 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeD: Context-Aware Diffusion for Accurate 3D Gaze Estimation
Jan 19, 2026We introduce GazeD, a new 3D gaze estimation method that jointly provides 3D gaze and human pose from a single RGB image. Leveraging the ability of diffusion models to deal with uncertainty, it generates multiple plausible 3D gaze and pose hypotheses based on the 2D context information extracted from the input image. Specifically, we condition the denoising process on the 2D pose, the surroundings of the subject, and the context of the scene. With GazeD we also introduce a novel way of representing the 3D gaze by positioning it as an additional body joint at a fixed distance from the eyes. The rationale is that the gaze is usually closely related to the pose, and thus it can benefit from being jointly denoised during the diffusion process. Evaluations across three benchmark datasets demonstrate that GazeD achieves state-of-the-art performance in 3D gaze estimation, even surpassing methods that rely on temporal information. Project details will be available at https://aimagelab.ing.unimore.it/go/gazed.
Language-Based Swarm Perception: Decentralized Person Re-Identification via Natural Language Descriptions
Jan 18, 2026We introduce a method for decentralized person re-identification in robot swarms that leverages natural language as the primary representational modality. Unlike traditional approaches that rely on opaque visual embeddings -- high-dimensional feature vectors extracted from images -- the proposed method uses human-readable language to represent observations. Each robot locally detects and describes individuals using a vision-language model (VLM), producing textual descriptions of appearance instead of feature vectors. These descriptions are compared and clustered across the swarm without centralized coordination, allowing robots to collaboratively group observations of the same individual. Each cluster is distilled into a representative description by a language model, providing an interpretable, concise summary of the swarm's collective perception. This approach enables natural-language querying, enhances transparency, and supports explainable swarm behavior. Preliminary experiments demonstrate competitive performance in identity consistency and interpretability compared to embedding-based methods, despite current limitations in text similarity and computational load. Ongoing work explores refined similarity metrics, semantic navigation, and the extension of language-based perception to environmental elements. This work prioritizes decentralized perception and communication, while active navigation remains an open direction for future study.
Mixture of Experts Guided by Gaussian Splatters Matters: A new Approach to Weakly-Supervised Video Anomaly Detection
Aug 08, 2025Video Anomaly Detection (VAD) is a challenging task due to the variability of anomalous events and the limited availability of labeled data. Under the Weakly-Supervised VAD (WSVAD) paradigm, only video-level labels are provided during training, while predictions are made at the frame level. Although state-of-the-art models perform well on simple anomalies (e.g., explosions), they struggle with complex real-world events (e.g., shoplifting). This difficulty stems from two key issues: (1) the inability of current models to address the diversity of anomaly types, as they process all categories with a shared model, overlooking category-specific features; and (2) the weak supervision signal, which lacks precise temporal information, limiting the ability to capture nuanced anomalous patterns blended with normal events. To address these challenges, we propose Gaussian Splatting-guided Mixture of Experts (GS-MoE), a novel framework that employs a set of expert models, each specialized in capturing specific anomaly types. These experts are guided by a temporal Gaussian splatting loss, enabling the model to leverage temporal consistency and enhance weak supervision. The Gaussian splatting approach encourages a more precise and comprehensive representation of anomalies by focusing on temporal segments most likely to contain abnormal events. The predictions from these specialized experts are integrated through a mixture-of-experts mechanism to model complex relationships across diverse anomaly patterns. Our approach achieves state-of-the-art performance, with a 91.58% AUC on the UCF-Crime dataset, and demonstrates superior results on XD-Violence and MSAD datasets. By leveraging category-specific expertise and temporal guidance, GS-MoE sets a new benchmark for VAD under weak supervision.
Just Dance with $π$! A Poly-modal Inductor for Weakly-supervised Video Anomaly Detection
May 19, 2025Weakly-supervised methods for video anomaly detection (VAD) are conventionally based merely on RGB spatio-temporal features, which continues to limit their reliability in real-world scenarios. This is due to the fact that RGB-features are not sufficiently distinctive in setting apart categories such as shoplifting from visually similar events. Therefore, towards robust complex real-world VAD, it is essential to augment RGB spatio-temporal features by additional modalities. Motivated by this, we introduce the Poly-modal Induced framework for VAD: "PI-VAD", a novel approach that augments RGB representations by five additional modalities. Specifically, the modalities include sensitivity to fine-grained motion (Pose), three dimensional scene and entity representation (Depth), surrounding objects (Panoptic masks), global motion (optical flow), as well as language cues (VLM). Each modality represents an axis of a polygon, streamlined to add salient cues to RGB. PI-VAD includes two plug-in modules, namely Pseudo-modality Generation module and Cross Modal Induction module, which generate modality-specific prototypical representation and, thereby, induce multi-modal information into RGB cues. These modules operate by performing anomaly-aware auxiliary tasks and necessitate five modality backbones -- only during training. Notably, PI-VAD achieves state-of-the-art accuracy on three prominent VAD datasets encompassing real-world scenarios, without requiring the computational overhead of five modality backbones at inference.
Collective perception for tracking people with a robot swarm
Oct 09, 2024
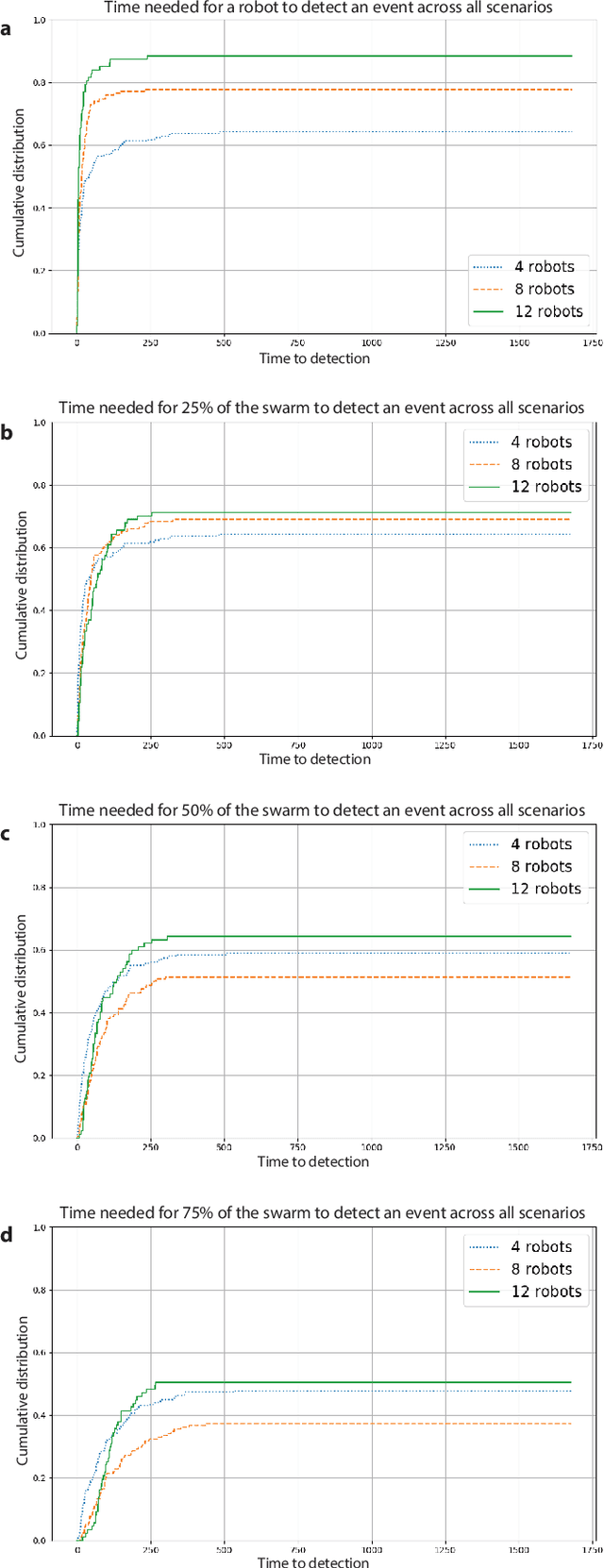
Swarm perception refers to the ability of a robot swarm to utilize the perception capabilities of each individual robot, forming a collective understanding of the environment. Their distributed nature enables robot swarms to continuously monitor dynamic environments by maintaining a constant presence throughout the space.In this study, we present a preliminary experiment on the collective tracking of people using a robot swarm. The experiment was conducted in simulation across four different office environments, with swarms of varying sizes. The robots were provided with images sampled from a dataset of real-world office environment pictures.We measured the time distribution required for a robot to detect a person changing location and to propagate this information to increasing fractions of the swarm. The results indicate that robot swarms show significant promise in monitoring dynamic environments.
Depth-based Privileged Information for Boosting 3D Human Pose Estimation on RGB
Sep 17, 2024



Despite the recent advances in computer vision research, estimating the 3D human pose from single RGB images remains a challenging task, as multiple 3D poses can correspond to the same 2D projection on the image. In this context, depth data could help to disambiguate the 2D information by providing additional constraints about the distance between objects in the scene and the camera. Unfortunately, the acquisition of accurate depth data is limited to indoor spaces and usually is tied to specific depth technologies and devices, thus limiting generalization capabilities. In this paper, we propose a method able to leverage the benefits of depth information without compromising its broader applicability and adaptability in a predominantly RGB-camera-centric landscape. Our approach consists of a heatmap-based 3D pose estimator that, leveraging the paradigm of Privileged Information, is able to hallucinate depth information from the RGB frames given at inference time. More precisely, depth information is used exclusively during training by enforcing our RGB-based hallucination network to learn similar features to a backbone pre-trained only on depth data. This approach proves to be effective even when dealing with limited and small datasets. Experimental results reveal that the paradigm of Privileged Information significantly enhances the model's performance, enabling efficient extraction of depth information by using only RGB images.
Leveraging swarm capabilities to assist other systems
May 07, 2024Most studies in swarm robotics treat the swarm as an isolated system of interest. We argue that the prevailing view of swarms as self-sufficient, independent systems limits the scope of potential applications for swarm robotics. A robot swarm could act as a support in an heterogeneous system comprising other robots and/or human operators, in particular by quickly providing access to a large amount of data acquired in large unknown environments. Tasks such as target identification & tracking, scouting, or monitoring/surveillance could benefit from this approach.
LAC: Latent Action Composition for Skeleton-based Action Segmentation
Aug 31, 2023Skeleton-based action segmentation requires recognizing composable actions in untrimmed videos. Current approaches decouple this problem by first extracting local visual features from skeleton sequences and then processing them by a temporal model to classify frame-wise actions. However, their performances remain limited as the visual features cannot sufficiently express composable actions. In this context, we propose Latent Action Composition (LAC), a novel self-supervised framework aiming at learning from synthesized composable motions for skeleton-based action segmentation. LAC is composed of a novel generation module towards synthesizing new sequences. Specifically, we design a linear latent space in the generator to represent primitive motion. New composed motions can be synthesized by simply performing arithmetic operations on latent representations of multiple input skeleton sequences. LAC leverages such synthesized sequences, which have large diversity and complexity, for learning visual representations of skeletons in both sequence and frame spaces via contrastive learning. The resulting visual encoder has a high expressive power and can be effectively transferred onto action segmentation tasks by end-to-end fine-tuning without the need for additional temporal models. We conduct a study focusing on transfer-learning and we show that representations learned from pre-trained LAC outperform the state-of-the-art by a large margin on TSU, Charades, PKU-MMD datasets.
Automatic off-line design of robot swarms: exploring the transferability of control software and design methods across different platforms
May 25, 2023



Automatic off-line design is an attractive approach to implementing robot swarms. In this approach, a designer specifies a mission for the swarm, and an optimization process generates suitable control software for the individual robots through computer-based simulations. Most relevant literature has focused on effectively transferring control software from simulation to physical robots. For the first time, we investigate (i) whether control software generated via automatic design is transferable across robot platforms and (ii) whether the design methods that generate such control software are themselves transferable. We experiment with two ground mobile platforms with equivalent capabilities. Our measure of transferability is based on the performance drop observed when control software and/or design methods are ported from one platform to another. Results indicate that while the control software generated via automatic design is transferable in some cases, better performance can be achieved when a transferable method is directly applied to the new platform.
Self-Supervised Video Representation Learning via Latent Time Navigation
May 10, 2023



Self-supervised video representation learning aimed at maximizing similarity between different temporal segments of one video, in order to enforce feature persistence over time. This leads to loss of pertinent information related to temporal relationships, rendering actions such as `enter' and `leave' to be indistinguishable. To mitigate this limitation, we propose Latent Time Navigation (LTN), a time-parameterized contrastive learning strategy that is streamlined to capture fine-grained motions. Specifically, we maximize the representation similarity between different video segments from one video, while maintaining their representations time-aware along a subspace of the latent representation code including an orthogonal basis to represent temporal changes. Our extensive experimental analysis suggests that learning video representations by LTN consistently improves performance of action classification in fine-grained and human-oriented tasks (e.g., on Toyota Smarthome dataset). In addition, we demonstrate that our proposed model, when pre-trained on Kinetics-400, generalizes well onto the unseen real world video benchmark datasets UCF101 and HMDB51, achieving state-of-the-art performance in action recognition.