 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitVis-2023 Challenge: Workflow Recognition in videos of Endoscopic Pituitary Surgery
Sep 02, 2024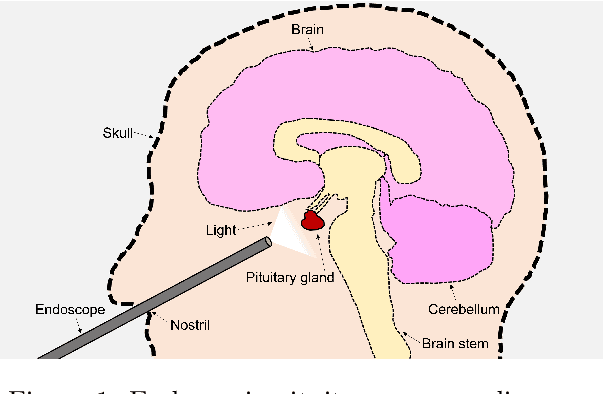

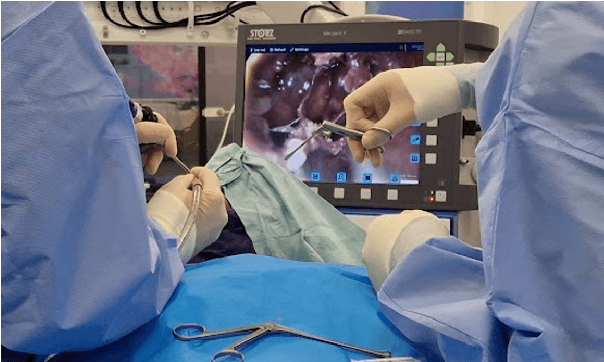
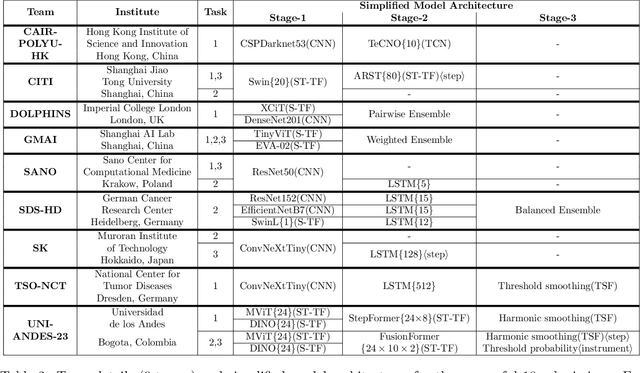
The field of computer vision applied to videos of minimally invasive surgery is ever-growing. Workflow recognition pertains to the automated recognition of various aspects of a surgery: including which surgical steps are performed; and which surgical instruments are used. This information can later be used to assist clinicians when learning the surgery; during live surgery; and when writing operation notes. The Pituitary Vision (PitVis) 2023 Challenge tasks the community to step and instrument recognition in videos of endoscopic pituitary surgery. This is a unique task when compared to other minimally invasive surgeries due to the smaller working space, which limits and distorts vision; and higher frequency of instrument and step switching, which requires more precise model predictions. Participants were provided with 25-videos, with results presented at the MICCAI-2023 conference as part of the Endoscopic Vision 2023 Challenge in Vancouver, Canada, on 08-Oct-2023. There were 18-submissions from 9-teams across 6-countries, using a variety of deep learning models. A commonality between the top performing models was incorporating spatio-temporal and multi-task methods, with greater than 50% and 10% macro-F1-score improvement over purely spacial single-task models in step and instrument recognition respectively. The PitVis-2023 Challenge therefore demonstrates state-of-the-art computer vision models in minimally invasive surgery are transferable to a new dataset, with surgery specific techniques used to enhance performance, progressing the field further. Benchmark results are provided in the paper, and the dataset is publicly available at: https://doi.org/10.5522/04/26531686.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023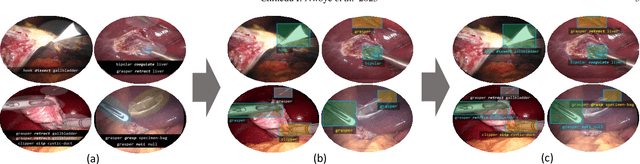
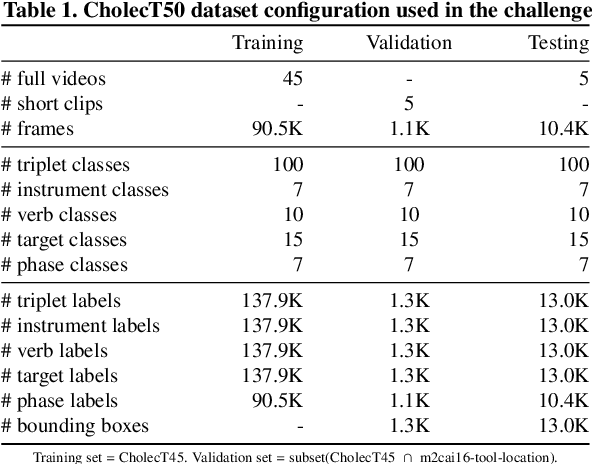
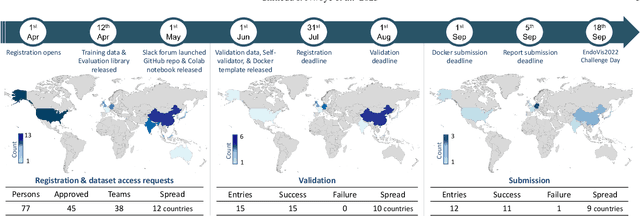
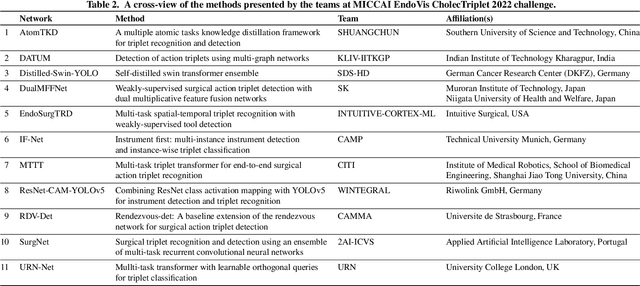
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
ARST: Auto-Regressive Surgical Transformer for Phase Recognition from Laparoscopic Videos
Sep 02, 2022


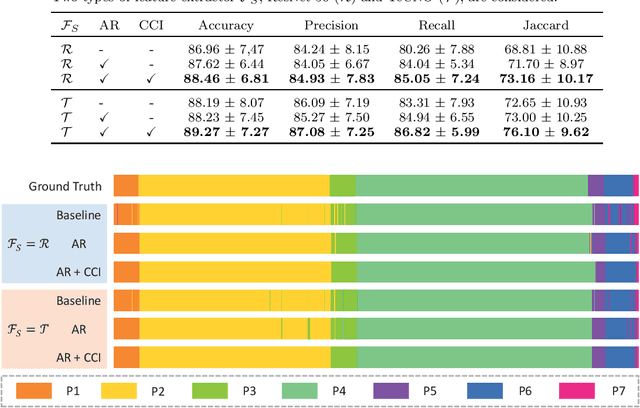
Phase recognition plays an essential role for surgical workflow analysis in computer assisted intervention. Transformer, originally proposed for sequential data modeling in natural language processing, has been successfully applied to surgical phase recognition. Existing works based on transformer mainly focus on modeling attention dependency, without introducing auto-regression. In this work, an Auto-Regressive Surgical Transformer, referred as ARST, is first proposed for on-line surgical phase recognition from laparoscopic videos, modeling the inter-phase correlation implicitly by conditional probability distribution. To reduce inference bias and to enhance phase consistency, we further develop a consistency constraint inference strategy based on auto-regression. We conduct comprehensive validations on a well-known public dataset Cholec80. Experimental results show that our method outperforms the state-of-the-art methods both quantitatively and qualitatively, and achieves an inference rate of 66 frames per second (fps).