 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizing Temporal Action Segmentation to Unseen Views
Paper and Code
Apr 03, 2025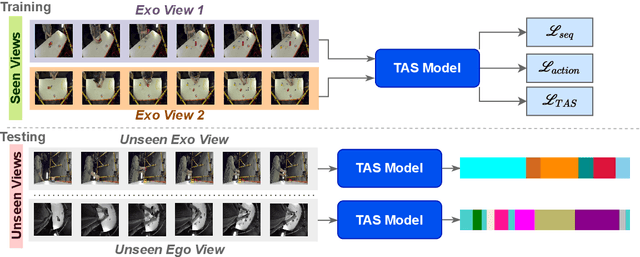
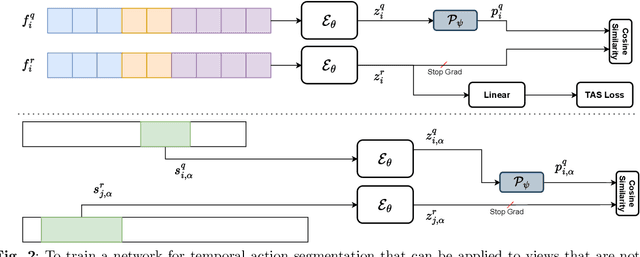
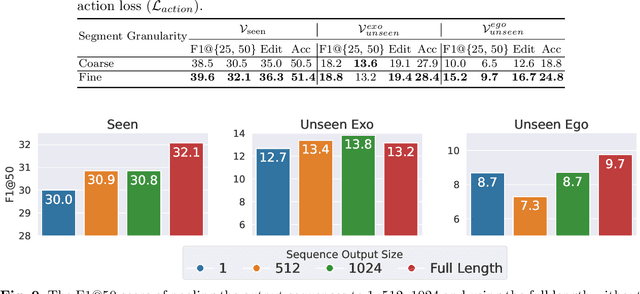

While there has been substantial progress in temporal action segmentation, the challenge to generalize to unseen views remains unaddressed. Hence, we define a protocol for unseen view action segmentation where camera views for evaluating the model are unavailable during training. This includes changing from top-frontal views to a side view or even more challenging from exocentric to egocentric views. Furthermore, we present an approach for temporal action segmentation that tackles this challenge. Our approach leverages a shared representation at both the sequence and segment levels to reduce the impact of view differences during training. We achieve this by introducing a sequence loss and an action loss, which together facilitate consistent video and action representations across different views. The evaluation on the Assembly101, IkeaASM, and EgoExoLearn datasets demonstrate significant improvements, with a 12.8% increase in F1@50 for unseen exocentric views and a substantial 54% improvement for unseen egocentric views.