. Despite promising results, the challenge also exposed inherent uncertainties in fragment definition, particularly in cases of incomplete fractures. These findings suggest that interactive segmentation approaches, integrating human decision-making with task-relevant information, may be essential for improving model reliability and clinical applicability.
SimuScope: Realistic Endoscopic Synthetic Dataset Generation through Surgical Simulation and Diffusion Models
Dec 03, 2024



Computer-assisted surgical (CAS) systems enhance surgical execution and outcomes by providing advanced support to surgeons. These systems often rely on deep learning models trained on complex, challenging-to-annotate data. While synthetic data generation can address these challenges, enhancing the realism of such data is crucial. This work introduces a multi-stage pipeline for generating realistic synthetic data, featuring a fully-fledged surgical simulator that automatically produces all necessary annotations for modern CAS systems. This simulator generates a wide set of annotations that surpass those available in public synthetic datasets. Additionally, it offers a more complex and realistic simulation of surgical interactions, including the dynamics between surgical instruments and deformable anatomical environments, outperforming existing approaches. To further bridge the visual gap between synthetic and real data, we propose a lightweight and flexible image-to-image translation method based on Stable Diffusion (SD) and Low-Rank Adaptation (LoRA). This method leverages a limited amount of annotated data, enables efficient training, and maintains the integrity of annotations generated by our simulator. The proposed pipeline is experimentally validated and can translate synthetic images into images with real-world characteristics, which can generalize to real-world context, thereby improving both training and CAS guidance. The code and the dataset are available at https://github.com/SanoScience/SimuScope.
PitVis-2023 Challenge: Workflow Recognition in videos of Endoscopic Pituitary Surgery
Sep 02, 2024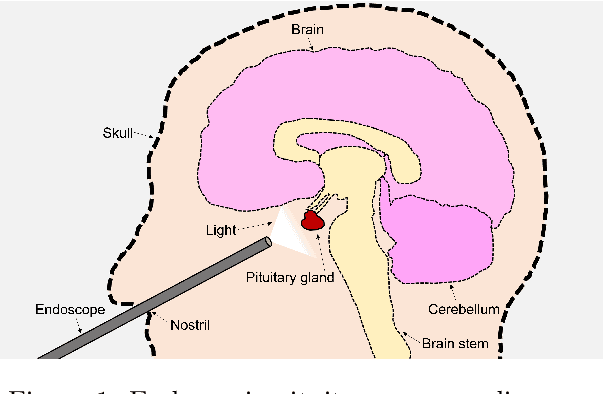

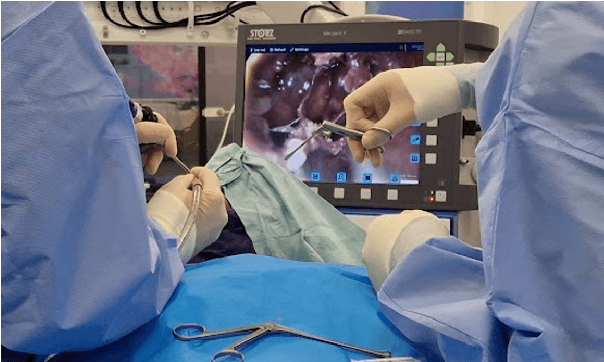
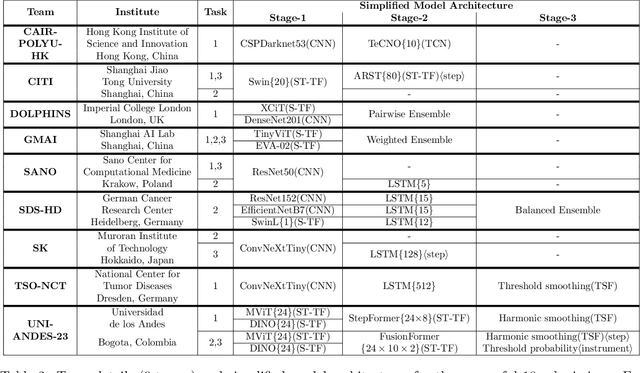
The field of computer vision applied to videos of minimally invasive surgery is ever-growing. Workflow recognition pertains to the automated recognition of various aspects of a surgery: including which surgical steps are performed; and which surgical instruments are used. This information can later be used to assist clinicians when learning the surgery; during live surgery; and when writing operation notes. The Pituitary Vision (PitVis) 2023 Challenge tasks the community to step and instrument recognition in videos of endoscopic pituitary surgery. This is a unique task when compared to other minimally invasive surgeries due to the smaller working space, which limits and distorts vision; and higher frequency of instrument and step switching, which requires more precise model predictions. Participants were provided with 25-videos, with results presented at the MICCAI-2023 conference as part of the Endoscopic Vision 2023 Challenge in Vancouver, Canada, on 08-Oct-2023. There were 18-submissions from 9-teams across 6-countries, using a variety of deep learning models. A commonality between the top performing models was incorporating spatio-temporal and multi-task methods, with greater than 50% and 10% macro-F1-score improvement over purely spacial single-task models in step and instrument recognition respectively. The PitVis-2023 Challenge therefore demonstrates state-of-the-art computer vision models in minimally invasive surgery are transferable to a new dataset, with surgery specific techniques used to enhance performance, progressing the field further. Benchmark results are provided in the paper, and the dataset is publicly available at: https://doi.org/10.5522/04/26531686.
Aggregated Attributions for Explanatory Analysis of 3D Segmentation Models
Jul 24, 2024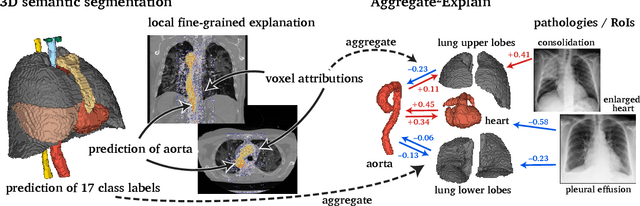
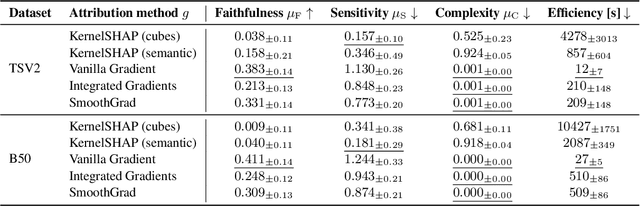
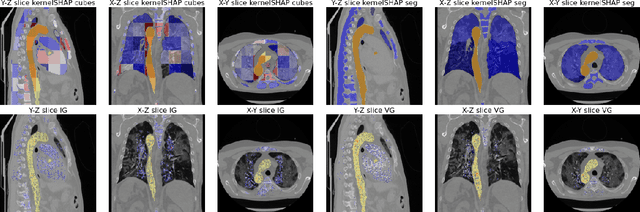
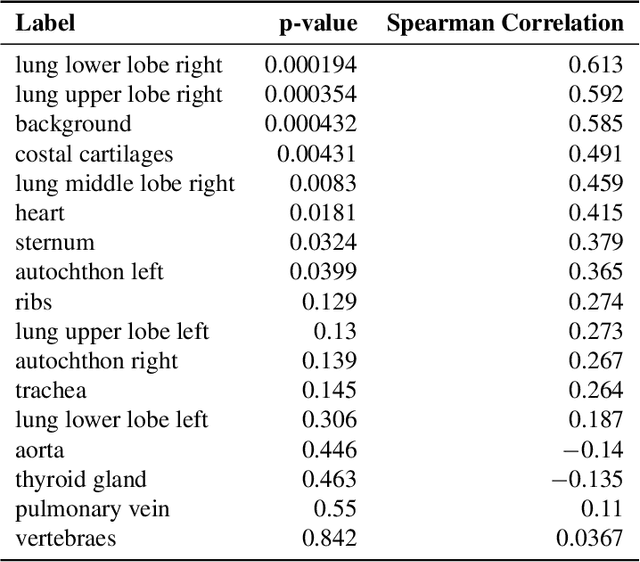
Analysis of 3D segmentation models, especially in the context of medical imaging, is often limited to segmentation performance metrics that overlook the crucial aspect of explainability and bias. Currently, effectively explaining these models with saliency maps is challenging due to the high dimensions of input images multiplied by the ever-growing number of segmented class labels. To this end, we introduce Agg^2Exp, a methodology for aggregating fine-grained voxel attributions of the segmentation model's predictions. Unlike classical explanation methods that primarily focus on the local feature attribution, Agg^2Exp enables a more comprehensive global view on the importance of predicted segments in 3D images. Our benchmarking experiments show that gradient-based voxel attributions are more faithful to the model's predictions than perturbation-based explanations. As a concrete use-case, we apply Agg^2Exp to discover knowledge acquired by the Swin UNEt TRansformer model trained on the TotalSegmentator v2 dataset for segmenting anatomical structures in computed tomography medical images. Agg^2Exp facilitates the explanatory analysis of large segmentation models beyond their predictive performance.
Let Me DeCode You: Decoder Conditioning with Tabular Data
Jul 12, 2024



Training deep neural networks for 3D segmentation tasks can be challenging, often requiring efficient and effective strategies to improve model performance. In this study, we introduce a novel approach, DeCode, that utilizes label-derived features for model conditioning to support the decoder in the reconstruction process dynamically, aiming to enhance the efficiency of the training process. DeCode focuses on improving 3D segmentation performance through the incorporation of conditioning embedding with learned numerical representation of 3D-label shape features. Specifically, we develop an approach, where conditioning is applied during the training phase to guide the network toward robust segmentation. When labels are not available during inference, our model infers the necessary conditioning embedding directly from the input data, thanks to a feed-forward network learned during the training phase. This approach is tested using synthetic data and cone-beam computed tomography (CBCT) images of teeth. For CBCT, three datasets are used: one publicly available and two in-house. Our results show that DeCode significantly outperforms traditional, unconditioned models in terms of generalization to unseen data, achieving higher accuracy at a reduced computational cost. This work represents the first of its kind to explore conditioning strategies in 3D data segmentation, offering a novel and more efficient method for leveraging annotated data. Our code, pre-trained models are publicly available at https://github.com/SanoScience/DeCode .
Swin SMT: Global Sequential Modeling in 3D Medical Image Segmentation
Jul 10, 2024Recent advances in Vision Transformers (ViTs) have significantly enhanced medical image segmentation by facilitating the learning of global relationships. However, these methods face a notable challenge in capturing diverse local and global long-range sequential feature representations, particularly evident in whole-body CT (WBCT) scans. To overcome this limitation, we introduce Swin Soft Mixture Transformer (Swin SMT), a novel architecture based on Swin UNETR. This model incorporates a Soft Mixture-of-Experts (Soft MoE) to effectively handle complex and diverse long-range dependencies. The use of Soft MoE allows for scaling up model parameters maintaining a balance between computational complexity and segmentation performance in both training and inference modes. We evaluate Swin SMT on the publicly available TotalSegmentator-V2 dataset, which includes 117 major anatomical structures in WBCT images. Comprehensive experimental results demonstrate that Swin SMT outperforms several state-of-the-art methods in 3D anatomical structure segmentation, achieving an average Dice Similarity Coefficient of 85.09%. The code and pre-trained weights of Swin SMT are publicly available at https://github.com/MI2DataLab/SwinSMT.
Underestimation of lung regions on chest X-ray segmentation masks assessed by comparison with total lung volume evaluated on computed tomography
Feb 18, 2024
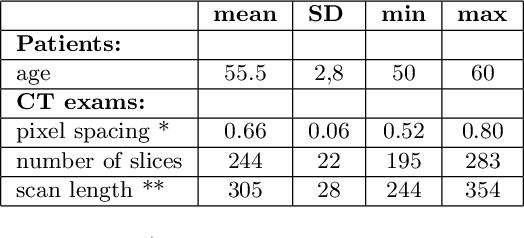
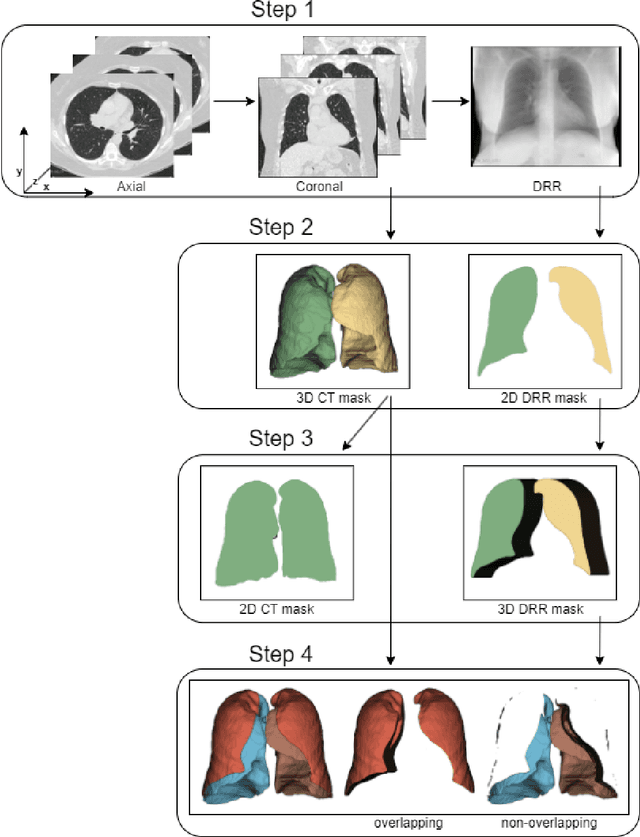
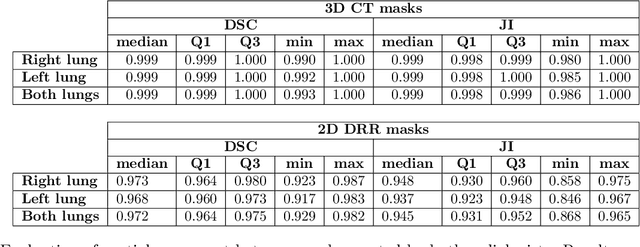
Lung mask creation lacks well-defined criteria and standardized guidelines, leading to a high degree of subjectivity between annotators. In this study, we assess the underestimation of lung regions on chest X-ray segmentation masks created according to the current state-of-the-art method, by comparison with total lung volume evaluated on computed tomography (CT). We show, that lung X-ray masks created by following the contours of the heart, mediastinum, and diaphragm significantly underestimate lung regions and exclude substantial portions of the lungs from further assessment, which may result in numerous clinical errors.