 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSkill: Segment-Level Skill Assessment in Procedural Videos
Jan 28, 2026Skill assessment in procedural videos is crucial for the objective evaluation of human performance in settings such as manufacturing and procedural daily tasks. Current research on skill assessment has predominantly focused on sports and lacks large-scale datasets for complex procedural activities. Existing studies typically involve only a limited number of actions, focus on either pairwise assessments (e.g., A is better than B) or on binary labels (e.g., good execution vs needs improvement). In response to these shortcomings, we introduce ProSkill, the first benchmark dataset for action-level skill assessment in procedural tasks. ProSkill provides absolute skill assessment annotations, along with pairwise ones. This is enabled by a novel and scalable annotation protocol that allows for the creation of an absolute skill assessment ranking starting from pairwise assessments. This protocol leverages a Swiss Tournament scheme for efficient pairwise comparisons, which are then aggregated into consistent, continuous global scores using an ELO-based rating system. We use our dataset to benchmark the main state-of-the-art skill assessment algorithms, including both ranking-based and pairwise paradigms. The suboptimal results achieved by the current state-of-the-art highlight the challenges and thus the value of ProSkill in the context of skill assessment for procedural videos. All data and code are available at https://fpv-iplab.github.io/ProSkill/
Language-Based Swarm Perception: Decentralized Person Re-Identification via Natural Language Descriptions
Jan 18, 2026We introduce a method for decentralized person re-identification in robot swarms that leverages natural language as the primary representational modality. Unlike traditional approaches that rely on opaque visual embeddings -- high-dimensional feature vectors extracted from images -- the proposed method uses human-readable language to represent observations. Each robot locally detects and describes individuals using a vision-language model (VLM), producing textual descriptions of appearance instead of feature vectors. These descriptions are compared and clustered across the swarm without centralized coordination, allowing robots to collaboratively group observations of the same individual. Each cluster is distilled into a representative description by a language model, providing an interpretable, concise summary of the swarm's collective perception. This approach enables natural-language querying, enhances transparency, and supports explainable swarm behavior. Preliminary experiments demonstrate competitive performance in identity consistency and interpretability compared to embedding-based methods, despite current limitations in text similarity and computational load. Ongoing work explores refined similarity metrics, semantic navigation, and the extension of language-based perception to environmental elements. This work prioritizes decentralized perception and communication, while active navigation remains an open direction for future study.
Mixture of Experts Guided by Gaussian Splatters Matters: A new Approach to Weakly-Supervised Video Anomaly Detection
Aug 08, 2025Video Anomaly Detection (VAD) is a challenging task due to the variability of anomalous events and the limited availability of labeled data. Under the Weakly-Supervised VAD (WSVAD) paradigm, only video-level labels are provided during training, while predictions are made at the frame level. Although state-of-the-art models perform well on simple anomalies (e.g., explosions), they struggle with complex real-world events (e.g., shoplifting). This difficulty stems from two key issues: (1) the inability of current models to address the diversity of anomaly types, as they process all categories with a shared model, overlooking category-specific features; and (2) the weak supervision signal, which lacks precise temporal information, limiting the ability to capture nuanced anomalous patterns blended with normal events. To address these challenges, we propose Gaussian Splatting-guided Mixture of Experts (GS-MoE), a novel framework that employs a set of expert models, each specialized in capturing specific anomaly types. These experts are guided by a temporal Gaussian splatting loss, enabling the model to leverage temporal consistency and enhance weak supervision. The Gaussian splatting approach encourages a more precise and comprehensive representation of anomalies by focusing on temporal segments most likely to contain abnormal events. The predictions from these specialized experts are integrated through a mixture-of-experts mechanism to model complex relationships across diverse anomaly patterns. Our approach achieves state-of-the-art performance, with a 91.58% AUC on the UCF-Crime dataset, and demonstrates superior results on XD-Violence and MSAD datasets. By leveraging category-specific expertise and temporal guidance, GS-MoE sets a new benchmark for VAD under weak supervision.
Looking into the Unknown: Exploring Action Discovery for Segmentation of Known and Unknown Actions
Aug 07, 2025We introduce Action Discovery, a novel setup within Temporal Action Segmentation that addresses the challenge of defining and annotating ambiguous actions and incomplete annotations in partially labeled datasets. In this setup, only a subset of actions - referred to as known actions - is annotated in the training data, while other unknown actions remain unlabeled. This scenario is particularly relevant in domains like neuroscience, where well-defined behaviors (e.g., walking, eating) coexist with subtle or infrequent actions that are often overlooked, as well as in applications where datasets are inherently partially annotated due to ambiguous or missing labels. To address this problem, we propose a two-step approach that leverages the known annotations to guide both the temporal and semantic granularity of unknown action segments. First, we introduce the Granularity-Guided Segmentation Module (GGSM), which identifies temporal intervals for both known and unknown actions by mimicking the granularity of annotated actions. Second, we propose the Unknown Action Segment Assignment (UASA), which identifies semantically meaningful classes within the unknown actions, based on learned embedding similarities. We systematically explore the proposed setting of Action Discovery on three challenging datasets - Breakfast, 50Salads, and Desktop Assembly - demonstrating that our method considerably improves upon existing baselines.
Just Dance with $π$! A Poly-modal Inductor for Weakly-supervised Video Anomaly Detection
May 19, 2025Weakly-supervised methods for video anomaly detection (VAD) are conventionally based merely on RGB spatio-temporal features, which continues to limit their reliability in real-world scenarios. This is due to the fact that RGB-features are not sufficiently distinctive in setting apart categories such as shoplifting from visually similar events. Therefore, towards robust complex real-world VAD, it is essential to augment RGB spatio-temporal features by additional modalities. Motivated by this, we introduce the Poly-modal Induced framework for VAD: "PI-VAD", a novel approach that augments RGB representations by five additional modalities. Specifically, the modalities include sensitivity to fine-grained motion (Pose), three dimensional scene and entity representation (Depth), surrounding objects (Panoptic masks), global motion (optical flow), as well as language cues (VLM). Each modality represents an axis of a polygon, streamlined to add salient cues to RGB. PI-VAD includes two plug-in modules, namely Pseudo-modality Generation module and Cross Modal Induction module, which generate modality-specific prototypical representation and, thereby, induce multi-modal information into RGB cues. These modules operate by performing anomaly-aware auxiliary tasks and necessitate five modality backbones -- only during training. Notably, PI-VAD achieves state-of-the-art accuracy on three prominent VAD datasets encompassing real-world scenarios, without requiring the computational overhead of five modality backbones at inference.
Towards Generalizing Temporal Action Segmentation to Unseen Views
Apr 03, 2025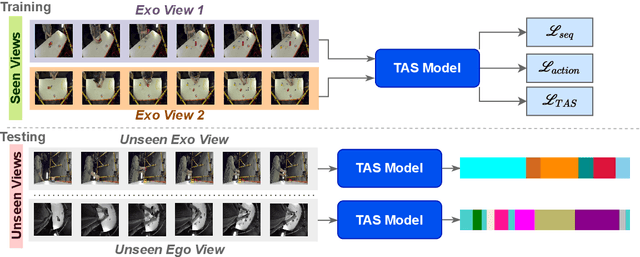
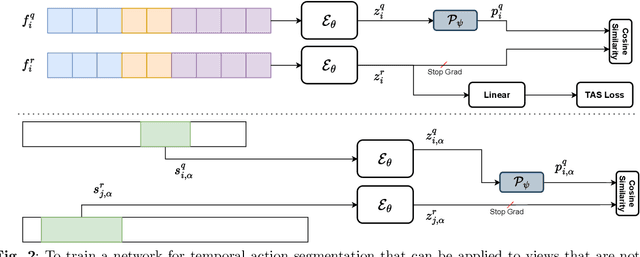
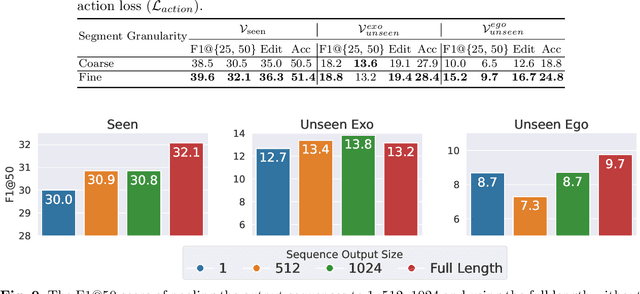

While there has been substantial progress in temporal action segmentation, the challenge to generalize to unseen views remains unaddressed. Hence, we define a protocol for unseen view action segmentation where camera views for evaluating the model are unavailable during training. This includes changing from top-frontal views to a side view or even more challenging from exocentric to egocentric views. Furthermore, we present an approach for temporal action segmentation that tackles this challenge. Our approach leverages a shared representation at both the sequence and segment levels to reduce the impact of view differences during training. We achieve this by introducing a sequence loss and an action loss, which together facilitate consistent video and action representations across different views. The evaluation on the Assembly101, IkeaASM, and EgoExoLearn datasets demonstrate significant improvements, with a 12.8% increase in F1@50 for unseen exocentric views and a substantial 54% improvement for unseen egocentric views.
MANTA: Diffusion Mamba for Efficient and Effective Stochastic Long-Term Dense Anticipation
Jan 15, 2025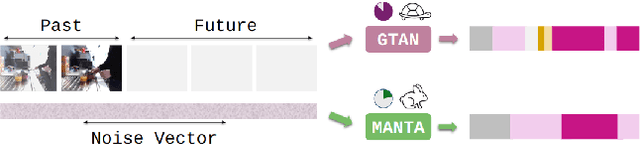

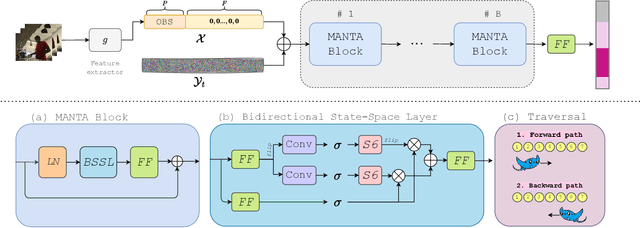

Our work addresses the problem of stochastic long-term dense anticipation. The goal of this task is to predict actions and their durations several minutes into the future based on provided video observations. Anticipation over extended horizons introduces high uncertainty, as a single observation can lead to multiple plausible future outcomes. To address this uncertainty, stochastic models are designed to predict several potential future action sequences. Recent work has further proposed to incorporate uncertainty modelling for observed frames by simultaneously predicting per-frame past and future actions in a unified manner. While such joint modelling of actions is beneficial, it requires long-range temporal capabilities to connect events across distant past and future time points. However, the previous work struggles to achieve such a long-range understanding due to its limited and/or sparse receptive field. To alleviate this issue, we propose a novel MANTA (MAmba for ANTicipation) network. Our model enables effective long-term temporal modelling even for very long sequences while maintaining linear complexity in sequence length. We demonstrate that our approach achieves state-of-the-art results on three datasets - Breakfast, 50Salads, and Assembly101 - while also significantly improving computational and memory efficiency.
Hierarchical Vector Quantization for Unsupervised Action Segmentation
Dec 23, 2024In this work, we address unsupervised temporal action segmentation, which segments a set of long, untrimmed videos into semantically meaningful segments that are consistent across videos. While recent approaches combine representation learning and clustering in a single step for this task, they do not cope with large variations within temporal segments of the same class. To address this limitation, we propose a novel method, termed Hierarchical Vector Quantization (\ours), that consists of two subsequent vector quantization modules. This results in a hierarchical clustering where the additional subclusters cover the variations within a cluster. We demonstrate that our approach captures the distribution of segment lengths much better than the state of the art. To this end, we introduce a new metric based on the Jensen-Shannon Distance (JSD) for unsupervised temporal action segmentation. We evaluate our approach on three public datasets, namely Breakfast, YouTube Instructional and IKEA ASM. Our approach outperforms the state of the art in terms of F1 score, recall and JSD.
Collective perception for tracking people with a robot swarm
Oct 09, 2024
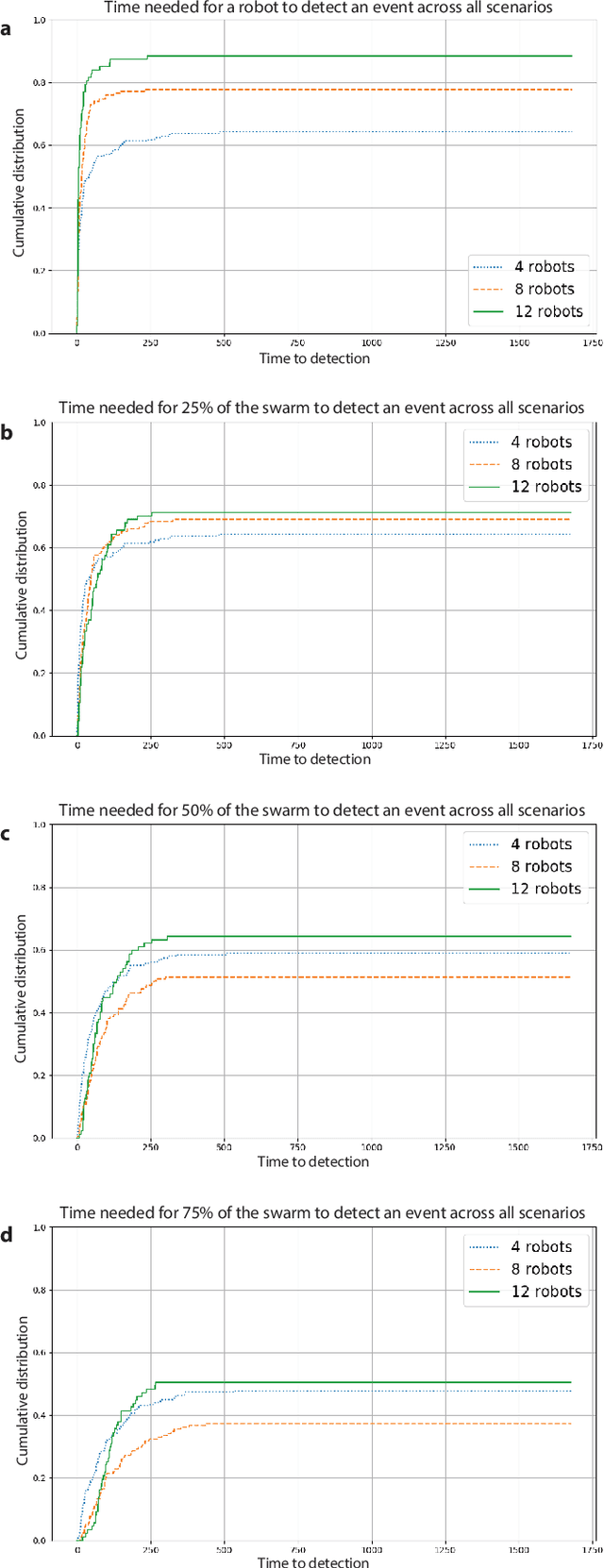
Swarm perception refers to the ability of a robot swarm to utilize the perception capabilities of each individual robot, forming a collective understanding of the environment. Their distributed nature enables robot swarms to continuously monitor dynamic environments by maintaining a constant presence throughout the space.In this study, we present a preliminary experiment on the collective tracking of people using a robot swarm. The experiment was conducted in simulation across four different office environments, with swarms of varying sizes. The robots were provided with images sampled from a dataset of real-world office environment pictures.We measured the time distribution required for a robot to detect a person changing location and to propagate this information to increasing fractions of the swarm. The results indicate that robot swarms show significant promise in monitoring dynamic environments.
Depth-based Privileged Information for Boosting 3D Human Pose Estimation on RGB
Sep 17, 2024



Despite the recent advances in computer vision research, estimating the 3D human pose from single RGB images remains a challenging task, as multiple 3D poses can correspond to the same 2D projection on the image. In this context, depth data could help to disambiguate the 2D information by providing additional constraints about the distance between objects in the scene and the camera. Unfortunately, the acquisition of accurate depth data is limited to indoor spaces and usually is tied to specific depth technologies and devices, thus limiting generalization capabilities. In this paper, we propose a method able to leverage the benefits of depth information without compromising its broader applicability and adaptability in a predominantly RGB-camera-centric landscape. Our approach consists of a heatmap-based 3D pose estimator that, leveraging the paradigm of Privileged Information, is able to hallucinate depth information from the RGB frames given at inference time. More precisely, depth information is used exclusively during training by enforcing our RGB-based hallucination network to learn similar features to a backbone pre-trained only on depth data. This approach proves to be effective even when dealing with limited and small datasets. Experimental results reveal that the paradigm of Privileged Information significantly enhances the model's performance, enabling efficient extraction of depth information by using only RGB images.