 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefine-CLIP: Enhancing Zero-Shot Fine-Grained Surgical Action Recognition with Vision-Language Models
Mar 25, 2025



While vision-language models like CLIP have advanced zero-shot surgical phase recognition, they struggle with fine-grained surgical activities, especially action triplets. This limitation arises because current CLIP formulations rely on global image features, which overlook the fine-grained semantics and contextual details crucial for complex tasks like zero-shot triplet recognition. Furthermore, these models do not explore the hierarchical structure inherent in triplets, reducing their ability to generalize to novel triplets. To address these challenges, we propose fine-CLIP, which learns object-centric features and lever- ages the hierarchy in triplet formulation. Our approach integrates three components: hierarchical prompt modeling to capture shared semantics, LoRA-based vision backbone adaptation for enhanced feature extraction, and a graph-based condensation strategy that groups similar patch features into meaningful object clusters. Since triplet classification is a challenging task, we introduce an alternative yet meaningful base-to-novel generalization benchmark with two settings on the CholecT50 dataset: Unseen-Target, assessing adaptability to triplets with novel anatomical structures, and Unseen-Instrument-Verb, where models need to generalize to novel instrument-verb interactions. fine-CLIP shows significant improvements in F1 and mAP, enhancing zero-shot recognition of novel surgical triplets.
Early Operative Difficulty Assessment in Laparoscopic Cholecystectomy via Snapshot-Centric Video Analysis
Feb 10, 2025Purpose: Laparoscopic cholecystectomy (LC) operative difficulty (LCOD) is highly variable and influences outcomes. Despite extensive LC studies in surgical workflow analysis, limited efforts explore LCOD using intraoperative video data. Early recog- nition of LCOD could allow prompt review by expert surgeons, enhance operating room (OR) planning, and improve surgical outcomes. Methods: We propose the clinical task of early LCOD assessment using limited video observations. We design SurgPrOD, a deep learning model to assess LCOD by analyzing features from global and local temporal resolutions (snapshots) of the observed LC video. Also, we propose a novel snapshot-centric attention (SCA) module, acting across snapshots, to enhance LCOD prediction. We introduce the CholeScore dataset, featuring video-level LCOD labels to validate our method. Results: We evaluate SurgPrOD on 3 LCOD assessment scales in the CholeScore dataset. On our new metric assessing early and stable correct predictions, SurgPrOD surpasses baselines by at least 0.22 points. SurgPrOD improves over baselines by at least 9 and 5 percentage points in F1 score and top1-accuracy, respectively, demonstrating its effectiveness in correct predictions. Conclusion: We propose a new task for early LCOD assessment and a novel model, SurgPrOD analyzing surgical video from global and local perspectives. Our results on the CholeScore dataset establishes a new benchmark to study LCOD using intraoperative video data.
Surgical Action Triplet Detection by Mixed Supervised Learning of Instrument-Tissue Interactions
Jul 18, 2023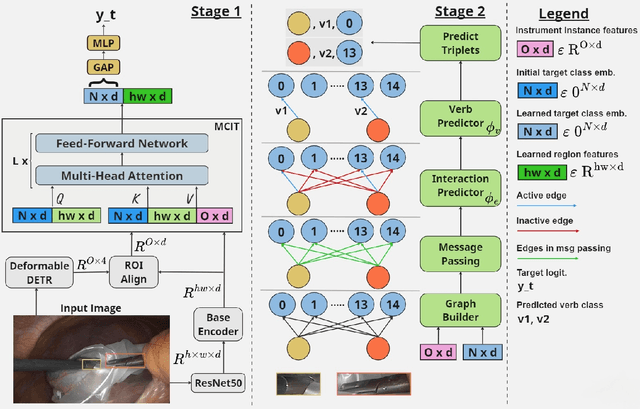

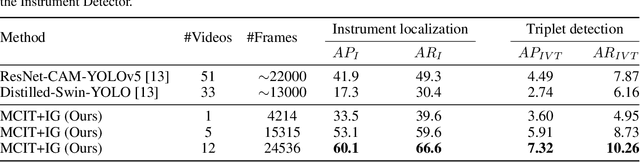

Surgical action triplets describe instrument-tissue interactions as (instrument, verb, target) combinations, thereby supporting a detailed analysis of surgical scene activities and workflow. This work focuses on surgical action triplet detection, which is challenging but more precise than the traditional triplet recognition task as it consists of joint (1) localization of surgical instruments and (2) recognition of the surgical action triplet associated with every localized instrument. Triplet detection is highly complex due to the lack of spatial triplet annotation. We analyze how the amount of instrument spatial annotations affects triplet detection and observe that accurate instrument localization does not guarantee better triplet detection due to the risk of erroneous associations with the verbs and targets. To solve the two tasks, we propose MCIT-IG, a two-stage network, that stands for Multi-Class Instrument-aware Transformer-Interaction Graph. The MCIT stage of our network models per class embedding of the targets as additional features to reduce the risk of misassociating triplets. Furthermore, the IG stage constructs a bipartite dynamic graph to model the interaction between the instruments and targets, cast as the verbs. We utilize a mixed-supervised learning strategy that combines weak target presence labels for MCIT and pseudo triplet labels for IG to train our network. We observed that complementing minimal instrument spatial annotations with target embeddings results in better triplet detection. We evaluate our model on the CholecT50 dataset and show improved performance on both instrument localization and triplet detection, topping the leaderboard of the CholecTriplet challenge in MICCAI 2022.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023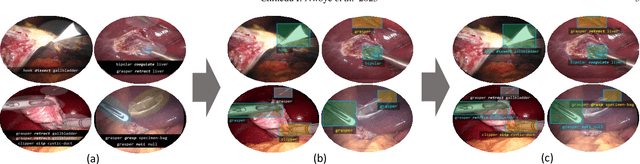
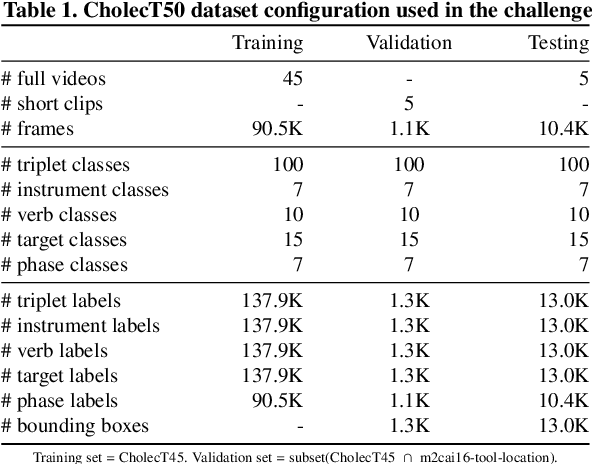
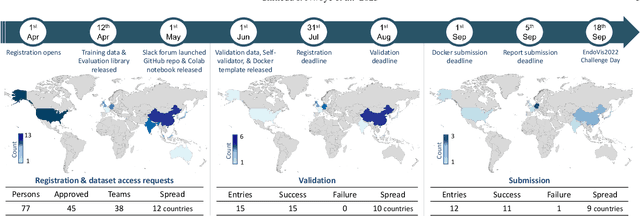
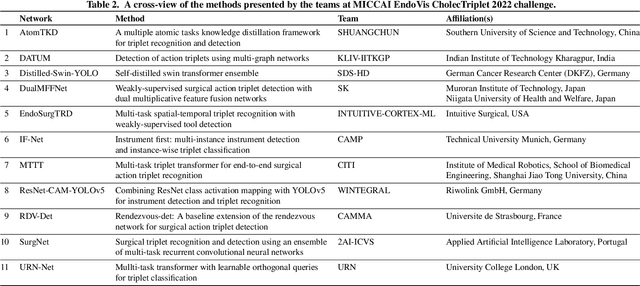
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
Rendezvous in Time: An Attention-based Temporal Fusion approach for Surgical Triplet Recognition
Nov 30, 2022One of the recent advances in surgical AI is the recognition of surgical activities as triplets of (instrument, verb, target). Albeit providing detailed information for computer-assisted intervention, current triplet recognition approaches rely only on single frame features. Exploiting the temporal cues from earlier frames would improve the recognition of surgical action triplets from videos. In this paper, we propose Rendezvous in Time (RiT) - a deep learning model that extends the state-of-the-art model, Rendezvous, with temporal modeling. Focusing more on the verbs, our RiT explores the connectedness of current and past frames to learn temporal attention-based features for enhanced triplet recognition. We validate our proposal on the challenging surgical triplet dataset, CholecT45, demonstrating an improved recognition of the verb and triplet along with other interactions involving the verb such as (instrument, verb). Qualitative results show that the RiT produces smoother predictions for most triplet instances than the state-of-the-arts. We present a novel attention-based approach that leverages the temporal fusion of video frames to model the evolution of surgical actions and exploit their benefits for surgical triplet recognition.
Toyota Smarthome Untrimmed: Real-World Untrimmed Videos for Activity Detection
Oct 28, 2020
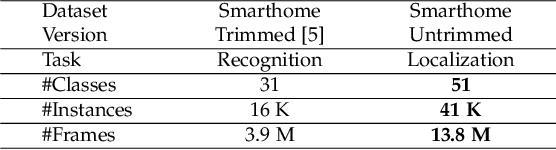

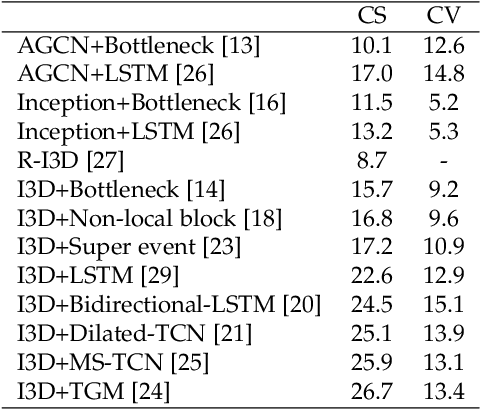
This work aims at building a large scale dataset with daily-living activities performed in a natural manner. Activities performed in a spontaneous manner lead to many real-world challenges that are often ignored by the vision community. This includes low inter-class due to the presence of similar activities and high intra-class variance, low camera framing, low resolution, long-tail distribution of activities, and occlusions. To this end, we propose the Toyota Smarthome Untrimmed (TSU) dataset, which provides spontaneous activities with rich and dense annotations to address the detection of complex activities in real-world scenarios.
VPN: Learning Video-Pose Embedding for Activities of Daily Living
Jul 06, 2020



In this paper, we focus on the spatio-temporal aspect of recognizing Activities of Daily Living (ADL). ADL have two specific properties (i) subtle spatio-temporal patterns and (ii) similar visual patterns varying with time. Therefore, ADL may look very similar and often necessitate to look at their fine-grained details to distinguish them. Because the recent spatio-temporal 3D ConvNets are too rigid to capture the subtle visual patterns across an action, we propose a novel Video-Pose Network: VPN. The 2 key components of this VPN are a spatial embedding and an attention network. The spatial embedding projects the 3D poses and RGB cues in a common semantic space. This enables the action recognition framework to learn better spatio-temporal features exploiting both modalities. In order to discriminate similar actions, the attention network provides two functionalities - (i) an end-to-end learnable pose backbone exploiting the topology of human body, and (ii) a coupler to provide joint spatio-temporal attention weights across a video. Experiments show that VPN outperforms the state-of-the-art results for action classification on a large scale human activity dataset: NTU-RGB+D 120, its subset NTU-RGB+D 60, a real-world challenging human activity dataset: Toyota Smarthome and a small scale human-object interaction dataset Northwestern UCLA.