 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking into the Unknown: Exploring Action Discovery for Segmentation of Known and Unknown Actions
Aug 07, 2025We introduce Action Discovery, a novel setup within Temporal Action Segmentation that addresses the challenge of defining and annotating ambiguous actions and incomplete annotations in partially labeled datasets. In this setup, only a subset of actions - referred to as known actions - is annotated in the training data, while other unknown actions remain unlabeled. This scenario is particularly relevant in domains like neuroscience, where well-defined behaviors (e.g., walking, eating) coexist with subtle or infrequent actions that are often overlooked, as well as in applications where datasets are inherently partially annotated due to ambiguous or missing labels. To address this problem, we propose a two-step approach that leverages the known annotations to guide both the temporal and semantic granularity of unknown action segments. First, we introduce the Granularity-Guided Segmentation Module (GGSM), which identifies temporal intervals for both known and unknown actions by mimicking the granularity of annotated actions. Second, we propose the Unknown Action Segment Assignment (UASA), which identifies semantically meaningful classes within the unknown actions, based on learned embedding similarities. We systematically explore the proposed setting of Action Discovery on three challenging datasets - Breakfast, 50Salads, and Desktop Assembly - demonstrating that our method considerably improves upon existing baselines.
Towards Generalizing Temporal Action Segmentation to Unseen Views
Apr 03, 2025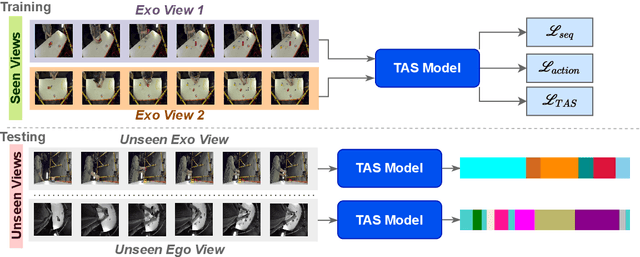
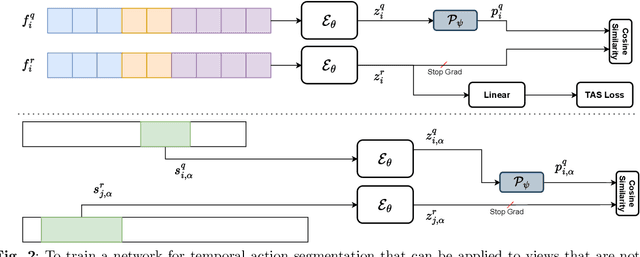
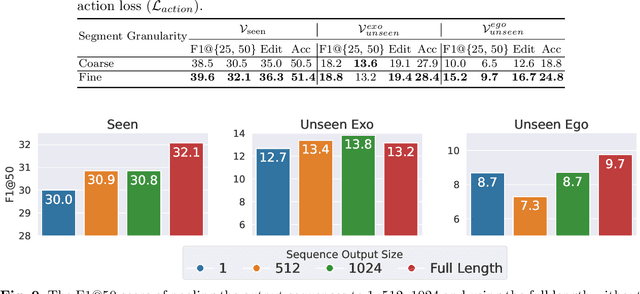

While there has been substantial progress in temporal action segmentation, the challenge to generalize to unseen views remains unaddressed. Hence, we define a protocol for unseen view action segmentation where camera views for evaluating the model are unavailable during training. This includes changing from top-frontal views to a side view or even more challenging from exocentric to egocentric views. Furthermore, we present an approach for temporal action segmentation that tackles this challenge. Our approach leverages a shared representation at both the sequence and segment levels to reduce the impact of view differences during training. We achieve this by introducing a sequence loss and an action loss, which together facilitate consistent video and action representations across different views. The evaluation on the Assembly101, IkeaASM, and EgoExoLearn datasets demonstrate significant improvements, with a 12.8% increase in F1@50 for unseen exocentric views and a substantial 54% improvement for unseen egocentric views.
MANTA: Diffusion Mamba for Efficient and Effective Stochastic Long-Term Dense Anticipation
Jan 15, 2025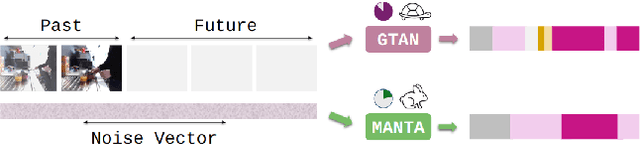

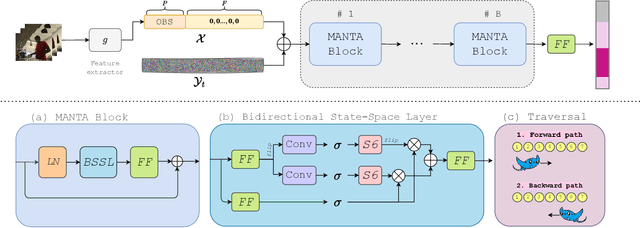

Our work addresses the problem of stochastic long-term dense anticipation. The goal of this task is to predict actions and their durations several minutes into the future based on provided video observations. Anticipation over extended horizons introduces high uncertainty, as a single observation can lead to multiple plausible future outcomes. To address this uncertainty, stochastic models are designed to predict several potential future action sequences. Recent work has further proposed to incorporate uncertainty modelling for observed frames by simultaneously predicting per-frame past and future actions in a unified manner. While such joint modelling of actions is beneficial, it requires long-range temporal capabilities to connect events across distant past and future time points. However, the previous work struggles to achieve such a long-range understanding due to its limited and/or sparse receptive field. To alleviate this issue, we propose a novel MANTA (MAmba for ANTicipation) network. Our model enables effective long-term temporal modelling even for very long sequences while maintaining linear complexity in sequence length. We demonstrate that our approach achieves state-of-the-art results on three datasets - Breakfast, 50Salads, and Assembly101 - while also significantly improving computational and memory efficiency.
Hierarchical Vector Quantization for Unsupervised Action Segmentation
Dec 23, 2024In this work, we address unsupervised temporal action segmentation, which segments a set of long, untrimmed videos into semantically meaningful segments that are consistent across videos. While recent approaches combine representation learning and clustering in a single step for this task, they do not cope with large variations within temporal segments of the same class. To address this limitation, we propose a novel method, termed Hierarchical Vector Quantization (\ours), that consists of two subsequent vector quantization modules. This results in a hierarchical clustering where the additional subclusters cover the variations within a cluster. We demonstrate that our approach captures the distribution of segment lengths much better than the state of the art. To this end, we introduce a new metric based on the Jensen-Shannon Distance (JSD) for unsupervised temporal action segmentation. We evaluate our approach on three public datasets, namely Breakfast, YouTube Instructional and IKEA ASM. Our approach outperforms the state of the art in terms of F1 score, recall and JSD.
Gated Temporal Diffusion for Stochastic Long-Term Dense Anticipation
Jul 16, 2024



Long-term action anticipation has become an important task for many applications such as autonomous driving and human-robot interaction. Unlike short-term anticipation, predicting more actions into the future imposes a real challenge with the increasing uncertainty in longer horizons. While there has been a significant progress in predicting more actions into the future, most of the proposed methods address the task in a deterministic setup and ignore the underlying uncertainty. In this paper, we propose a novel Gated Temporal Diffusion (GTD) network that models the uncertainty of both the observation and the future predictions. As generator, we introduce a Gated Anticipation Network (GTAN) to model both observed and unobserved frames of a video in a mutual representation. On the one hand, using a mutual representation for past and future allows us to jointly model ambiguities in the observation and future, while on the other hand GTAN can by design treat the observed and unobserved parts differently and steer the information flow between them. Our model achieves state-of-the-art results on the Breakfast, Assembly101 and 50Salads datasets in both stochastic and deterministic settings. Code: https://github.com/olga-zats/GTDA .
FastSurfer-HypVINN: Automated sub-segmentation of the hypothalamus and adjacent structures on high-resolutional brain MRI
Aug 24, 2023The hypothalamus plays a crucial role in the regulation of a broad range of physiological, behavioural, and cognitive functions. However, despite its importance, only a few small-scale neuroimaging studies have investigated its substructures, likely due to the lack of fully automated segmentation tools to address scalability and reproducibility issues of manual segmentation. While the only previous attempt to automatically sub-segment the hypothalamus with a neural network showed promise for 1.0 mm isotropic T1-weighted (T1w) MRI, there is a need for an automated tool to sub-segment also high-resolutional (HiRes) MR scans, as they are becoming widely available, and include structural detail also from multi-modal MRI. We, therefore, introduce a novel, fast, and fully automated deep learning method named HypVINN for sub-segmentation of the hypothalamus and adjacent structures on 0.8 mm isotropic T1w and T2w brain MR images that is robust to missing modalities. We extensively validate our model with respect to segmentation accuracy, generalizability, in-session test-retest reliability, and sensitivity to replicate hypothalamic volume effects (e.g. sex-differences). The proposed method exhibits high segmentation performance both for standalone T1w images as well as for T1w/T2w image pairs. Even with the additional capability to accept flexible inputs, our model matches or exceeds the performance of state-of-the-art methods with fixed inputs. We, further, demonstrate the generalizability of our method in experiments with 1.0 mm MR scans from both the Rhineland Study and the UK Biobank. Finally, HypVINN can perform the segmentation in less than a minute (GPU) and will be available in the open source FastSurfer neuroimaging software suite, offering a validated, efficient, and scalable solution for evaluating imaging-derived phenotypes of the hypothalamus.
How Much Temporal Long-Term Context is Needed for Action Segmentation?
Aug 22, 2023Modeling long-term context in videos is crucial for many fine-grained tasks including temporal action segmentation. An interesting question that is still open is how much long-term temporal context is needed for optimal performance. While transformers can model the long-term context of a video, this becomes computationally prohibitive for long videos. Recent works on temporal action segmentation thus combine temporal convolutional networks with self-attentions that are computed only for a local temporal window. While these approaches show good results, their performance is limited by their inability to capture the full context of a video. In this work, we try to answer how much long-term temporal context is required for temporal action segmentation by introducing a transformer-based model that leverages sparse attention to capture the full context of a video. We compare our model with the current state of the art on three datasets for temporal action segmentation, namely 50Salads, Breakfast, and Assembly101. Our experiments show that modeling the full context of a video is necessary to obtain the best performance for temporal action segmentation.
Robust Action Segmentation from Timestamp Supervision
Oct 12, 2022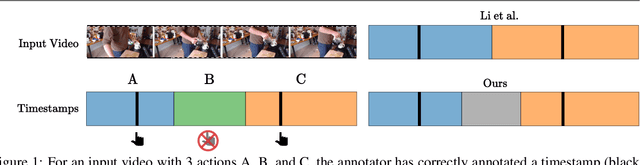
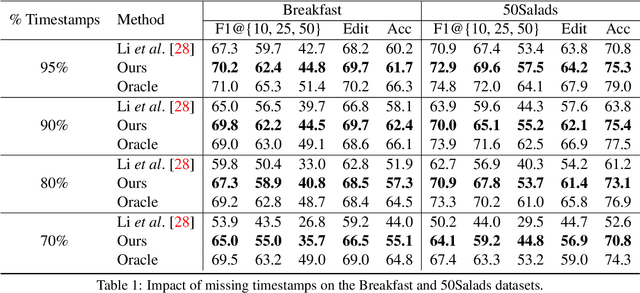
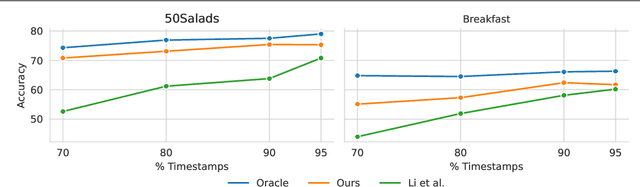
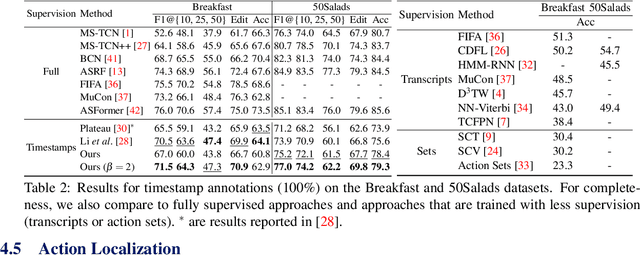
Action segmentation is the task of predicting an action label for each frame of an untrimmed video. As obtaining annotations to train an approach for action segmentation in a fully supervised way is expensive, various approaches have been proposed to train action segmentation models using different forms of weak supervision, e.g., action transcripts, action sets, or more recently timestamps. Timestamp supervision is a promising type of weak supervision as obtaining one timestamp per action is less expensive than annotating all frames, but it provides more information than other forms of weak supervision. However, previous works assume that every action instance is annotated with a timestamp, which is a restrictive assumption since it assumes that annotators do not miss any action. In this work, we relax this restrictive assumption and take missing annotations for some action instances into account. We show that our approach is more robust to missing annotations compared to other approaches and various baselines.
Taylor Swift: Taylor Driven Temporal Modeling for Swift Future Frame Prediction
Oct 27, 2021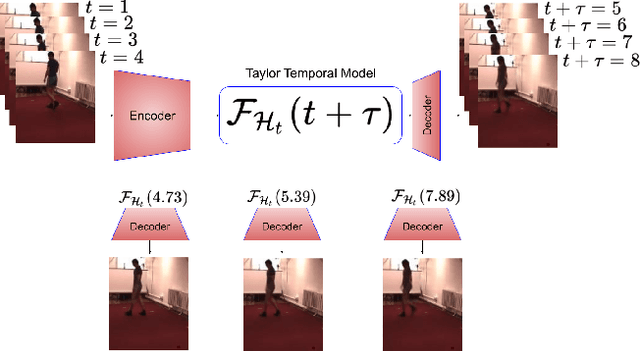
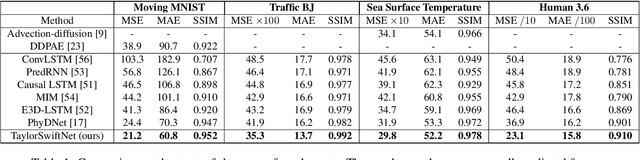
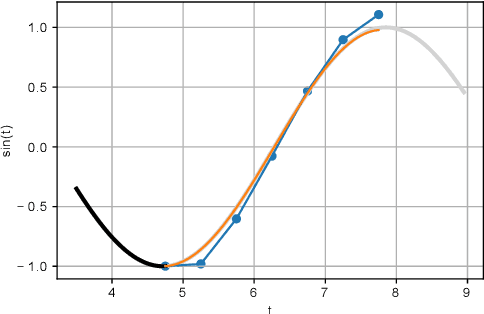

While recurrent neural networks (RNNs) demonstrate outstanding capabilities in future video frame prediction, they model dynamics in a discrete time space and sequentially go through all frames until the desired future temporal step is reached. RNNs are therefore prone to accumulate the error as the number of future frames increases. In contrast, partial differential equations (PDEs) model physical phenomena like dynamics in continuous time space, however, current PDE-based approaches discretize the PDEs using e.g., the forward Euler method. In this work, we therefore propose to approximate the motion in a video by a continuous function using the Taylor series. To this end, we introduce TayloSwiftNet, a novel convolutional neural network that learns to estimate the higher order terms of the Taylor series for a given input video. TayloSwiftNet can swiftly predict any desired future frame in just one forward pass and change the temporal resolution on-the-fly. The experimental results on various datasets demonstrate the superiority of our model.