 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-center analysis of deep learning methods for video polyp detection and segmentation
Mar 04, 2026Colonic polyps are well-recognized precursors to colorectal cancer (CRC), typically detected during colonoscopy. However, the variability in appearance, location, and size of these polyps complicates their detection and removal, leading to challenges in effective surveillance, intervention, and subsequently CRC prevention. The processes of colonoscopy surveillance and polyp removal are highly reliant on the expertise of gastroenterologists and occur within the complexities of the colonic structure. As a result, there is a high rate of missed detections and incomplete removal of colonic polyps, which can adversely impact patient outcomes. Recently, automated methods that use machine learning have been developed to enhance polyps detection and segmentation, thus helping clinical processes and reducing missed rates. These advancements highlight the potential for improving diagnostic accuracy in real-time applications, which ultimately facilitates more effective patient management. Furthermore, integrating sequence data and temporal information could significantly enhance the precision of these methods by capturing the dynamic nature of polyp growth and the changes that occur over time. To rigorously investigate these challenges, data scientists and experts gastroenterologists collaborated to compile a comprehensive dataset that spans multiple centers and diverse populations. This initiative aims to underscore the critical importance of incorporating sequence data and temporal information in the development of robust automated detection and segmentation methods. This study evaluates the applicability of deep learning techniques developed in real-time clinical colonoscopy tasks using sequence data, highlighting the critical role of temporal relationships between frames in improving diagnostic precision.
Comparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
Challenging Vision-Language Models with Surgical Data: A New Dataset and Broad Benchmarking Study
Jun 06, 2025While traditional computer vision models have historically struggled to generalize to endoscopic domains, the emergence of foundation models has shown promising cross-domain performance. In this work, we present the first large-scale study assessing the capabilities of Vision Language Models (VLMs) for endoscopic tasks with a specific focus on laparoscopic surgery. Using a diverse set of state-of-the-art models, multiple surgical datasets, and extensive human reference annotations, we address three key research questions: (1) Can current VLMs solve basic perception tasks on surgical images? (2) Can they handle advanced frame-based endoscopic scene understanding tasks? and (3) How do specialized medical VLMs compare to generalist models in this context? Our results reveal that VLMs can effectively perform basic surgical perception tasks, such as object counting and localization, with performance levels comparable to general domain tasks. However, their performance deteriorates significantly when the tasks require medical knowledge. Notably, we find that specialized medical VLMs currently underperform compared to generalist models across both basic and advanced surgical tasks, suggesting that they are not yet optimized for the complexity of surgical environments. These findings highlight the need for further advancements to enable VLMs to handle the unique challenges posed by surgery. Overall, our work provides important insights for the development of next-generation endoscopic AI systems and identifies key areas for improvement in medical visual language models.
PitVis-2023 Challenge: Workflow Recognition in videos of Endoscopic Pituitary Surgery
Sep 02, 2024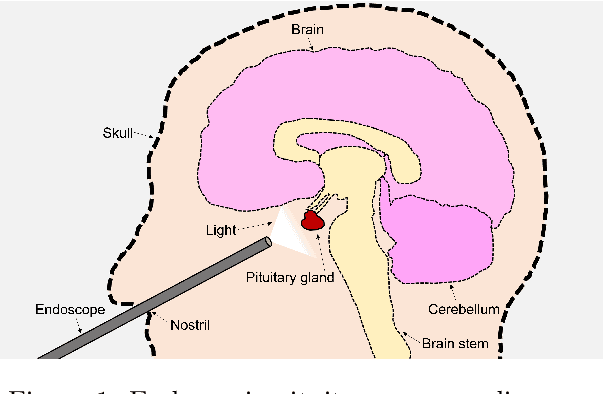

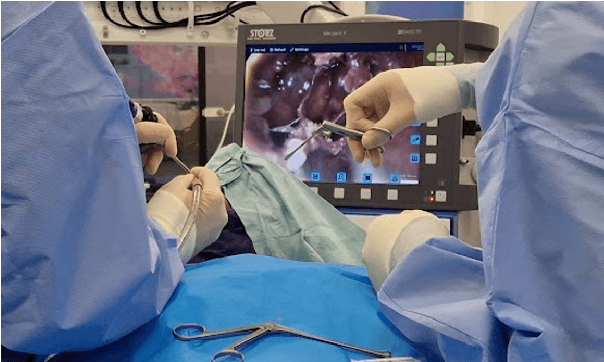
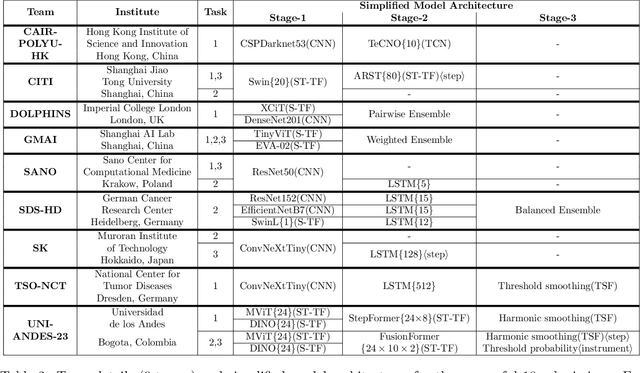
The field of computer vision applied to videos of minimally invasive surgery is ever-growing. Workflow recognition pertains to the automated recognition of various aspects of a surgery: including which surgical steps are performed; and which surgical instruments are used. This information can later be used to assist clinicians when learning the surgery; during live surgery; and when writing operation notes. The Pituitary Vision (PitVis) 2023 Challenge tasks the community to step and instrument recognition in videos of endoscopic pituitary surgery. This is a unique task when compared to other minimally invasive surgeries due to the smaller working space, which limits and distorts vision; and higher frequency of instrument and step switching, which requires more precise model predictions. Participants were provided with 25-videos, with results presented at the MICCAI-2023 conference as part of the Endoscopic Vision 2023 Challenge in Vancouver, Canada, on 08-Oct-2023. There were 18-submissions from 9-teams across 6-countries, using a variety of deep learning models. A commonality between the top performing models was incorporating spatio-temporal and multi-task methods, with greater than 50% and 10% macro-F1-score improvement over purely spacial single-task models in step and instrument recognition respectively. The PitVis-2023 Challenge therefore demonstrates state-of-the-art computer vision models in minimally invasive surgery are transferable to a new dataset, with surgery specific techniques used to enhance performance, progressing the field further. Benchmark results are provided in the paper, and the dataset is publicly available at: https://doi.org/10.5522/04/26531686.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Self-distillation for surgical action recognition
Mar 22, 2023



Surgical scene understanding is a key prerequisite for contextaware decision support in the operating room. While deep learning-based approaches have already reached or even surpassed human performance in various fields, the task of surgical action recognition remains a major challenge. With this contribution, we are the first to investigate the concept of self-distillation as a means of addressing class imbalance and potential label ambiguity in surgical video analysis. Our proposed method is a heterogeneous ensemble of three models that use Swin Transfomers as backbone and the concepts of self-distillation and multi-task learning as core design choices. According to ablation studies performed with the CholecT45 challenge data via cross-validation, the biggest performance boost is achieved by the usage of soft labels obtained by self-distillation. External validation of our method on an independent test set was achieved by providing a Docker container of our inference model to the challenge organizers. According to their analysis, our method outperforms all other solutions submitted to the latest challenge in the field. Our approach thus shows the potential of self-distillation for becoming an important tool in medical image analysis applications.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023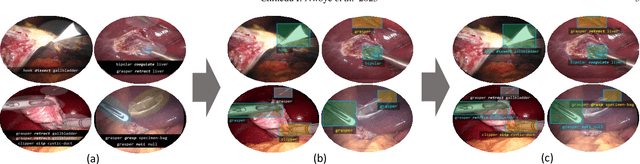
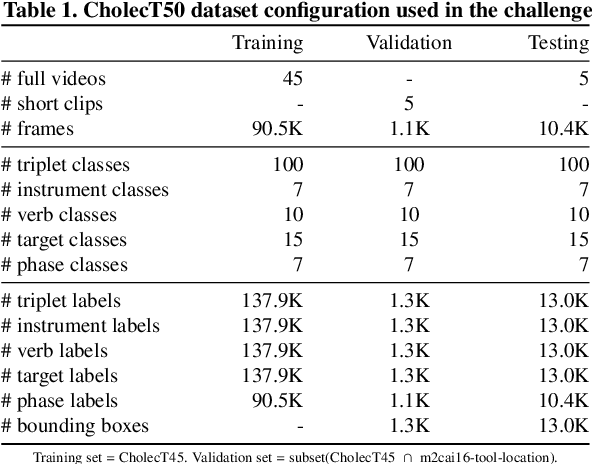
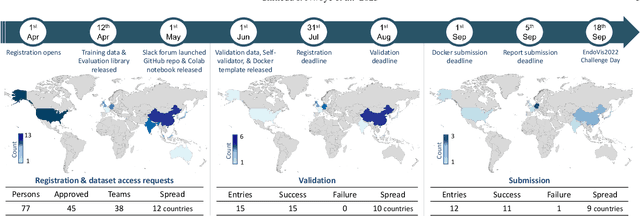
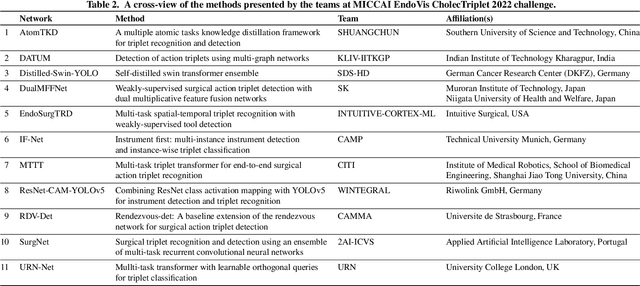
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
Sources of performance variability in deep learning-based polyp detection
Nov 17, 2022Validation metrics are a key prerequisite for the reliable tracking of scientific progress and for deciding on the potential clinical translation of methods. While recent initiatives aim to develop comprehensive theoretical frameworks for understanding metric-related pitfalls in image analysis problems, there is a lack of experimental evidence on the concrete effects of common and rare pitfalls on specific applications. We address this gap in the literature in the context of colon cancer screening. Our contribution is twofold. Firstly, we present the winning solution of the Endoscopy computer vision challenge (EndoCV) on colon cancer detection, conducted in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI) 2022. Secondly, we demonstrate the sensitivity of commonly used metrics to a range of hyperparameters as well as the consequences of poor metric choices. Based on comprehensive validation studies performed with patient data from six clinical centers, we found all commonly applied object detection metrics to be subject to high inter-center variability. Furthermore, our results clearly demonstrate that the adaptation of standard hyperparameters used in the computer vision community does not generally lead to the clinically most plausible results. Finally, we present localization criteria that correspond well to clinical relevance. Our work could be a first step towards reconsidering common validation strategies in automatic colon cancer screening applications.